







1.论文链接
2.论文主要为了解决什么问题?
主要为了解决对于一个已经train好的神经网络迁移的时候需要改动很多结构的问题
3.模型流程
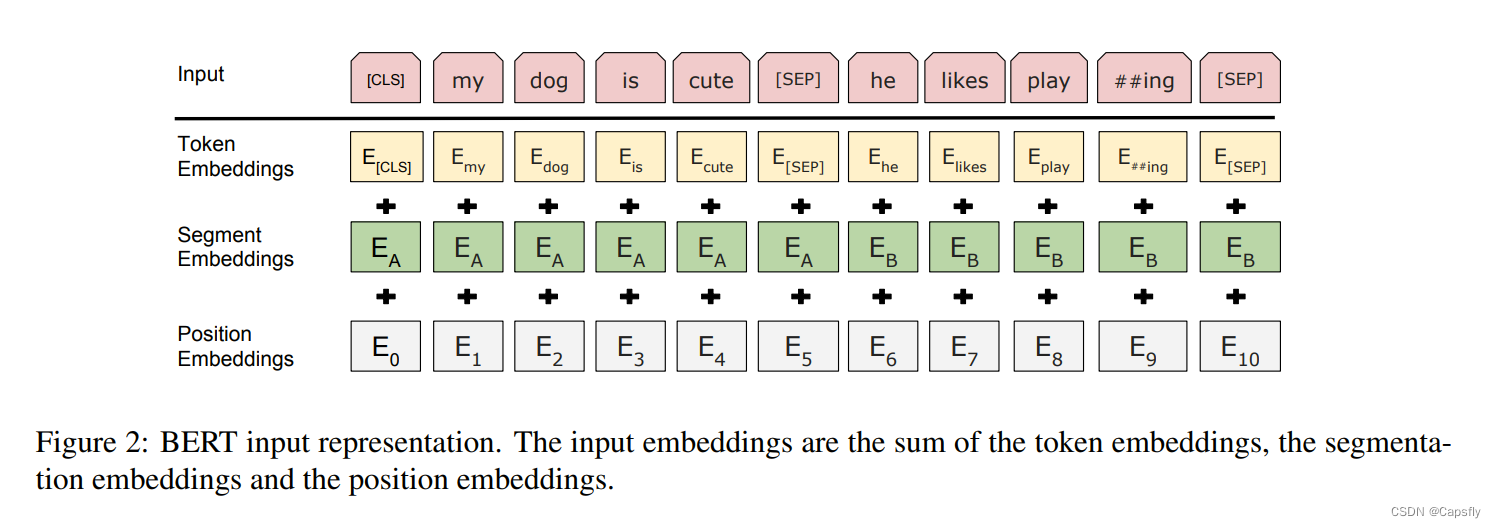
输入的时候使用上面这个图的流程,首先对位置进行编码,是非常简单的直接用index进行嵌入就可以了(0,1,2,3…),segment embeddings主要是为了去掉不常用的词,只用词根来表示。token embeddings是对word进行编码,然后将这三个embedding加起来。

论文在微调的时候,需要看到context,作者提出来了一个想法:就是每次80%的时间需要猜测这个单词,10%的时间需要代替这个单词,10%的时间保持这个单词不变。这样就能让这个网络既有预测能力,又看到了这个单词。
4.论文创新点
论文解除了GPT的单向限制(只能从左边看),同时他引入了既能看到单词的方法,又能进行猜测
5.本论文收到了哪些论文启发?
论文基于GPT和ELMO















 843
843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









