







欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/132085757

图像来源于 SDXL 模型,艺术风格是赛博朋克、漫画、奇幻。
全身图像是指拍摄对象的整个身体都在画面中的照片,可以展示人物的姿态、服装、气质等特点,也可以表达一种情绪或故事。全身图像的拍摄需要注意构图、光线、角度、姿势等方面。
全身图像的提示词:
full body shot,(head-to-toe shot:1.2),1girl,an asian beatiful woman in a dress and jacket standing,(office lady high heels),
pantyhose,black leggings,outdoors,
people in the center,soft light,natural and comfortable pose,face to camera,
<lora:neg4all_xl_v6:1>,<lora:pantyhose_widget_xl_v10:1.2>,
负向提示词:
nsfw,(ng_deepnegative_v1_75t:1.2),badhandv4,
注意:SDXL 的提示词一般不需要高质量、低质量等提示词,尽量简洁。
随机种子:3830551278、3193321894、2206410753
常用的描述全身的词汇:
full-body shot
head-to-toe shot
complete body photograph
comprehensive full-body image
overall body shot
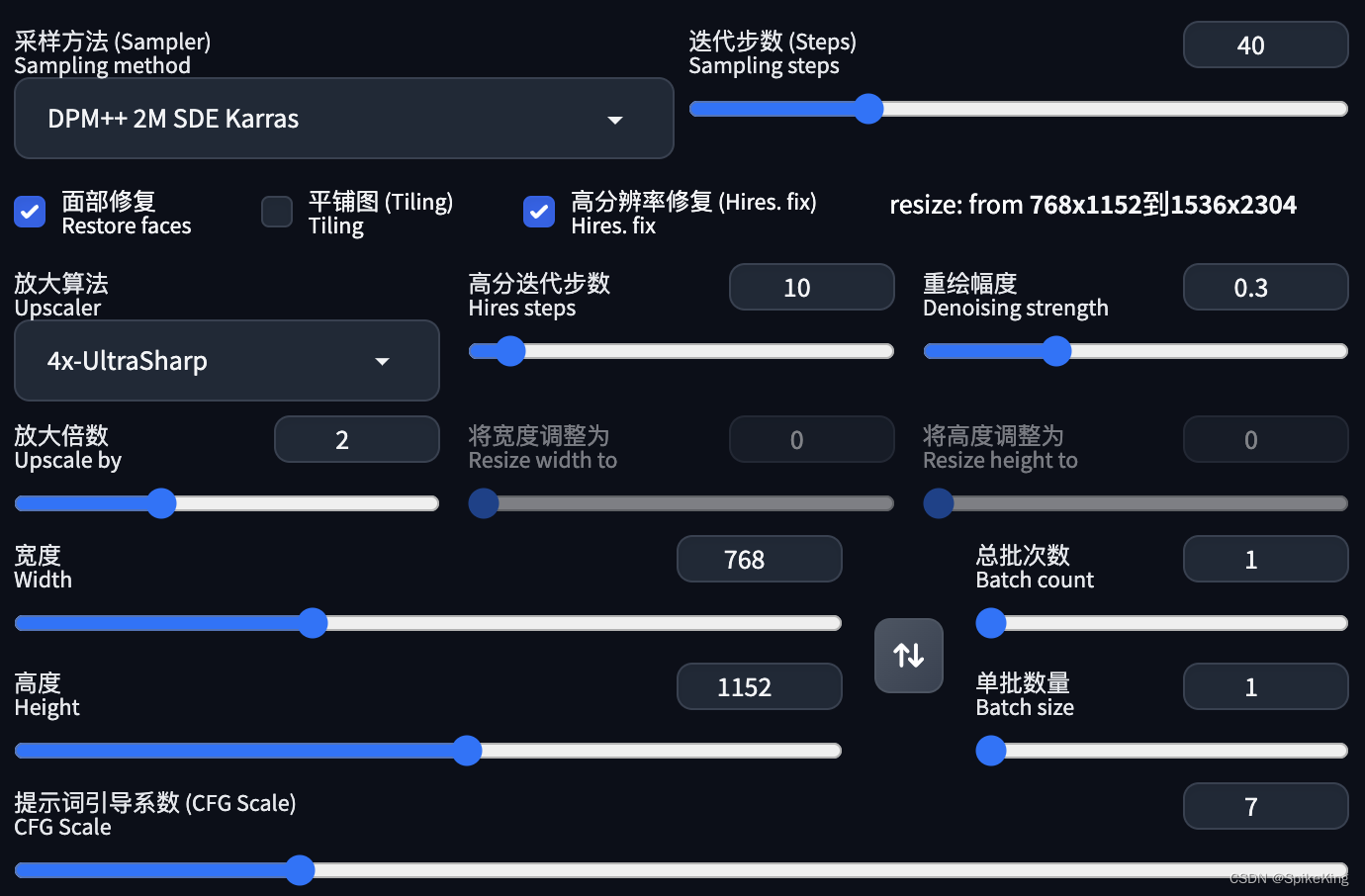
注意配置,保持图像稳定:
- 图像尺寸选择
768x1152,其他尺寸会导致人物比例失衡; - 开启
高分辨率修复,放大算法4x-UltraSharp,重复幅度 0.3;开启面部修复; - 开启
AfterDetailer,修复脸部和手部细节。
配置如下:
结合不同的风格,绘制全身图像,例如 赛博朋克 (Neonpunk)、幻想艺术 (Fantasy art)、影片风格 (Cinematic)、高增强 (Enhance) 等。
测试模型 DreamShaper_XL1.0_alpha2,即:

测试模型 GuoFeng4_XL_Real-Beta,即:

下载 GuoFeng 模型的真实版,来源于 吐司Art 模型网站。
其他测试模型 ArienmixxlAsian_v10_SDXL1.0、SDVN6-RealXL,效果均不稳定。
测试参数示例:
ethereal fantasy concept art of full body shot,(head-to-toe shot:1.2),1girl,an asian beautiful woman in a dress and jacket standing,(high heels),
pantyhose and leggings,outdoors,
people in the center,soft light,natural and comfortable pose,face to shot,
lora:neg4all_xl_v6:1,lora:pantyhose_widget_xl_v10:1.2, . magnificent, celestial, ethereal, painterly, epic, majestic, magical, fantasy art, cover art, dreamy
Negative prompt: nsfw,breast,(ng_deepnegative_v1_75t:1.2),badhandv4, photographic, realistic, realism, 35mm film, dslr, cropped, frame, text, deformed, glitch, noise, noisy, off-center, deformed, cross-eyed, closed eyes, bad anatomy, ugly, disfigured, sloppy, duplicate, mutated, black and white
Steps: 35, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Seed: 2206410753, Face restoration: GFPGAN, Size: 768x1152, Model hash: 57fdfb1fbe, Model: GuoFeng4_XL_Real-Beta, Clip skip: 2, ADetailer model: face_yolov8n.pt, ADetailer confidence: 0.3, ADetailer dilate/erode: 4, ADetailer mask blur: 4, ADetailer denoising strength: 0.4, ADetailer inpaint only masked: True, ADetailer inpaint padding: 32, ADetailer version: 23.7.6, Lora hashes: “neg4all_xl_v6: 9a735be26f5e, pantyhose_widget_xl_v10: 90b94c2a1974”, Version: v1.5.1
推荐 SDXL 版本的相关 LoRA,即:
- 负向提示词 LoRA:neg4all_xl_v6
- 袜子 LoRA:pantyhose_widget_xl_v10



















 2976
2976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











