







目录
3.1Proposal Separation Sampling
3.3Geometric and Context Encoding
4.2Experiments onHuman Part Segmentation
4.3Experiments on Dense Pose Estimation
Abstact
实例级人体解析在生活场景中是很常见的,也有许多表现形式,比如人体部件分割、稠密姿态估计、人-物交互等。模型需要判别不同人实例,学习丰富的特征来表示每个实例的细节。在这篇文章中,我们提出一个端到端的pipeline来解决实例级人体解析,叫做parsing r-cnn。它通过综合考虑基于区域的方法特性和人体表观,表示实例细节,同时处理一组人体实例。
Introduction
因为深度学习的发展,许多现有的方法都采用一个两阶段的Pipeline,1.MaskRCNN(检测人)2.并行地预测一个class-aware mask。这些方法已经很成功,但是在实例人体解析还存在问题:1.mask分支用来预测class-agnostic实例mask,但是实例级人体解析需要更多细节的特征。2、人体解析需要人体部件或稠密点间的几何和语义信息,现有方法也都没有体现这一点。所以提出简洁有效的Parsing R_CNN
研究从以下四个方面探索实例人体解析的问题:
1.为了增强特征语义信息,保持特征分辨率,使用可分离采样。
人体通常在图像中占据比较大的比例。因此ROIPool通常在粗糙分辨率特征图上执行。但是这会丢失许多实例细节信息。在这个工作中在特征金字塔中采用可分离采样,最后细化阶段使用roipool
2.为了得到更仔细的信息,我们增大了roi分辨率。
因为人体解析任务通常在12人或者12类中判别。它需要增大特征图分辨率。
3。提出几何和上下文编码方法,来增大感受野,捕捉不同部件间的关系。
它是一个由两个部分组成的轻量组。第一个部件用来得到多个Level感受野和上下文信息;第二个部件是用来学习几何关联。
3.Parsing R_CNN
3.1Proposal Separation Sampling
在FPN和mask R-cnn里,分配策略是把ROI根据不同尺度分配到对应的特征金字塔。通常,大的roi被分配到粗糙分辨率的特征图。但是,我们发现这种策略在实例人体解析中不是最优的。因为小实例不能被准确标注,人体实例通常占据比较大的部分。如图3所示,在COCO数据集中少于20%的实例占据大于图像10%,而CIHP,MHP分别是74%、86%、。在这种比例下,根据FPN提出的分配策略,大部分实例别分到粗糙分辨率的特征图。实例级人体解析通常需要人体一些细节信息,但是粗糙分辨率的特征图不能提供。
所以提出pps,建议分离采样,提取细节特征,也保留了多尺度特征表达。bbox分支依然采用FPN的尺度分配策略(p2-p5),但是解析分支的RoIPool/RoIAlign只在最精细的特征图(P2)上进行。金字塔特征表示有利于目标检测,同时通过从最精细特征图上提取特征,保留了人体细节。
3.2Enlarging RoI Resolution
之前基于区域的方法,为了充分利用预训练的参数,ROIPOOL把一个roi转换到固定大小的特征图7*7或者14*14。但是大多数人体实例在特征图中占据比较大的比例,太小的ROI会丢失许多细节。比如,一个160*64的人体,在P2上是40*16,缩放到14*14会减小预测精度。在木匾检测和实例分割任务重,可能不需要准确预测实例细节 ,但是人体实例级解析需要。
所以提出最简单直直观的方法,增大ROi分辨率err.在解析分支使用32*32的ROI,这增大了计算量,但是显著提高了准确性。为了解决err产生的训练时间和内存负载问题,我们从检测任务中分离出实例级level人体解析的batch_size,固定于一个值32,发现这样增加了训练速度,没有导致准确度下降。
3.3Geometric and Context Encoding
在之前的工作中,每个分支的设计非常简洁。一个FCN被用到池化后的特征图上,来预测pixel-wisemask。然而用一个FCN有3个缺点:1.不同人的部件尺度变化大,这就要求特征图捕捉多尺度信息,2.人体部件是几何相关的,需要一个非局部表示。3.32*32的roi需要一个 大的感受野,堆叠4个或8个3*3的卷积层不够。
ASPP是一个语义分割中有效的模块,用并行的多个不同大小的空洞卷积捕捉尺度信息。Non-local操作能够捕捉大范围的依赖。
我们组合了ASPP和non-local的优点,提出几何和上下文编码模块GCE,代替解析分支的FCN。图5展示了GCE可以编码每个实例的几何和上下文信息。在GCE模块中:
ASPP由一个1*1的卷积和3个3*3不同rate的空洞卷积组成。image-level特征由global average pooling生成,然后1*1卷积,双线性上采样到32*32.
Non-local采用embedded Gaussian ,一个 batch_normal加到最后的卷积层。
3.4Parsing Branch Decoupling
人们在设计神经网络时,通常会根据不同层学习的特征的特点,把网络划分为多个部分。比如,高层对应整个目标,其他神经单元可能会被局部纹理激活。基于区域的方法并行处理每个ROI,所以每个分支的任务可以被理解为相互独立的网络。然而,现有的方法没有吧这些分支decople到不同的部分。
在这篇文章,把解析分支分为三个部分。1、语义空间转换,用来把特征转换到对应的任务。;2.GCE语义和上下文编码3.转换语义特征到特定任务,有人用来增强网络能力。before gce,gce,after gce。
对实例级人体解析任务来说,不是简单地增加每个模块的计算复杂性就提高准确性了。因此,有必要decouple解析分支,分析每个部分的速度/精度 平衡。
4.Experiments
4.1Implementation Details
我们在一个8块Titan X的服务器上基于Detectron实现了Parsing R_CNN。我们采用了FPN和RoIAlign,端到端训练。每个GPU上的mini-batch包含2个图片,每个图片上512个ROI。训练用的图像在[512,864]尺度之间随机,测试用的是800像素的图像。
CIHP数据集,我们在训练集上训练45k次,学习率是0.02,在30k,40k下降10倍。
MHPv2.0数据集,训练次数是CIHP的一般,学习率变化对对应变化。
DensePose-COCO,训练130K次,学习率是0.002,在100k,120k下降10倍
其他细节和Mask R-CNN一样
4.2Experiments onHuman Part Segmentation
Metrics and Baseline。我们从两个方面评估人体部件解析
1从语义分割方法,和[22]一样生成多人mask,用mIOU评估行呢
2从实例级上,我们用APp,用一个人体实例内不同语义部件的部件级iou决定一个实例是否为true posistive。用APp50,APpvol。前者有一个IOU阈值为0.5,后者是iou阈值从0.1到0.9变化APp的均值。还用了PCP(percentage of Correctly parsed semantic parts)
为了公平的比较,我们的baseline采用ResNet-50-FPN作为backbone。解析分支由8个堆叠的3*3 512通道的卷积层,1个反卷积,2*双线性上采样。和【15】一样,RoiAlign后的特征图分辨率是14*14,所以输出分辨率是56*56。训练时用,每个像素的softmax作为多项式交叉熵Loss
在CIHP上的消融实验。
比较了提出的方法,和增加迭代次数,和COCO上预训练。
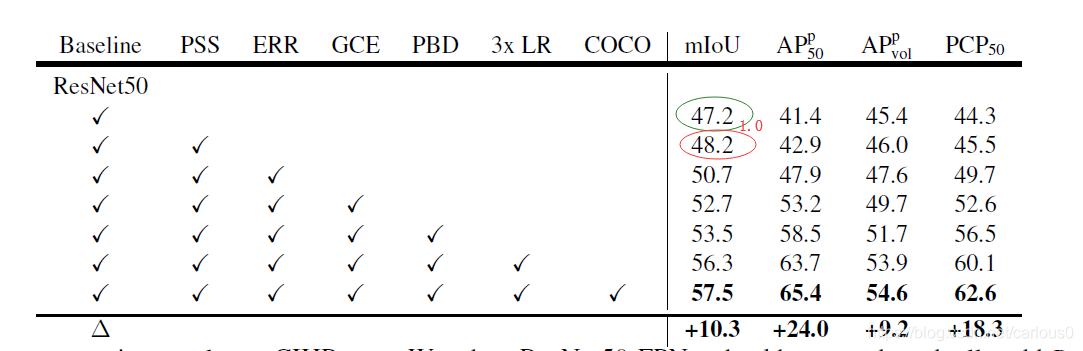
1)Proposals Separation Sampling(PSS)。
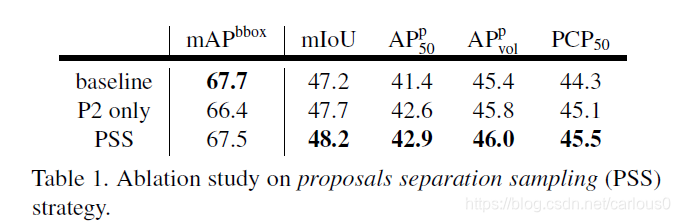
用PSS,mIoU提高了1.0比baseline。也和只用P2特征图比较了,mIoU减少了0.5,bbox mAP也更坏了。如表1所示,APp指标在PSS下有一定程度的提高,说明提出的方法是有效的。
2)Enlarging RoI Resolution(ERR)
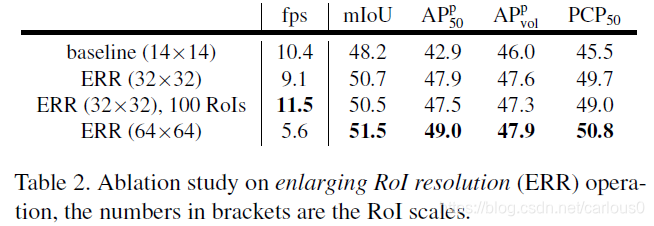
如表2所示我们用32*32、64*64的ROI,发现比14*14提升了性能。ERR(32*32)比baseline (14*14)mIoU提升了2.8。APp指标比baseline(14*14)分别提高了5.0,1.7,4.4。而且解析分支的ROI是并行的,所以速度之比baseline(14*14)减少了12%((10.4-9.1)/10.4)。而且我们可以通过减少ROI的数量来增加速度,如果我们使用100个ROI速度提升率,精度基本没有下降。相对于32*32,64*64的ROI可以继续提升精度,但是考虑到速度精度均衡,我们用32*32的更有效。
3)Geometric and Context Encoding(GCE)
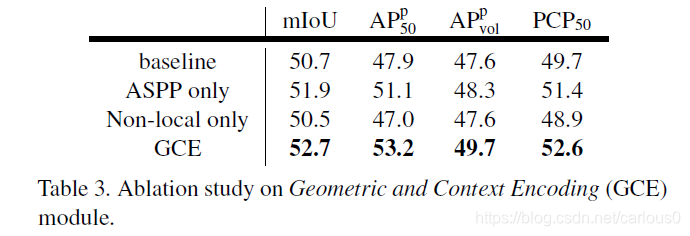
用GCE比8个3*3 521个通道卷积层堆叠,miou提升2.0,更轻量化。Non-Local的有无,ASPP可以提高1.2mIou。但是没有ASPP,non-local导致性能下降。
4)Parsing Branch Decoupling
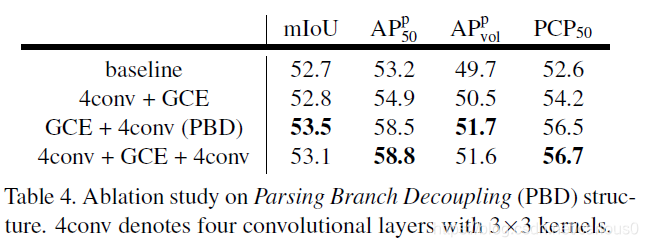
把解析分支分为3个部分。如表4所示,before GCE是不必需的,我们推测是GCE模块本身可以进行语义空间转换。另一方面,after GCE可以显著提高。考虑到速度和精度均衡,我们采用GCE+4个3*3 512个通道(PBD)作为解析分支.
5)Incresing iterations and COCO pretraining
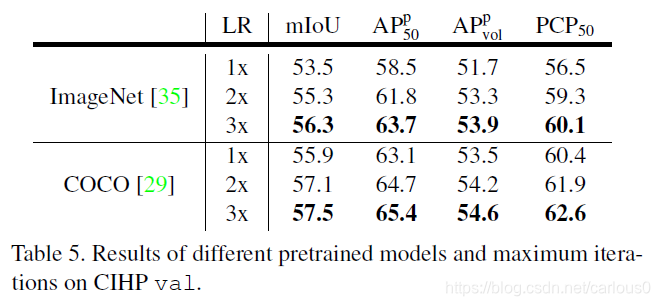
增加迭代次数是提高性能的常见方法。如表5所示,我们在CIHP上2倍和3倍的迭代,提升是很明显的。
进一步,我们比较了在COCO上预训练。
这两种的组合也是显著提升。
如表6所示,有了所有这些提出的方法,我们的Parsing R-cnn比baseline提升更多
Component Ablation Studies on MHP v2.0
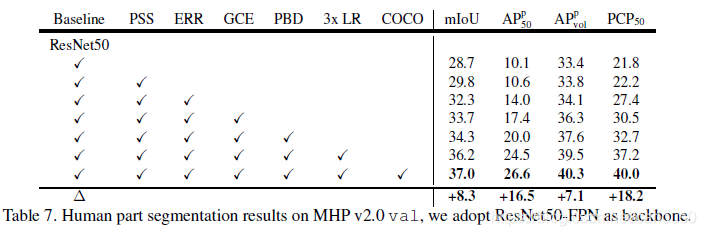
也在MHP上比较了,因为MHP有59个类别,一些是小尺度的,所以baseline就比CIHP低。Parsing R_CNN也提高了。
Comparisons with State-of-the-art Methods
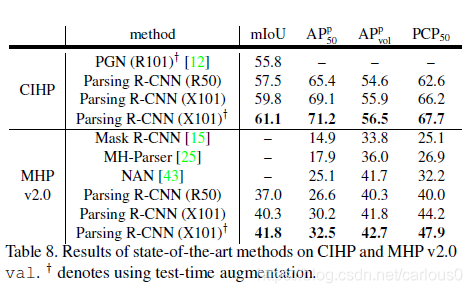
对于CIHP数据集,Parsing R-CNN用ResNet50-FPN比PGN(ResNet101)好。值得一提的是,PGN采用多尺度输入,左右翻转图像来提升性能,而Parsing R-CNN没有test-time augmentation.Parsing R_cnn用ResNeXt-101-32x8d-FPN作为backbone可以达到59.8%mIOU。在此上再进行多尺度、翻转,可以达到61.1%mIoU。
对于MHPv2.0数据集,我们也进行了这些比较,也和其他现有方法比较了。在AP上提高了,不幸的是,其他方法没有给出mIoU
4.3Experiments on Dense Pose Estimation
Metrics and Baseline:和[14]一样,采用点相似阈值从0.5-0.95的平均精度(AP)。基本模型和人体部件解析的一样,我们用稠密人体估计Loss替换softmaxloss
Component Ablation Studies on DensePose-COCO.消融实验。
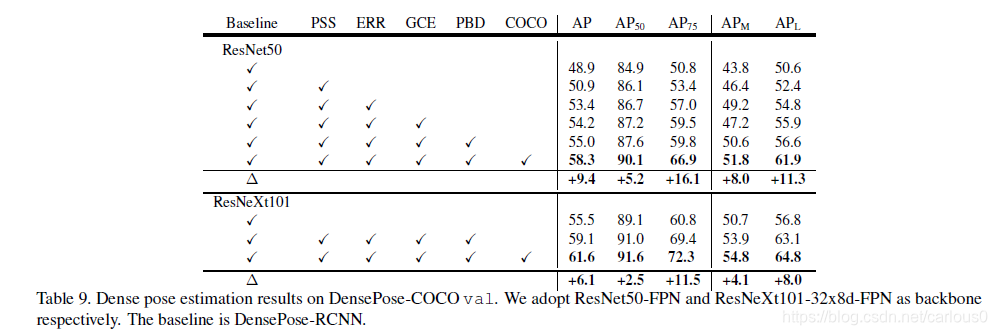
分别用resNet50,ResNeXt101,作为Backbone。用ResNet50-FPN,Parsing R-CNN比basline好。用所有 我们提出的方法,我们的方法达到55.0%AP。比baseline提高6.1。有了COCO预训练,Parsing R-CNN进一步提高了3.3AP。在AP75上显著提高,这说明我们的方法suface的点定位上更准确。到ResNeXt101上,进一步提高,这显示了Parsing R-CNN的泛化能力。
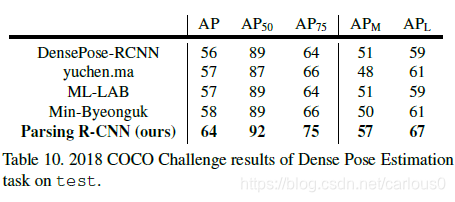
COCO 2018 Challenge:第一名。
可视化结果:

5.Conclusion
我们为实例级人体解析提出了一个新的基于区域的方法Parsing R-CNN。我们的方法探索了实例级人体解析的四个方面的问题,并在人体部件解析和稠密姿态估计上验证了有效性。基于提出的方法,我们在COCO2018上取得第一名。未来来我们会吧Parsing R-CNN扩展到实例级人体分析的更多应用上。














 1707
1707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









