










1.解密Spark Streaming运行机制
2.解密Spark Streaming架构
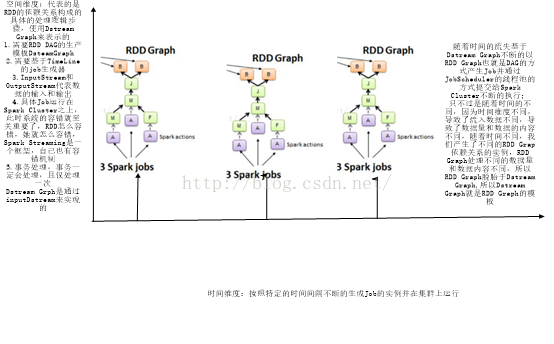
I.Spark Core是基于RDD形成的,RDD之间都会有依赖关系,Spark Streaming在RDD上的时间维度,DStream就是在RDD的基础之上加上了时间维度。DStream就是RDD的模板,随着时间的流逝不断地实例化DStream,以数据进行填充DStream Graph,静态的RDD DAG模板,这个模板就是DStream Graph,
II.基于DStream 的依赖构造成DStream Graph是RDD DAG的模板
Dstream是RDD的模板,随着DStream的依赖关系构成Dstream Graph
III.DStream是逻辑级别,RDD是物理级别
@transient
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]] ()
Dstrem就是在RDD的基础上加上了时间的维度所以整个SparkStreaming就是时空维度
DStream的compute需要传入一个时间参数,通过时间获取相应的RDD,然后再对RDD进行计算
|
| /** Method that generates a RDD for the given time */ def compute(validTime: Time): Option[RDD[T]] |
我们查看SparkStreaming的运行日志,就可以看出和RDD的运行几乎是一致的:

动态的job控制器会根据我们设定的时间间隔收集到数据,让静态的Dstream Graph活起来变成RDDGraph
如果数据处理不过来,就可以限流,Spark Streaming在运行的过程中可以动态地调整自己的资源,CPU















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









