







 超级会员免费看
超级会员免费看
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/141605718
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。
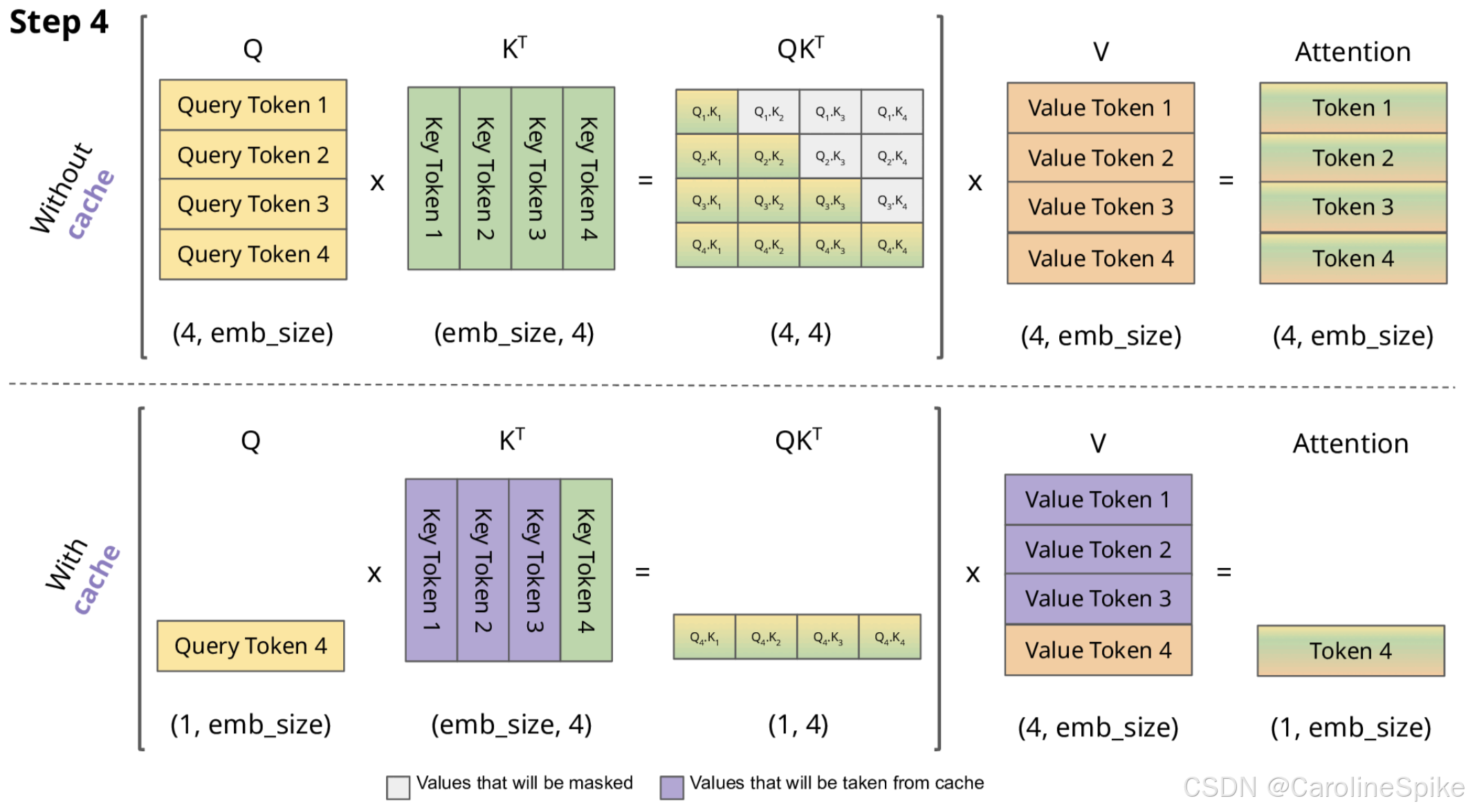
在 GPT 类模型中,KV Cache (键值缓存) 是用于优化推理效率的重要技术,基本思想是通过缓存先前计算的 键(Key) 和 值(Value),避免在推理过程中,重复计算 Mask 的 注意力(Attention) 矩阵,从而加速生成过程。
1. 公式
矩阵乘法的基础性质:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











