










I.Spark Streaming另类在线实验
II.瞬间理解Spark Streaming本质
扩展Spark的内容来适合自己的业务模型,自己能够进行框架的维护,就好比你拿到一个开源源代码,即使你编译引用库,那么你后期的维护和后期的扩展都会受到极大的限制,如果你自己依据于Spark的源码进行改造,那么自己后期的维护和扩展都是依赖于自己的设计来适合公司的业务逻辑,从而方便维护和可扩展
Spark Streaming本来就是Spark Core中的一个子框架,为什么选Spark Streaming,目前用的最多的是Spark core,Spark SQL涉及到很多SQL语法的解析和优化,不适合作为一个子框架来研究,而Spark R不太成熟支持的功能有限,Spark Graph似乎没有扩展,那么Spark Graph后期的发展可能不大,并且图计算涉及到很多数学级别的算法,机器学习关键是大部分的库涉及到太多的数学知识,所以选择Spark Streaming作为学习的基石。
超过50%的人认为Spark Streaming对Spark开发人员最具有吸引力,大家考虑使用Spark主要是Spark Streaming
1.流式计算,这是一个流处理的时代,一切数据如果不是流的方式,那么就是一个无效的数据
2.流式处理才是真正的我们对大数据的真正影响,而不是批处理和数据挖掘,Spark非常强悍的是可以在线的利用spark R,Spark图计算,Spark SQL,你根本不需要任何的设置,Spark Streaming 就可以调用其它的子框架。
3.整个Spark的所有程序,基于Spark Streaming的程序最容易出问题,因为数据是不断流动的,要动态地控制数据的流入,作业的切分和数据的处理,数据量的不确定性
4.其实Spark Streaming与其他子框架的不同之处在于,Spark Streaming很像Spark Core之上的一个应用程序
通过将Spark Streaming中的batch interval放到足够的大,从而方便理解整个过程
二.Spark Streaming另类在线实验
附上Spark在线黑名单程序如下:
package com.dt.spark.com.dt.spark.streaming
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* 使用Scala开发的集群运行的Spark 在线黑名单过虑的程序
* @author DT大数据梦工厂
* 背景描述:在广告点击计费系统中,我们在线过滤黑名单的点击,进而保护广告商的利益,只进行有效的广告商利益或者在防刷屏评分(或者流量)系统,过滤掉无效的投票或者评分或者流量
* 实现技术:使用trasform API直接基于RDD编程,进行join操作
*/
object OnlineBlackListFilter {
def main(args: Array[ String]){
/**
* 第1步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要链接的Spark集群的Master的URL,如果设置
* 为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差(例如
* 只有1G的内存)的初学者 *
*/
val conf = new SparkConf() //创建SparkConf对象
conf.setAppName( "OnlineBlackListFilter") //设置应用程序的名称,在程序运行的监控界面可以看到名称
conf.setMaster( "spark://Master:7077") //此时,程序在本地运行,不需要安装Spark集群
val ssc = new StreamingContext(conf, Seconds( 300))
//黑名单数据准备,实际上黑名单一般都是动态的,例如在Redis或者数据库中,黑名单的生成往往有复杂的逻辑,具体情况算法不同,但是
//在Spark Streaming进行处理的时候每次都能访问完整的信息
val blackList = Array(( "Hadoop", true), ( "mahout", true))
val blackListRDD = ssc.sparkContext.parallelize(blackList, 4)
val adsClickStream = ssc.socketTextStream( "Master", 9999)
/*此处模拟的是广告点击的每条数据的格式:time,name此处map操作的结果是name,(time,name)的格式*/
val adsClickStreamFormatted = adsClickStream.map{ads => (ads.split( " ")( 1),ads)}
adsClickStreamFormatted.transform(userClickRDD => {
//通过leftOuterJoin操作标刘了左侧用户广告点击内容的RDD的所有内容,又获得了相应点击内容是否过滤
val joinedBlackListRDD = userClickRDD.leftOuterJoin(blackListRDD)
/*进行filter过滤的时候,起输入元素是一个Tuple:(name,((time,name),boolean))
* 其中第一个元素是黑名单的名称,第二个元素的第二个元素是进行leftOuterJoin的时候是否存在值
* 如果村在的话,表示当前广告点击的是黑名单,需要过滤掉,否则的话则是有效点击内容:
* */
/*IMF晚8点大数据实战YY直播频道号:68917580*/
val validClicked = joinedBlackListRDD.filter(joinedItem => {
if(joinedItem._2._2.getOrElse(false)){
false
}else{
true
}
})
validClicked.map(validClicked => {validClicked._2._1})
}).print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
将程序的Batch Interval 设置为300秒
val ssc = new StreamingContext(conf,Seconds(300))
启动数据发送端口:nc -kl 9999
[root@Master sbin]# nc -kl 9999
123 Hadoop
345 Spark
789 Hadoop
899 AAA
999 BBB
111 CCC
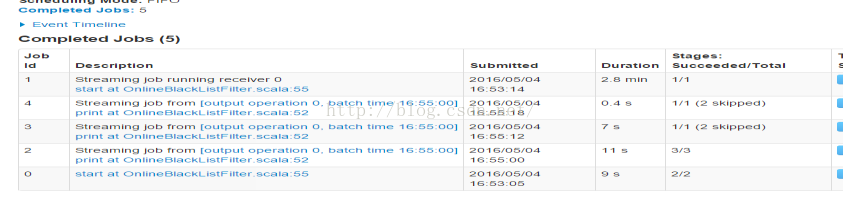
运行完毕后查看History日志记录

发现应用执行的时间为3.1min
进入应用查看每个job的执行情况
发现一共完成了5个job
点击进入job id为0的job查看发现
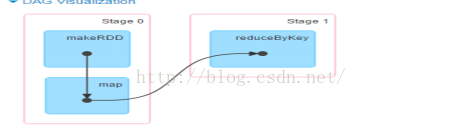
MakeRDD作为整个job的一个独立的Stage,只是在一个Worker Node上执行,此Job不体现我们的业务逻辑代码。这个Job是出于对后面计算的负载均衡的考虑
Job 1:运行的是时间花了2.8min而且只有一个stage

点击stage发现:
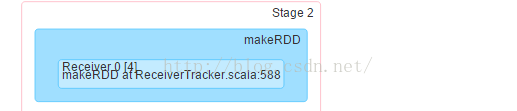
原来Receiver是通过一个Job来启动的。那肯定有一个Action来触发它。
查看Tasks部分:

只有一个Worker运行此Job。是用于接收数据。
Locality Level是PROCESS_LOCAL,原来是内存节点。所以,默认情况下,数据接收不会使用磁盘,在内存足够大的情况下会直接使用内存中的数据。
那么它就是一个专门用来接收数据的线程,一直进行listen/reciver数据
从而我们发现:Spark Streaming中可以启动很多Job,而且每个job可以互相配合
Job 2:看Details可以发现整个代码的流动过程,体现在Stage 3、Stage 4、Stage 5
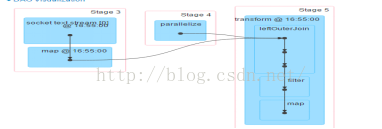

发现stage4是在两个worker上执行,且启动4个task
Stage 5只在Worker4上。这是因为这个Stage有Shuffle操作。
三. 瞬间理解Spark Streaming本质
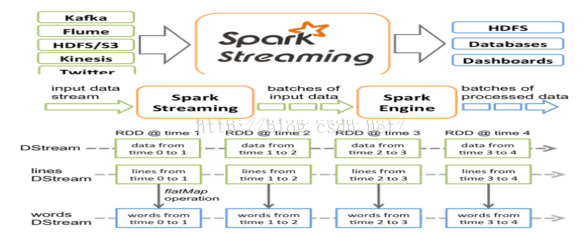
DStream是一个没有边界的集合,但是没有大小的限制,不但的产生RDD,对于DStream的处理是作用在RDD上
Spark Streaming接收Kafka、Flume、HDFS和Kinesis等各种来源的实时数据输入,进行处理后,处理结果保存在HDFS、Databases等各种地方。
Spark Streaming接收这些实时输入数据流,会将他们按批次划分,然后交给Spark引擎处理,生成按照批次划分的结果流。
Spark Streaming提供了表示连续数据流的,高度抽象的被称为离散流的Dstream。Dstream本质上表示RDD的序列。任何对DStream的操作都会转变为对底层RDD的操作
Spark Streaming使用数据源产生的数据流创建Dstream,也可以在已有的Dstream上使用一些操作来创建新的Dstream.
DStream是一个没有边界的集合,没有大小的限制。
DStream代表了时空的概念。随着时间的推移,里面不断产生RDD。
锁定到时间片后,就是空间的操作,也就是对本时间片的对应批次的数据的处理。
下面用实例来讲解数据处理过程。

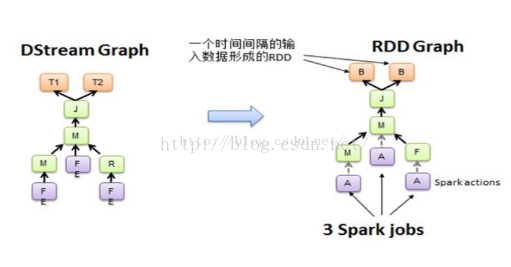
从Spark Streaming程序转换为Spark执行的作业的过程中,使用了DstreamGraph.
Spark Streaming程序中一般会有若干个对DStream的操作,DstreamGraph就是由这些操作的依赖关系构成。
本例中,从每个foreach开始,都会进行回溯,从后往前回溯这些操作之间的依赖关系,也就形成了DstreamGraph
执行从Dstream到RDD的转换,也就形成了RDD Graph,如下图所示:
新浪微博:http://www.weibo.com/ilovepains















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









