







文章目录
老铁们✌,重要通知🙌!福利来了!!!😉
【计算机视觉 复习流程剖析及面试题详解 】
【深度学习算法 最全面面试题(30 页)】
【机器学习算法 最全面面试题(61页)】
6.特征工程
特征工程分三步: ①数据预处理;②特征选择;③特征提取。

数据预处理有哪些方法?
数据预处理的方法主要包括去除唯一属性、处理缺失值、属性编码、数据标准化、特征选择(降维)
1.去除唯一属性:删除一些id属性;
2.缺失值处理的三种方法:
直接使用含有缺失值的特征;删除含有缺失值的特征(该方法在包含缺失值的属性含有大量缺失值而仅仅包含极少量有效值时是有效的);缺失值补全。
均值插补;利用同类均值插补;
极大似然估计: 常采用的计算方法是期望值最大化(EM),适用于大样本。
多重插补:思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值;估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。
插值法填充:包括随机插值,多重差补法,热平台插补,拉格朗日插值,牛顿插值等。
模型填充:使用回归、贝叶斯、随机森林、决策树等模型对缺失数据进行预测。
3.特征编码:
独热编码–采用N位状态寄存器来对N个可能的取值进行编码,每个状态都由独立的寄存器来表示,并且在任意时刻只有其中一位有效。
独热编码的优点:能够处理非数值属性;在一定程度上扩充了特征;编码后的属性是稀疏的,存在大量的零元分量。
4.数据标准化:

知乎:数据预处理剖析
6.1 特征选择
特征选择在于选取对训练数据具有分类能力的特征,可以提高决策树学习的效率。通常特征选择的准则是信息增益或信息增益率。
特征选择的划分依据:这一特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就应该选择这个特征。
(将数据集划分为纯度更高,不确定性更小的子集的过程)
6.1.1 什么是特征选择?为什么需要它?特征选择的目标?
指从已有的M个特征中选择N个特征使得系统的特定指标最优化,是从原始特征中选择出一些最有效特征以降低数据集维度的过程。
原因: ①减少特征数量、降维,使模型泛化能力更强,减少过拟合;
②增强对特征和特征值之间的理解。
目标:选择离散程度高且与目标的相关性强的特征。
6.1.2 有哪些特征选择技术?
①过滤法
按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,从而选择特征;
②包装法
根据目标函数(通常是预测效果评分),每次选择若干特征或者排除若干特征;常用方法主要是递归特征消除法。
③嵌入法
先使用ML的算法和模型进行训练,得到各个特征的权重系数,根据系数从大到小选择特征;常用方法主要 是基于惩罚项的特征选择法。

过滤式选择:该方法先对数据集进行特征选择,然后再训练学习器。特征选择过程与后续学习器无关。Relief是一种著名的过滤式特征选择方法。
包裹式选择:该方法直接把最终将要使用的学习器的性能作为特征子集的评价原则。其优点是直接针对特定学习器进行优化,因此通常包裹式特征选择比过滤式特征选择更好,缺点是由于特征选择过程需要多次训练学习器,故计算开销要比过滤式特征选择要大得多。
嵌入式选择
常见的降维方法:SVD、PCA、LDA
6.2 特征提取
常见的降维方法除了基于L1惩罚项的模型以外,另外还有PCA和LDA,
本质是要将原始的样本映射到维度更低的样本空间中,
但是它们的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;
而LDA是为了让映射后的样本有最好的分类性能。
6.3 特征选择 vs 特征提取
都是降维的方法。
特征选择:不改变变量的含义,仅仅只是做出筛选,留下对目标影响较大的变量;
特征提取:通过映射(变换)的方法,将高维的特征向量变换为低维特征向量。
6.4为什么要处理类别特征?怎么处理?
除了决策树等少量模型能直接处理字符串形式的输入,对于LR,SVM等模型来说,类别特征必须经过处理转化成数值特征才能正常工作。方法主要有:
序号编码;独热编码;二进制编码
6.5 什么是组合特征?
为了提高复杂关系的拟合能力,在特征工程中经常会把一阶离散特征两两组合,构成高级特征。例如,特征a有m个取值,特别b 有n个取值,将二者组合就有m*n个组成情况。这时需要学习的参数个数就是 m×n 个。
6.6 怎么有效地找到组合特征?
可以用基于决策树的方法,首先根据样本的数据和特征构造出一颗决策树。然后从根节点都叶节点的每一条路径,都可以当作一种组合方式。
6.7 如何处理高维组合特征?
当每个特征都有千万级别,就无法学习 m×n 规模的参数了。
解决:可以将每个特征分别用 k 维的低维向量表示,需要学习的参数变为 m×k+n×k 个,等价于矩阵分解
6.8 如何解决数据不平衡问题?
主要是由于数据分布不平衡造成的。
解决方法如下:
1.采样,对小样本加噪声采样,对大样本进行下采样
2.进行特殊的加权,如在Adaboost中或者SVM中
3.采用对不平衡数据集不敏感的算法
4.改变评价标准:用AUC/ROC来进行评价
5.采用Bagging/Boosting/ensemble等方法
6.考虑数据的先验分布
6.9 数据中有噪声如何处理?
噪声检查中比较常见的方法:
(1)通过寻找数据集中与其他观测值及均值差距最大的点作为异常
(2)聚类方法检测:将类似的取值组织成“群”或“簇”,落在“簇”集合之外的值被视为离群点。
在进行噪声检查后,通常采用分箱、聚类、回归、计算机检查和人工检查结合等方法“光滑”数据,去掉数据中的噪声。
采用分箱技术时,需要确定的两个主要问题就是:如何分箱以及如何对每个箱子中的数据进行平滑处理。
分箱的方法:有4种:等深分箱法、等宽分箱法、最小熵法和用户自定义区间法。
数据平滑方法
按平均值平滑 :对同一箱值中的数据求平均值,用平均值替代该箱子中的所有数据。
按边界值平滑:用距离较小的边界值替代箱中每一数据。
按中值平滑:取箱子的中值,用来替代箱子中的所有数据。
6.10 FM
基于矩阵分解的机器学习算法,用于解决数据稀疏的业务场景(如推荐业务),特征怎样组合的问题。
如:一个广告分类的问题为例,根据用户与广告位的一些特征,来预测用户是否会点击广告。
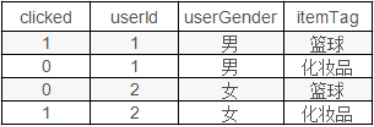
对于CTR点击的分类预测中,有些特征是分类变量,一般进行one-hot编码。
One-hot会带来数据的稀疏性,使得特征空间变大。
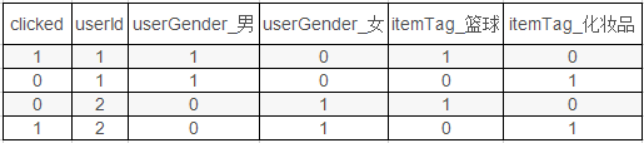
6.10.1 SVM vs FM
1.SVM的二元特征交叉参数是独立的,而FM的二元特征交叉参数是两个k维的向量vi、vj,交叉参数就不是独立的,而是相互影响的。
2.FM可以在原始形式下进行优化学习,而基于kernel的非线性SVM通常需要在对偶形式下进行。
3.FM的模型预测与训练样本独立,而SVM则与部分训练样本有关,即支持向量。
6.11 FFM
FM在FM的基础上进一步改进,在模型中引入类别(field)的概念。将同一个field的特征单独进行One-hot,因此在FFM中,每一维特征都会针对其他特征的每个field,分别学习一个隐变量,该隐变量不仅与特征相关,也与field相关。
FFM中每一维特征都归属于一个特定和field,field和feature是一对多的关系:
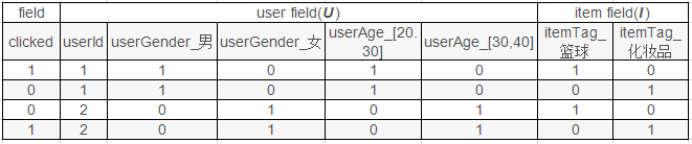
实现FM & FFM的最流行的python库有:LibFM、LibFFM、xlearn和tffm
名词解释: 点击率CTR 转化率CVR

















 1535
1535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











