






是否大家在部署大模型的时候,总会遇到显存不足的问题呢?明明我的设备能存下模型参数啊!凭什么超内存了了呢!?
其实,这是 KV Cache 在作祟
KV Cache 是一种大模型推理加速的方法,该方法通过缓存 Attention 中的 K, V 来实现推理优化
1.背景:大模型推理的冗余计算
观察 Only-Decoder 架构的大模型生成的过程。
假设模型只是一层 Self-Attention,用户输入“中国的首都”,模型续写得到”是北京”。
生成过程如下:
-
将“中国的首都”输入模型,得到每个 token 的注意力得分(绿色)。使用 “首都” 的注意力表示,预测得到下一个 token 为 ”是”(省略计算 logits 的过程)。
-
将 “是” 拼接到原来的输入,得到 “中国的首都是” ,将其输入模型,得到注意力表示,使用 “是” 的注意力表示,预测得到下一个 token 是 “北”。
-
将“北”拼接到原来的输入,依此类推,预测得到“京”,最终得到“中国的首都是北京”
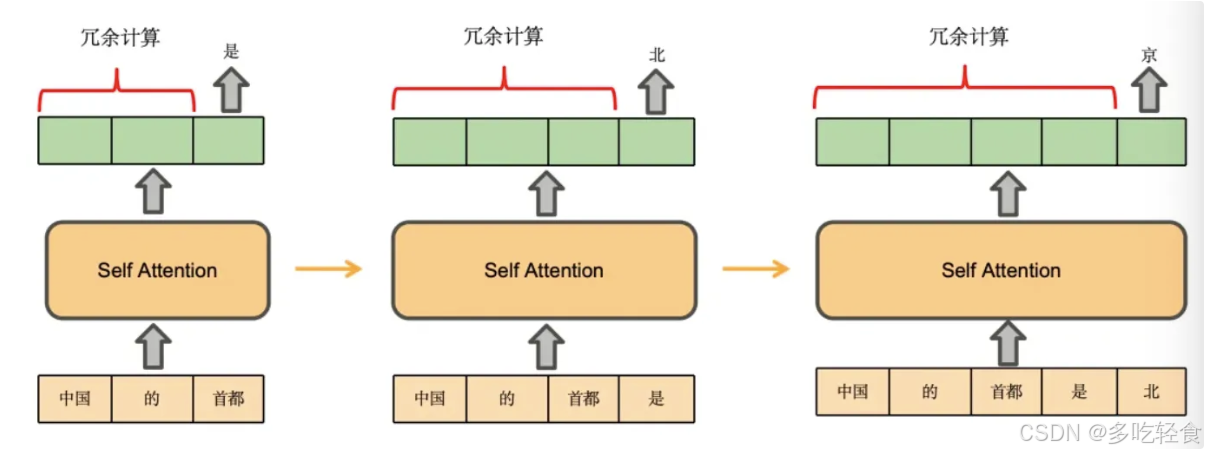
在每一步生成中,仅使用输入序列中的最后一个 token 的注意力表示 即可预测出下一个 token。但是模型还是并行计算了所有 token 的注意力表示,其中产生了大量的冗余计算(包含 QKV 映射,attention 计算等),并且输入长度越长,产生的冗余计算量越大。
例如:
- 在第一步中,仅需要使用“首都”的注意力表示,即可预测到 “是”,但模型仍然会并行计算出 “中国”、“的” 这两个 token 的注意力表示。
- 在第二步仅需要“是”就可以预测到“北”,但模型会并行计算之前所有的。
2.KV Cache
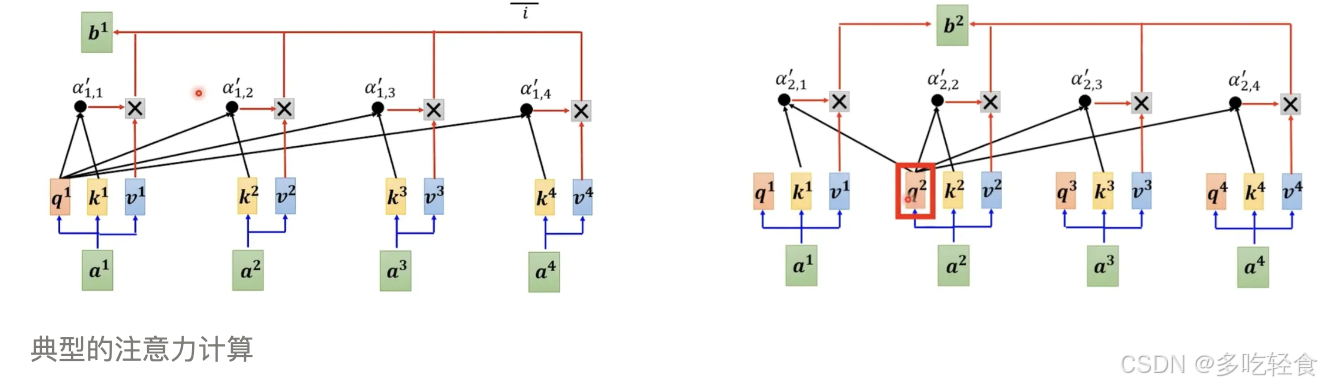
在推理阶段,当输入长度为 n,我们仅需要使用 b n b^n bn 就可以预测下一个 token,但模型会并行计算出 b 1 , b 2 , … , b n − 1 b^1, b^2,…,b^{n-1} b1,b2,…,bn−1 ,这里产生了大量的冗余计算。
实际上 b n b^n bn 可以直接通过公式 b n = ∑ i = 1 n s o f t m a x ( q n ⋅ k i ) v i b^n=\sum^n_{i=1}softmax(q^n·k^i)v^i bn=∑i=1nsoftmax(qn⋅ki)vi 计算得出,即 b n b^n bn 只与 q n q^n qn、所有的 k , v k, v k,v 有关。
KV Cache 的本质是空间换时间。他将历史输入的 token 中的 k 和 v 缓存下来,避免每一步生成都重新计算历史 token 的 k 和 v 以及 注意力表示 b 1 , b 2 , … , b n − 1 b^1, b^2,…,b^{n-1} b1,b2,…,bn−1 ,而是直接通过 b n = ∑ i = 1 n s o f t m a x ( q n ⋅ k i ) v i b^n=\sum^n_{i=1}softmax(q^n·k^i)v^i bn=∑i=1nsoftmax(qn⋅ki)vi 的方式计算得到 b n b^n bn,然后预测下一个 token。
举例,用户输入“中国的首都”,模型续写得到的输出为“是北京”,KV Cache每一步的计算过程如下。
第一步生成时,缓存 K, V 均为空,输入为 “中国的首都”,模型将按照常规的方法进行并行计算:
- 并行计算得到每个 token 对应的 k, v,以及注意力表示 b 1 , b 2 , b 3 b^1,b^2,b^3 b1,b2,b3。
- 使用 b 3 b^3 b3 预测下一个 token,得到 “是”
- 更新缓存,令 K = [ k 1 , k 2 , k 3 ] K=[k^1,k^2,k^3] K=[k1,k2,k3], V = [ v 1 , v 2 , v 3 ] V=[v^1,v^2,v^3] V=[v1,v2,v3]
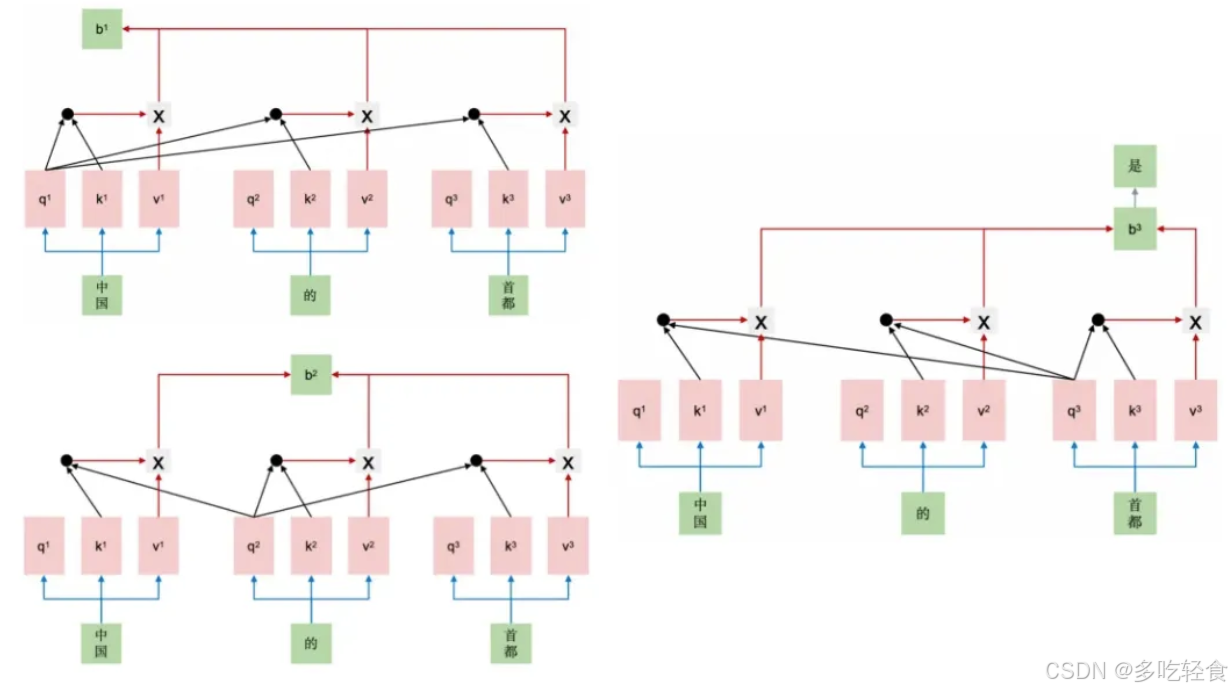
第二步生成时,计算流程如下:
- 仅将“是”输入模型,对其词向量进行映射,得到 q 4 , k 4 , v 4 q^4,k^4,v^4 q4,k4,v4
- 更新缓存,令 K = [ k 1 , k 2 , k 3 , k 4 ] K=[k^1,k^2,k^3,k^4] K=[k1,k2,k3,k4], V = [ v 1 , v 2 , v 3 , v 4 ] V=[v^1,v^2,v^3,v^4] V=[v1,v2,v3,v4]
- 计算 b 4 = ∑ i = 1 4 s o f t m a x ( q 4 ⋅ k i ) v i b^4=\sum^4_{i=1}softmax(q^4·k^i)v^i b4=∑i=14softmax(q4⋅ki)vi,预测下一个 token,得到 “京”
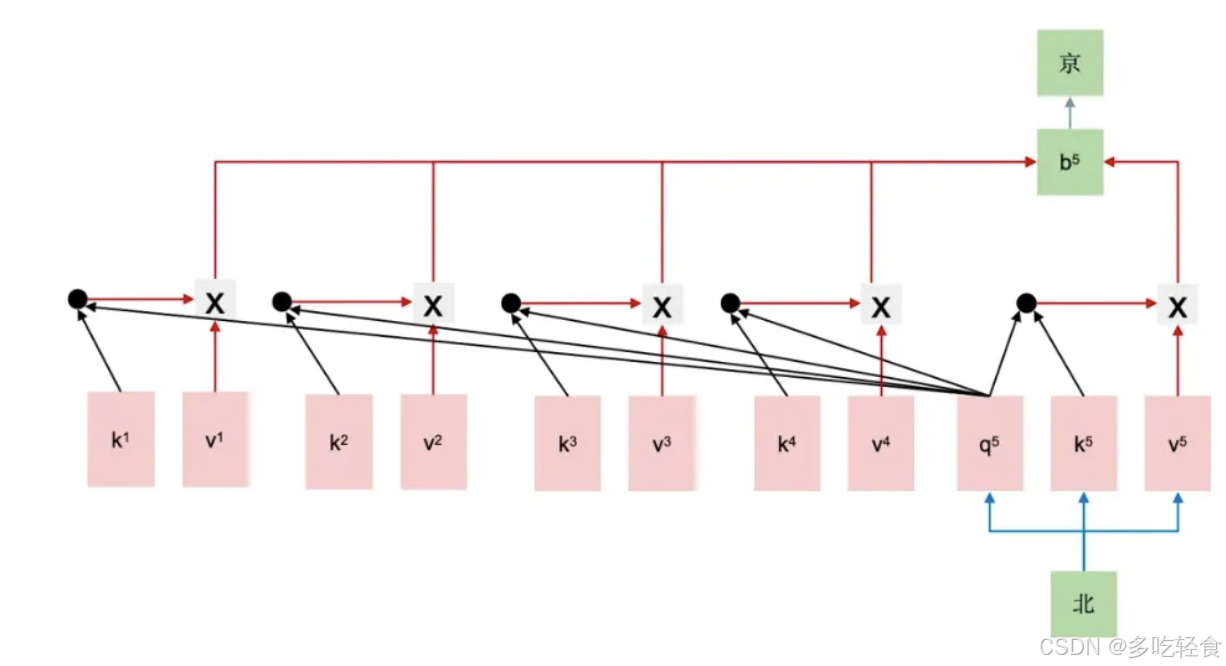
上述过程中,只有第一步生成的时候,模型需要计算所有的 token 的 k , v k, v k,v,并缓存下来。此后的每一步,仅需要计算当前 token 的 q , k , v q, k, v q,k,v ,更新缓存 K , V K,V K,V ,然后使用 q , K , V q, K, V q,K,V 算出当前 token 的注意力表示,预测下一个 token
KV Cache 是以空间换时间,当输入序列非常长的时候,需要缓存非常多 k 和 v,显存占用非常大。
为了缓解该问题,可以使用 MQA、GQA、Page Attention 等技术。

















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









