






一、三种网络结构
1.前馈网络
前馈神经网络的信息朝一个方向传播,没有反向的信息传播,可以用一个有向无环图表示。前馈网络包括全连接前馈网络和卷积神经网络等。

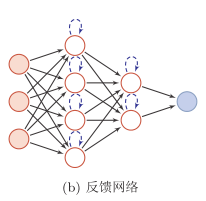
2.反馈网络
反馈网络中神经元不但可以接收其它神经元的信号,也可以接收自己的反馈信号。和前馈网络相比, 反馈网络中的神经元具有记忆功能, 在不同的时刻具有不同的状态。反馈神经网络中的信息传播可以是单向的,用一个有向循环图表示;也可以是双向传递,用无向图来表示。 反馈网络包括循环神经网络、 Hopfield网络、玻尔兹曼机。
为了增强记忆网络的记忆容量, 可以引入外部记忆单元和读写机制, 用来保存一些网络的中间状态,称为记忆增强网络(Memory-Augmented Neural Net-
work),比如神经图灵机[Graves et al., 2014]和记忆网络[Sukhbaataret al., 2015]等。
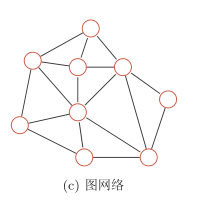
3.图网络
图网络是定义在图结构数据上的神经网络。
前馈网络和反馈网络的输入都可以表示为向量或向量序列。但实际应用中很多数据是图结构的数据,比如知识图谱、社交网络、分子(molecular )网络等。图网络中每个节点都一个或一组神经元构成。节点之间的连接可以是有向的,也可以是无向的。每个节点可以收到来自相邻节点或自身的信息。
图网络是前馈网络和记忆网络的泛化,包含很多不同的实现方式,比如图卷积网络(Graph Convolutional Network, GCN)[Kipf and Welling, 2016]、 消息传递网络(Message Passing Neural Network,MPNN)[Gilmer et al., 2017]等。
二、详细介绍-前馈神经网络

- L L L:表示神经网络的层数;一般只包括隐藏层和输出层。
- m ( l ) m^{(l)} m(l):表示第l层神经元的个数;
- f l ( ⋅ ) f_l(·) fl(⋅):表示l层神经元的激活函数;
- W ( l ) ∈ R m ( l ) × m l − 1 W^{(l)}∈R^{m^{(l)}×m^{l−1}} W(l)∈Rm(l)×ml−1:表示l − 1层到第l层的权重矩阵;
- b ( l ) ∈ R m l b^{(l)}∈ R^{m^l} b(l)∈Rml:表示l − 1层到第l层的偏置;
- z ( l ) ∈ R m l z^{(l)}∈ R^{m^l} z(l)∈Rml:表示l层神经元的净输入(净活性值) ;
- a ( l ) ∈ R m l a^{(l)}∈ R^{m^l} a(l)∈Rml:表示l层神经元的输出(活性值) 。
网络中信息传播公式:
z ( l ) = W ( l ) ⋅ a ( l − 1 ) + b ( l ) z^{(l)}=W^{(l)}·a^{(l-1)}+b^{(l)} z(l)=W(l)⋅a(l−1)+b(l)
a ( l ) = f l ( z ( l ) ) a^{(l)}=f_l(z^{(l)}) a(l)=fl(z(l))
二式合并:
z ( l ) = W ( l ) ⋅ f l − 1 z ( l − 1 ) + b ( l ) z^{(l)}=W^{(l)}·f_{l-1}z^{(l-1)}+b^{(l)} z(l)=W(l)⋅fl−1z(l−1)+b(l)
a ( l ) = f l ( W ( l ) ⋅ a ( l − 1 ) + b ( l ) ) a^{(l)}=f_l(W^{(l)}·a^{(l-1)}+b^{(l)}) a(l)=fl(W(l)⋅a(l−1)+b(l))
多层前馈神经网络也可以看成是一种特征转换方法
多层前馈神经网络也可以看成是一种特征转换方法,将输入
x
∈
R
d
x∈R^d
x∈Rd映射到输出
φ
(
x
)
∈
R
d
r
φ(x)∈R^{d^r}
φ(x)∈Rdr,其输出φ(x)作为分类器的输入进行分类。
如果分类器g(·)为Logistic回归分类器或softmax回归分类器,那么g(·)也可以看成是网络的最后一层,即神经网络直接输出不同类别的后验概率。
反之,Logistic 回归或 soft-max回归也可以看作是只有一层的神经网络。
对于两类分类问题y ∈ {0,1},并采用Logistic回归,那么Logistic回归分类器可以看成神经网络的最后一层。也就是说,网络的最后一层只用一个神经元,并且其激活函数为Logistic函数。网络的输出可以直接可以作为类别y = 1的后验概率。
p ( y = 1 ∣ x ) = a ( L ) p(y=1|x)=a^{(L)} p(y=1∣x)=a(L)
对于多类分类问题y ∈ {1,· · · , C},如果使用softmax回归分类器,相当于网络最后一层设置C 个神经元,其激活函数为softmax函数。网络的输出可以作为每个类的后验概率。
ˆ y = s o f t m a x ( z ( L ) ) ˆ y = softmax(z^{(L)}) ˆy=softmax(z(L))
参数学习:反向传播算法
梯度下降法需要计算损失函数对参数的偏导数,在神经网络的训练中经常使用反向传播算法来计算高效地梯度。
交叉熵损失函数:
L ( y , ˆ y ) = − y T ⋅ l o g ( ˆ y ) L(y, ˆy)=-y^T·log(ˆy) L(y,ˆy)=−yT⋅log(ˆy)
其中y ∈ {0,1}
C
为
^C为
C为标签y对应的one-hot向量表示。
L
(
y
,
ˆ
y
)
L(y, ˆy)
L(y,ˆy)对
W
W
W的偏导十分繁琐,先计算对
W
i
j
W_{ij}
Wij的偏导:
∂ L ( y , ˆ y ) ∂ W i j ( l ) = ( ∂ z ( l ) ∂ W i j ( l ) ) T ∂ L ( y , ˆ y ) ∂ z ( l ) \frac{∂L(y, ˆy)}{∂W_{ij}^{(l)}}=(\frac{∂z^{(l)}}{∂W_{ij}^{(l)}})^{T} \frac{∂L(y, ˆy)}{∂z^{(l)}} ∂Wij(l)∂L(y,ˆy)=(∂Wij(l)∂z(l))T∂z(l)∂L(y,ˆy)
L ( y , ˆ y ) L(y, ˆy) L(y,ˆy)对b的偏导:
∂ L ( y , ˆ y ) ∂ b ( l ) = ( ∂ z ( l ) ∂ b ( l ) ) T ∂ L ( y , ˆ y ) ∂ z ( l ) \frac{∂L(y, ˆy)}{∂b^{(l)}}=(\frac{∂z^{(l)}}{∂b^{(l)}})^T\frac{∂L(y, ˆy)}{∂z^{(l)}} ∂b(l)∂L(y,ˆy)=(∂b(l)∂z(l))T∂z(l)∂L(y,ˆy)
两个式子中的第二项是目标函数关于第l层的神经元z(l)的
偏导数, 称为误差项。
偏导数:
(1) ∂ z ( l ) ∂ W i j ( l ) = [ 0 ⋅ a j l − 1 ⋅ 0 ] = ∏ i ( a j ( l − 1 ) ) \frac{∂z^{(l)}}{∂W_{ij}^{(l)}}=\begin{bmatrix} 0\\ ·\\a_j^{}l-1\\·\\0\end{bmatrix}=∏_i(a_j^{(l-1)}) ∂Wij(l)∂z(l)=⎣⎢⎢⎢⎢⎡0⋅ajl−1⋅0⎦⎥⎥⎥⎥⎤=∏i(aj(l−1))
(2) ∂ z ( l ) ∂ b ( l ) = I m ( l ) \frac{∂z^{(l)}}{∂b^{(l)}}=I_m^{(l)} ∂b(l)∂z(l)=Im(l)
(3) 误差项: δ ( l ) = ∂ L ( y , ˆ y ) ∂ z ( l ) = f l ′ ( z ( l ) ) ⊙ ( ( W ( l + 1 ) ) T δ ( l + 1 ) ) δ^{(l)}=\frac{∂L(y,ˆy)}{∂z^{(l)}}=f'_l(z^{(l)})⊙((W^{(l+1)})^Tδ^{(l+1)}) δ(l)=∂z(l)∂L(y,ˆy)=fl′(z(l))⊙((W(l+1))Tδ(l+1))
第l层的误差项可以通过第l + 1层的误差项计算得到,这就是误差的反向传播。
可得
∂ L ( y , ˆ y ) ∂ W i j ( l ) = ∏ i ( a j ( l − 1 ) ) T δ ( l ) = δ i ( l ) a j ( l − 1 ) \frac{∂L(y, ˆy)}{∂W_{ij}^{(l)}}=∏_i(a_j^{(l-1)})^Tδ^{(l)}=δ_i^{(l)}a_j^{(l-1)} ∂Wij(l)∂L(y,ˆy)=∏i(aj(l−1))Tδ(l)=δi(l)aj(l−1)
可得
∂ L ( y , ˆ y ) ∂ W ( l ) = δ ( l ) ( a ( l − 1 ) ) T \frac{∂L(y, ˆy)}{∂W^{(l)}}=δ^{(l)}(a^{(l-1)})^T ∂W(l)∂L(y,ˆy)=δ(l)(a(l−1))T
∂ L ( y , ˆ y ) ∂ b ( l ) = δ ( l ) \frac{∂L(y, ˆy)}{∂b^{(l)}}=δ^{(l)} ∂b(l)∂L(y,ˆy)=δ(l)















 1361
1361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









