







文章目录
老铁们✌,重要通知🙌!福利来了!!!😉
【计算机视觉 复习流程剖析及面试题详解 】
【深度学习算法 最全面面试题(30 页)】
【机器学习算法 最全面面试题(61页)】
8.KNN
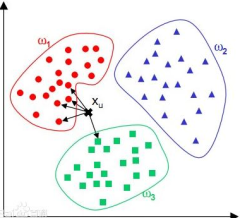
8.1 简述一下KNN算法的原理?
利用训练数据集对特征向量空间进行划分。KNN算法的核心思想是在一个含未知样本的空间,可以根据样本最近的k个样本的数据类型来确定未知样本的数据类型。 该算法涉及的3个主要因素是:k值选择,距离度量,分类决策。
8.2 如何理解kNN中的k的取值?
在应用中,k值一般取比较小的值,并采用交叉验证法进行调优。
8.3 在kNN的样本搜索中,如何进行高效的匹配查找?
线性扫描(数据多时,效率低) 构建数据索引——Clipping和Overlapping两种。前者划分的空间没有重叠,如k-d树;后者划分的空间相互交叠,如R树。(对R树了解很少,可以之后再去了解)
8.4 KNN算法有哪些优点和缺点?

8.5 不平衡的样本可以给KNN的预测结果造成哪些问题,有没有什么好的解决方式?
输入实例的K邻近点中,大数量类别的点会比较多,但其实可能都离实例较远,这样会影响最后的分类。
可以使用权值来改进,距实例较近的点赋予较高的权值,较远的赋予较低的权值。
8.6 为了解决KNN算法计算量过大的问题,可以使用分组的方式进行计算,简述一下该方式的原理。
先将样本按距离分解成组,获得质心,然后计算未知样本到各质心的距离,选出距离最近的一组或几组,再在这些组内引用KNN。
本质上就是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本,该方法比较适用于样本容量比较大时的情况。
8.7 如何优化Kmeans?
使用Kd树或者Ball Tree :将所有的观测实例构建成一颗kd树,之前每个聚类中心都是需要和每个观测点做依次距离计算,现在这些聚类中心根据kd树只需要计算附近的一个局部区域即可。
8.8 在k-means或kNN,我们是用欧氏距离来计算最近的邻居之间的距离。为什么不用曼哈顿距离?
曼哈顿距离只计算水平或垂直距离,有维度的限制。另一方面,欧氏距离可用于任何空间的距离计算问题。
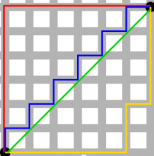
绿色的线为欧式距离的丈量长度,红色的线即为曼哈顿距离长度,
蓝色和黄色的线是这两点间曼哈顿距离的等价长度。
欧式距离:两点之间的最短距离;
曼哈顿距离:投影到坐标轴的长度之和;又称为出租车距离.
切比雪夫距离:各坐标数值差的最大值;
8.9 参数说明以及调参
n_neighbors:邻居节点数量
weights:设为distance(离一个簇中心越近的点,权重越高);
p=1为曼哈顿距离, p=2为欧式距离。默认为2
leaf_size:传递给BallTree或者KDTree,表示构造树的大小,默认值是30
n_jobs:并发执行的job数量,用于查找邻近的数据点。默认值1,选取-1占据CPU比重会减小,但运行速度也会变慢。


















 3643
3643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











