







一、milvus简介
Milvus是一个开源的向量相似度搜索引擎,主要用于大规模向量数据的存储和查询。它支持多种向量类型,包括稠密向量、稀疏向量、二进制向量等,并提供了多种相似度度量方法,如欧氏距离、余弦相似度、Jaccard相似度等。Milvus支持分布式部署,可以在多台服务器上搭建分布式搜索集群,支持高并发查询和批量查询。Milvus通过提供简单易用的API,可以轻松地与各种应用程序集成,如图像搜索、推荐系统、自然语言处理等领域。此博文以centos环境下安装milvus为例进行介绍,博文实验环境如下:
- 操作系统:centos7.9
- docker版本:23.0.1
- milvus版本:2.2.9
二、安装环境要求
如下是以单机节点部署方式的软硬件安装要求。
1、硬件要求
| 序号 | 硬件类型 | 最低配置要求 | 推荐配置 | 备注 |
|---|---|---|---|---|
| 1 | CPU | intel二代以上CPU | 4核以上CPU | 目前不支持AMD CPU类型 |
| 2 | CPU指令集 | SSE4.2、AVX、AVX2、AVX-512 | SSE4.2、AVX、AVX2、AVX-512 | 确保CPU至少支持一个列出的SIMD扩展 |
| 3 | 内存 | 8G | 16G | |
| 4 | 硬盘驱动 | SATA 3.0 SSD或者更高 | NVMe SSD或者更高 |
2、软件要求
对于单机部署来说主要满足满足docker和docker compose组件版本要求就可以,另外几个相关软件是在通过docker compose安装milvus时自动安装的。
| 序号 | 软件 | 要求 | 备注 |
|---|---|---|---|
| 1 | Linux系统 | Docker 19.03以上版本,Docker Compose 1.25.1以上版本 | |
| 2 | etcd | 3.5.0 | 对集群性能至关重要,与磁盘性能相关 |
| 3 | MinIO | RELEASE.2023-03-20T20-16-18Z | |
| 4 | Pulsar | 2.8.2 |
三、安装步骤
1、安装docker
docker的安装见博文Linux之docker安装,这里不再赘述。
2、安装fio命令
[root@yws55 home]# yum install -y fio
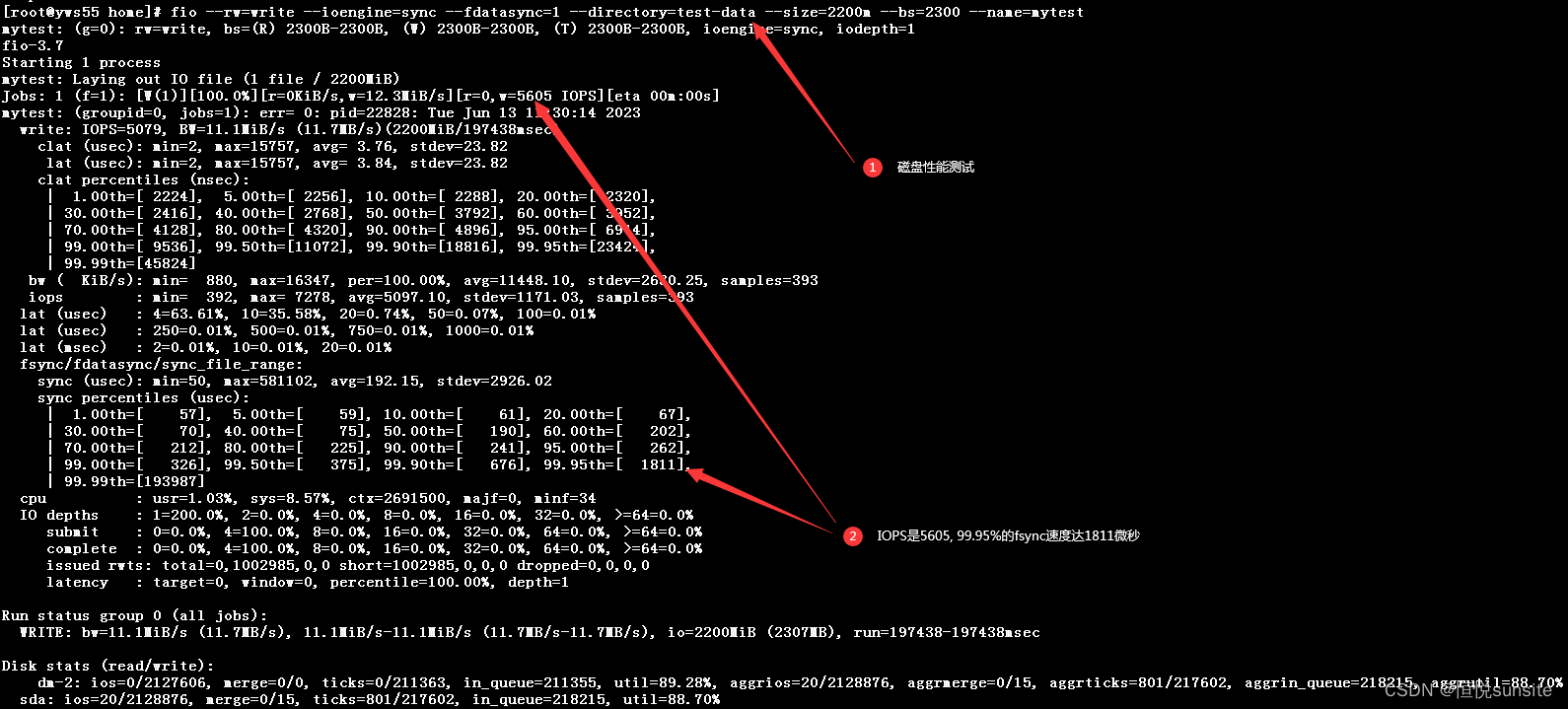
3、磁盘性能测试
理想情况下,磁盘的IOPS应超过500,而fsync延迟的99%以上应低于10ms。
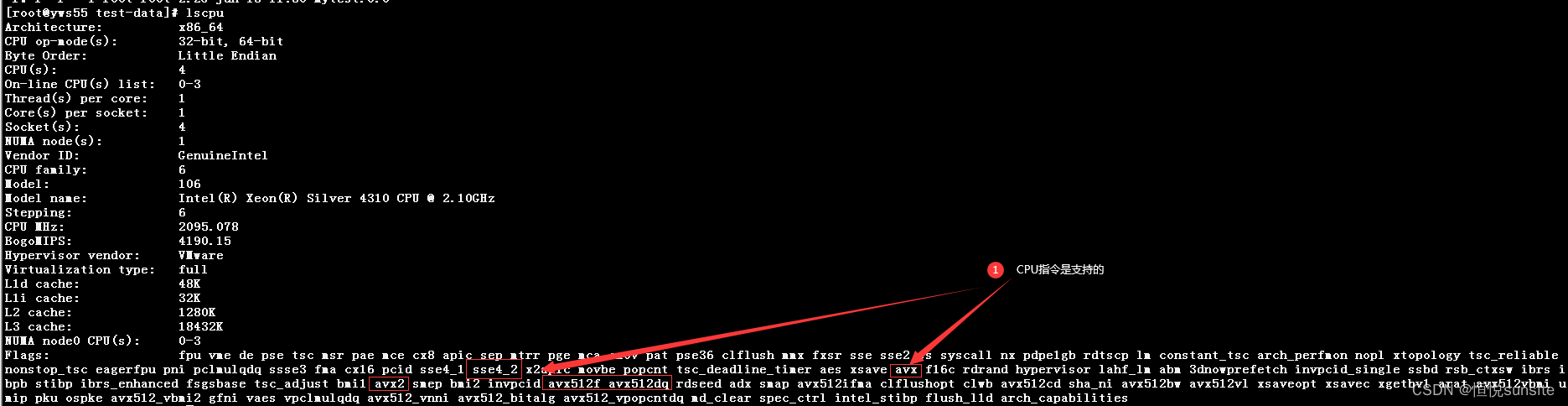
4、检查CPU支持的指令集
我们使用lscpu命令可以查看CPU支持的指令集,Flags的参数值就是该服务器支持的CPU指令集。
5、检查docker版本
根据milvus安装要求,docker版本要求是19.03以上版本,我们这里安装的docker版本为23.0.1,满足要求。
[root@yws55 test-data]# docker -v
Docker version 23.0.1, build a5ee5b1
6、安装docker compose组件
根据milvus安装要求,docker compose版本要求是1.25.1以上,我们这里安装的版本是1.29.2,满足要求。
[root@yws55 home]# yum -y install python3-pip
[root@yws55 home]# pip3 install --upgrade pip
[root@yws55 home]# pip install docker-compose
[root@yws55 home]# docker-compose version
…
docker-compose version 1.29.2, build unknown
…
7、下载YAML文件
在/home目录下创建一个docker目录,当然这个可以自定义,这个目录将用于存储我们的milvus容器的volumes数据。
[root@yws55 home]# mkdir docker
[root@yws55 home]# cd docker/
[root@yws55 docker]# wget https://github.com/milvus-io/milvus/releases/download/v2.2.9/milvus-standalone-docker-compose.yml -O docker-compose.yml
8、安装milvus容器
在下载存储docker-compose.yml文件的目录下执行docker-compose up -d 命令开始安装milvus容器。
[root@yws55 docker]# docker-compose up -d
…
Creating milvus-minio … done
Creating milvus-etcd … done
Creating milvus-standalone … done
[root@yws55 docker]# ll
total 4
-rw-r–r-- 1 root root 1356 Jun 5 10:35 docker-compose.yml
drwxr-xr-x 5 root root 45 Jun 13 14:52 volumes
9、查看milvus容器运行状态
使用docker-compose安装完成milvus后自动启动了,可以使用命令docker ps或者docker-compose ps命令查看容器运行状态。看到milvus-etcd 、milvus-minio 、milvus-standalone三个容器说明安装成功。

10、milvus数据库连接测试
使用浏览器访问连接地址http://ip:9091/api/v1/health,返回{“status”:“ok”}说明milvus数据库服务器运行正常。

11、milvus数据库服务管理
- 停止milvus容器
[root@yws55 docker]# docker-compose stop
- 启动milvus容器
[root@yws55 docker]# docker-compose start
- 删除milvus容器
使用docker-compose down命令会停止milvus容器并删除,然后我们可以rm -rf volumes删除milvus数据。
[root@yws55 docker]# docker-compose down
- 重启milvus容器
[root@yws55 docker]# docker-compose restart
- 查看milvus容器日志
[root@yws55 docker]# docker-compose logs
12、更多milvus知识
更多milvus知识见官网。


















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











