







PRML Chapter 03 Linear Models for Regression
本章主要介绍了监督学习中的基本模型——线性回归模型,即对给定的 D D 维输入,输出一个或者多个连续的目标变量,如第一章介绍的多项式拟合模型即是一种简单的线性回归模型。
Linear Basis Function Models
线性回归的最基本的模式定义如下,
如式(3.1)所示, y(x,ω) y ( x , ω ) 被定义为输入 x x 的线性函数,这在很多时候都无法满足应用的需求,因为非线性显然是更常见的状态。因此,如果我们将式(3.1)中的输入 x x 替换为输入的函数形式 ϕ(x) ϕ ( x ) ,那么我们则可以得到以下扩展形式,
式(3.2)中的函数 ϕ(x) ϕ ( x ) 称为基函数,可以看到,通过使用非线性基函数, y(x,ω) y ( x , ω ) 能够表示为输入 x x 的非线性函数。然而,我们之所以称式(3.2)为线性模型,是因为 y(x,ω) y ( x , ω ) 是参数 ω ω 的线性函数。尽管式(3.2)具有较强的数据拟合能力,但其应用场景也极大的收到了其自身特性的约束,其主要局限性为,
- 容易造成维数灾难:因为我们假设式(3.2)中的基函数 ϕ(x) ϕ ( x ) 在观测到任意数据前即确定,因此,当输入空间的维度 D D 较快增长时,基函数的数量通常随之成指数级增长;
一般地,我们常用的基函数形式有,
高斯基函数:其中控制了基函数在输入空间中的文职,参数 s s 控制了基函数的空间大小,
Sigmoid基函数:
ϕj(x)=σ{x−μjs}(3.4) (3.4) ϕ j ( x ) = σ { x − μ j s }其中 σ(a) σ ( a ) 是logistic sigmoid函数,定义为,
σ(a)=11+exp(−a)(3.5) (3.5) σ ( a ) = 1 1 + e x p ( − a )
a. Maximum Likelihood and Least Squares
本节主要讨论了最大似然函数和最小化平方误差(最小二乘法),首先进行概率建模,假设目标值 t t 由确定的函数给出,其定义如式(3.6)所示,
其中,我们定义噪声 ϵ ϵ 是一个零均值的高斯随机变量,精度(方差的倒数)为 β β ,我们可以使用模型式(3.6)中的右侧预测值 y(x,ω)+ϵ y ( x , ω ) + ϵ 的分布来描述左侧目标值 t t ,因此我们有,
考虑式(3.7)的最大似然形式,定义输入数据集 X={x1,x2,...,xN} X = { x 1 , x 2 , . . . , x N } ,对应的目标值为 t1,t2,...tN t 1 , t 2 , . . . t N ,我们把目标向量 {tn} { t n } 记作 t t ,则有,
对式(3.8)取对数,可以得到,
其中 ED E D 为平方和误差函数,我们也可以从式(3.8)和(3.9)中看出,线性回归模型在噪声均值为零的情况下,其最大似然等于最小平方误差,
得到最大对数似然的公式(3.8)后,我们则可以通过对参数进行求偏导得到参数的解有,
其中 Φ Φ 定义为一个 N∗M N ∗ M 的矩阵,称为设计矩阵(design matrix),
若式(3.6)对偏置 ω0 ω 0 求偏导,我们可以将式(3.10)演化为式(3.14),
并对偏置 ω0 ω 0 求偏导,得到,
从式(3.15)至(3.17)可以看出,偏置的主要作用是补偿训练集上目标值的均值和基函数均值的加权平均之间的差值。
b. Geometry of least squares
从几何角度看最小平方和误差(最小二乘法),可以考虑一个 N N 维空间,它的坐标轴由给出,即 t={t1...tN}T t = { t 1 . . . t N } T 是这个空间中的一个向量。对于每一个具有 M M 个基函数的线性回归模型 y(x,ω) y ( x , ω ) ,其可以看作是一个在 N N 维空间中的维子空间 S S ,因此,函数表示子空间 S S 中的任意位置。如果把子空间看作回归函数的预测值空间,而将 N N 维坐标空间视为目标值空间,则最小平方和误差的目标则是寻找与目标值空间中的目标向量 t t 最近的预测值空间中的预测向量 y y 。
如下图所示,我们要在子空间中寻找使得距离 t t 最近的参数,一般地,我们认为 t t 在子空间上的正交投影为 ω ω 的解。
c. Sequential learning
与第二章介绍的一样,顺序学习的主要目的还是解决实时应用与一次计算量过大的问题,这里我们可以选择一个数据点或者一小部分数据点,运用随机梯度下降(stochastic gradient descent)的技术,实现参数的迭代更新。如果误差函数由数据点的和 E=∑nEn E = ∑ n E n 组成,那么使用随机梯度下降实现的参数顺序学习如下所示,
对于如式(3.10)所示的最小平方和误差函数,我们可以获得如下形式的推导,
d. Regularized least squares
最大似然估计在数据量较小的情况下容易造成过拟合的问题在线性回归模型上仍然存在,因此为了降低这种情况,我们使用正则化项,也就是第一章中的惩罚项。即我们可以将误差函数的形式定义为,
考虑平方和误差则有如下形式,
对式(3.21)对参数 ω ω 求偏导,可以得到参数的解,
与式(3.11)进行相应的比较,会发现式(3.22)多了一个 λ λ ,即同样是最小化误差函数,加入了正则项后,由于权值 λ λ 的作用,会导致基函数 ϕ ϕ 的复杂性大大降低,进而实现对过拟合的降低。
e. Multiple outputs
对于多元目标值,一般会有两种想法,假设对于 K K 元目标值(),
- 方案一:对于 K K 元目标向量中的每一个分量,引入一个不同的基函数集合,即,这样就变成了多个独立的线性回归问题;
方案二:与方案一不同,方案二中对于所有的分量使用相同的基函数集合,而使用不同的参数,具体的定义 y y 是一个维的列向量,定义参数 W W 式一个 M∗K M ∗ K 的向量(对于目标向量的每一个维度,有不同的 M M 个参数),而基函数是一个 M M 维的列向量,每个元素为,其中 ϕ0(x)=1 ϕ 0 ( x ) = 1 ,则我们可以有如下的线性回归函数形式,
y(x,ω)=WTϕ(x)(3.23) (3.23) y ( x , ω ) = W T ϕ ( x )
The Bias-Variance Decomposition
Linear Basis Function Models部分讲到的线性回归模型,在现实的应用中往往具有很高的局限性,其主要表现在以下几个方面,
- 最大似然函数的通病,即在有限规模的数据集上训练复杂模型时,容易造成过拟合的现象;
- 在线性回归函数训练前,通常都指定了基函数的形式和数量,这很大程度上限制了线性回归模型描述数据中有趣的规律的灵活性;
- 使用正则化项来控制过拟合的主要问题时如何选择正确的正则化系数 λ λ ,从而pick出函数空间中中等复杂程度的模型。
a. Background
因此,为了进一步解决以上线性回归模型的以上三个问题,频率学派和贝叶斯学派分别提出了自己的方法,本节介绍的偏置-方差折中法(bias-variance trade-off)即是一种频率学派的解决办法。
在第二章决策论部分,我们定义了损失函数(loss function)为 L(t,y(x)) L ( t , y ( x ) ) ,并且采用损失函数的期望式(3.24)来选择最优的模型,
以使用平方损失函数为例,即 L(t,y(x))={y(x)−t}2 L ( t , y ( x ) ) = { y ( x ) − t } 2 ,对误差函数的期望求偏导,可以得到最优的函数模型 h(x) h ( x ) ,具体推导如下,
因此,当我们知道了条件概率分布 p(t|x) p ( t | x ) 后,损失函数即能给出最优的预测结果,如式(3.27)所示。我们可以对式(3.25)的平方项做一些处理,进而得到偏置-方差折中法,
式(3.28)是对式(3.25)中平方项的一个简单的扩展,将式(3.28)代入式(3.25)可以得到式(3.29),交叉项在积分的过程中被消掉,
上式可以看作是预测函数 y(x) y ( x ) 与最优函数 h(x) h ( x ) 之间的偏差(即两者之间的相似程度),加上最优函数与目标值之间的方差(即最优函数在目标值附近的波动)。
b. Bias-variance trade-off
对于偏置-方差折中法,一般考虑使用参数 ω ω 控制的函数 y(x,ω) y ( x , ω ) 对 h(x) h ( x ) 建模,
- 贝叶斯学派:从贝叶斯的观点来看,模型 y(x,ω) y ( x , ω ) 的不确定性由 ω ω 的后验概率分布来确定,因此会对利用到整个 ω ω 的分布;
- 频率学派:从频率学家的角度看,主要是利用数据集 D 对参数 ω ω 进行点估计,在具有多个数据集 D 的情况下,对每一个数据集训练出一个函数和其相应的平方损失值,对所有的数据集上得到的函数进行平均来评估模型。
从以上两派人马的观点可以看出,其核心思想都是通过平均来降低过拟合的程度,贝叶斯利用的是参数 ω ω 的平均,而频率观点采用数据集上的平均。因此,与式(3.29)类似,对应于每一个数据集 D 有,
对比式(3.29)和(3.30),(3.30)无非就是对多个数据集进行了一下平均。式(3.30)的第一项表示所有数据集得出的平均预测与最优模型 h(x) h ( x ) 之间的差异即平方偏置(bias);第二项则度量了对于单个数据集,单个模型给出的解在平均值附近的波动,这被称为方差(variance)。
现在我们可以看一下式(3.30)用以降低过拟合的原理,对于数据集上的损失均值(3.30),很显然,我们的目标是要使其最小化,
- 情况一:当偏差趋近于零时,意味着各数据集上训练得到的模型平均后与最优模型基本吻合,这时往往就是过拟合了,方差部分因为过拟合的模型无法拟合每一个数据集,因此便会产生较大的损失,造成式(3.30)无法达到最小值;
- 情况二:当方差趋近于零时,意味着每一个数据集上训练得到的模型都差别不大,这显然是发生了欠拟合,因此偏差就会成倍增加。
综合以上两种极端情况,可以看出偏置-方差折中的原理,即通过最小化约束来互相惩罚。然而这一方法也具有很大的局限性,主要表现在其依赖于所有数据集的平均,而实际应用中,往往不存在多个数据集,即使存在也会对其合并,使用更大规模的数据训练复杂模型效果会更好。
Bayesian Regression Model
基于以上传统的最大似然的局限性,贝叶斯方法通常是引入参数的先验分布,并利用贝叶斯定理计算后验分布在先验分布上的平均,从而解决,
- 问题一:使用最大似然的线性回归模型,往往需要根据特定的应用确定合适的模型复杂度的问题;
- 问题二:最大似然函数的过拟合问题;
- 问题三:降低因引入正则项而增加的计算量。
a. Parameter distribution
在偏置-方差折中的方法里,主要考虑的是预测函数 y(x,ω) y ( x , ω ) 中参数 ω ω 的点估计,而贝叶斯方法考虑参数 ω ω 的全分布,因此,我们可以定义参数 ω ω 服从均值为 m0 m 0 、协方差 S0 S 0 的高斯分布,
给定数据集的目标值 t t ,我们在式(3.7)定义了似然函数 p(t|ω) p ( t | ω ) ,进而可以得到相应的后验分布,
以上即为基于贝叶斯方法的线性回归函数参数分布的基本形式,在PRML中,为了简化讨论,考虑参数分布为均值为零的高斯分布,并且分布由精度参数 α α 控制,
这样后验分布中 mN、S−1N m N 、 S N − 1 也会发生相应的变化。考虑后验分布(3.32)的最大似然,我们称之为最大后验分布(Maximum A Posteriori),对其取对数的结果如下,
将式(3.34)与基于最大似然估计的式(3.14)相比,会发现最大后验比最大似然多了一个参数 ω ω 的二次项,这显然与加入正则项的最大似然一致。
b. Predictive distribution
在实际应用中,更常用到的是预测分布,即给定新的输入值 x x 预测出新的 t t ,其具体形式如下,
| 参数 | 含义 |
|---|---|
| t t | 训练数据集中的目标值集合 |
| α α | 参数 ω ω 的控制参数,来自先验(3.35) |
| β β | 似然函数(3.7)的控制参数,定义为高斯分布的精度 |
因为式(3.57)中的两项均为高斯分布,因此我们可以把预测分布表示为,
式(3.37)中的第一项取自似然函数(3.7),被定义为精度,可以看作是数据中的噪声;第二项与先验(3.35)有关,其反映了预测分布与参数 ω ω 关联的不确定性。很显然的,当我们观测到足够多的数据时,预测分布的结果与最大似然类似,这样,我们的先验起的作用将很小,即式(3.37)仅仅只由数据中的噪声 β β 控制。
c. Equivalent kernel
等价核可以看作一种非参数的训练方法。考虑式(3.33),如果采用零均值先验的参数分布即 m0=0 m 0 = 0 ,则式(3.33)变为,
将式(3.38)代入式(3.2),则有,
其中 SN S N 由式(3.34)定义,因此在点 x x 处的预测均值由训练机目标变量 tn t n 的线性组合给出,
式(3.41)的 k(x,xn) k ( x , x n ) 函数被称为平滑矩阵(smoother matrix)或者等价核(equivalent kernel)。对于式(3.40),我们可以认为等价核描述的是新输入值 x x 与已有数据集中数据点 xn x n 之间的距离,而 y(x,mN) y ( x , m N ) 则是数据点的目标值 tn t n 与这一距离的加权平均。比较常见的方法比如 K K 最近邻。
Bayesian Model Comparison
贝叶斯模型比较(Bayesian Model Comparison)是贝叶斯学派看待模型复杂度的方法论,即通过概率来表示模型选择的不确定性,对每一个模型,利用其整个参数分布上对数据集的拟合程度反应其优先级。假设我们有个模型 {i} { M i } ,其中 i=1,...,L i = 1 , . . . , L 。对于给定数据集 D 和模型的先验 p(i) p ( M i ) ,我们定义其后验分布为,
对于式(3.42),先验分布 p(i) p ( M i ) 用于描述不同模型之间的优先级。模型证据(model evidence) p(|i) p ( D | M i ) ,可以看作是模型空间上的似然函数,因此也被称为边缘似然(marginal likelihood),它表达了考虑数据拟合能力后的模型优先级,描述了从一个模型生成一个数据集 D 的概率。
- 模型选择(model selection):对于模型求平均来选择模型可以简单的近似为使用最有可能的一个模型作为预测。
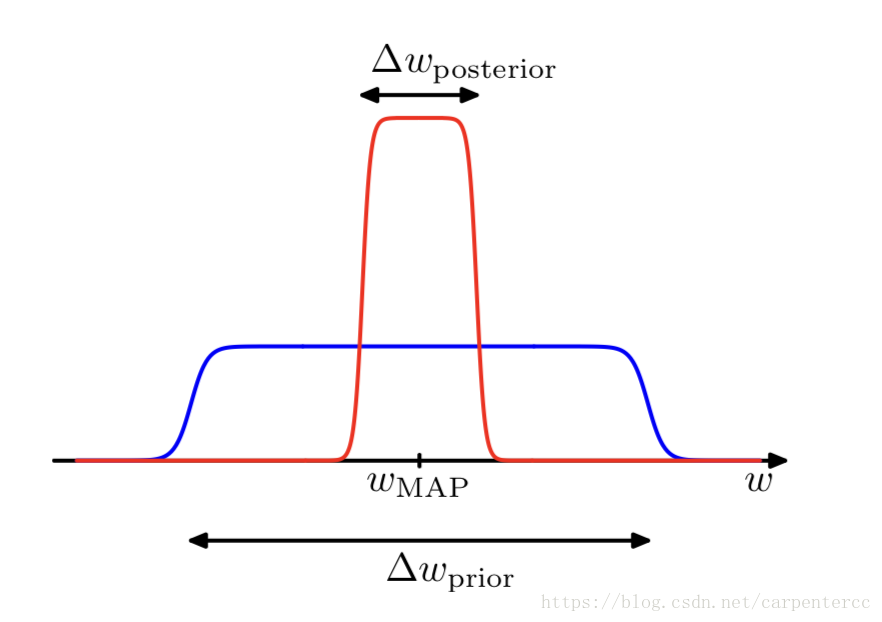
使用以上的模型选择思想,可以对模型证据进行相应的近似选择,考虑使用一个参数 ω ω 控制模型证据,
通过考虑参数 ω ω 的近似,我们可以更清楚的认识到模型证据的性质并选择出更优的模型,
考虑每一个模型仅有一个参数 ω ω ,由式(3.5)可知 p(ω|,i)∝p(|ω,i)p(ω|i) p ( ω | D , M i ) ∝ p ( D | ω , M i ) p ( ω | M i ) ,对于似然函数 p(|ω,i) p ( D | ω , M i ) ,我们考虑使用最有可能的 ωMAP ω M A P 来近似,
如图所示,式(3.46)对 ω ω 的积分近似为对尖峰 ωMAP ω M A P 与 Δωposterior Δ ω p o s t e r i o r 的乘积。类似地,我们可以对先验分布 p(ω|i) p ( ω | M i ) 进行相同的近似,对于平坦的宽度为 Δωprior Δ ω p r i o r 的先验分布,其 p(ω|i)=1Δωprior p ( ω | M i ) = 1 Δ ω p r i o r ,因此式(3.43)可以表示为,式(3.44)简化了所有的 i M i ,
对式(3.47)求对数可以得到,
类似地,对于多个参数( M>0 M > 0 ),有
对于式(3.48)和式(3.49)中的第一项可以理解为最优参数下模型对于数据的拟合程度,而第二项作为惩罚项,当 Δωposterior Δ ω p o s t e r i o r 变小时,即参数更加接近数据时, ln(ΔωposteriorΔωprior) l n ( Δ ω p o s t e r i o r Δ ω p r i o r ) 会变成一个很小的负数,从而达到惩罚的效果,显然,我们的目标是最大化(3.48)或者(3.49),即最大化模型对数据的拟合程度。
以上便是从贝叶斯角度,对模型复杂度的理解,以及模型选择中对过拟合的判别。
The Evidence Approximation
a. Evaluation of the evidence function
纯粹的贝叶斯处理方法中,通常会引入超参数 α α 和 β β 的先验分布,然后通过对超参数以及参数 ω ω 求积分的方式做预测。但实际情况是,我们可以解析的求出对参数 ω ω 的积分,或者解析的求出对参数 α α 、 β β 的积分;却无法对所有的这些参数解析的求得,因此,定义一种近似方法,
- 证据近似(evidence approximation):首先获取到超参数的近似形式,再利用该近似对参数 ω ω 求积分。证据近似在统计学的文献中也被称为经验贝叶斯(empriccal Bayes)、第二类最大似然(type2 maximum likelihood)、或者推广的最大似然(generalized maximum likelihood)。
如果引入 α α 和 β β 的超参数先验分布,那么预测分布可以通过 ω、α、β ω 、 α 、 β 求积分的方式获得,式(3.50)省略了对输入 x x 的以来,表示多个样本的目标值 t t ,而表示一个样本的多元目标值,
由于无法解析的求得所有参数的解,证据近似的方法告诉我们可以找到后验分布 p(α,β|t) p ( α , β | t ) 的近似解 α̂ α ^ 和 β̂ β ^ ,由此,式(3.50)表示的预测分布就可以近似为,
因此,我们只需要求得 α α 、 β β 的近似 α̂ α ^ 、 β̂ β ^ 即可,而由贝叶斯定理可知, p(α,β|t) p ( α , β | t ) 服从,
在证据框架中,我们可以通过最大化边缘似然函数 p(t|α,β) p ( t | α , β ) 得到 α̂ α ^ 、 β̂ β ^ 。
对于边缘似然分布 p(t|α,β) p ( t | α , β ) ,通过全职参数进行积分可以得到,即
对于线性回归模型,由式(3.9)、(3.10)、(3.35)可得,
其中 E(ω) E ( ω ) 可以看作是正则化的平方和误差函数,如果不考虑一些比例常数的话。通过对参数 ω ω 配平方,可以得到,
其中,
对于式(3.54)的边缘似然函数,其对数形式定义为,
式(3.59)即为证据函数的表达式。
b. Maximizing the evidence function
最大化证据函数的主要目的式根据式(3.59)求出超参数 α α 、 β β 的最佳近似 α̂ α ^ 、 β̂ β ^ 。首先定义式(3.60)的特征向量方程,
由式(3.56)可知 A A 的特征值为 α+λi α + λ i ,则对于式(3.59)中的 ln|A| l n | A | 对于 α α 求导,
因此式(3.59)对 α α 求偏导可得,
类似地,我们可以使式(3.59)对 β β 求偏导,进而得到,
c. Effective number of parameters
式(3.62)定义了超参数 α α 的值,这一值通过式(3.53)中的先验分布 p(ω|α) p ( ω | α ) 控制着参数 ω ω 的分布,考虑式(3.63),显然有 λiλi+α λ i λ i + α 位于0到1之间,因此式(3.63)中 0≤γ≤M 0 ≤ γ ≤ M 。对 α α 的值的影响则主要分为两种情况,
- 情况一: λi≫α λ i ≫ α ,此时 γ γ 接近于1,因此对应的参数 ωi ω i 将会与最大似然值接近。
- 情况二: λi≪α λ i ≪ α ,此时 γ γ 接近于0,相对应的参数 ωi ω i 也会接近于0。
由于以上两种情况,我们可以利用 γ γ 很好的度量先验分布 p(ω|α) p ( ω | α ) 中的参数数量。














 588
588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









