





心理压力是影响人类生理与病理生理的主要因素,与多种疾病相关,如自身免疫疾病、代谢综合征、睡眠障碍及自杀倾向和意念。因此,及早检测和管理慢性压力对预防多种疾病至关重要。人工智能(AI)和机器学习(ML)推动了生物医学多个领域的范式转变,包括疾病诊断、监测与预后。本文旨在介绍AI和ML在解决与心理压力相关的生物医学问题中的一些应用。我们提供了来自先前研究的多项证据,显示AI和ML能够以约90%的准确率预测压力并检测大脑的正常状态与异常状态(尤其是创伤后应激障碍(PTSD))。值得注意的是,除非未来的分析技术更多地关注通过这些技术检测长期心理困扰,而不仅仅是评估压力暴露本身,否则应用AI/ML技术识别普遍存在的压力暴露可能无法充分发挥其潜力。
展望未来,我们提出一种名为群智能(SI)的新型AI方法子类别可用于检测压力与PTSD。SI涉及集成学习技术,能有效解决诸如压力检测等复杂问题,尤其适用于临床环境,如隐私保护等方面。我们认为,将AI和ML方法应用于预测和评估压力水平,将对医疗界及患者群体产生积极影响。最后,我们鼓励开展更多研究,在不远的将来将AI和ML纳入临床诊断的标准实践。本文发表在Molecular Psychiatry杂志。
引言
压力被定义为“由于令人不安的状况而产生的心理紧张或压力状态” 。长期或慢性暴露于压力环境是发病的重要因素,并且是导致死亡的主要原因之一。原则上,慢性压力可分为躯体性压力(如烧伤)和心理压力。在Walter Cannon和Hans Selye的研究之后,慢性压力及其影响的研究领域不断扩展。对应激刺激的反应依赖于复杂的脑网络,需要功能完备的神经解剖处理,以检测并判断某事件是否对人类构成潜在威胁。然而,应激障碍的诊断和治疗难点在于系统的复杂性,以及不同压力源可触发脑网络中不同结构这一事实。
压力是遗传易感个体出现多种急性和慢性躯体及心理障碍的重要危险因素。慢性压力(躯体或心理)诱发的疾病包括炎症性疾病(如自身免疫疾病、过敏性疾病,或因糖皮质激素系统与白细胞介素-6相互作用而引发的疾病)、代谢疾病(糖尿病、心血管疾病、高血压、肥胖)、神经退行性疾病(如阿尔茨海默病)、精神疾病和心理障碍(如创伤后应激障碍、精神分裂症、抑郁症、惊恐发作、焦虑、执行或认知功能障碍)。值得注意的是,有研究表明,压力可能在无精神病遗传易感的健康个体中介导或增强精神病样症状,这些结果基于单核苷酸多态性研究所得的多基因风险评分。此外,根据多基因风险模型,复杂且多因素疾病的疾病表型表达需要风险因素的累积及/或保护因素的缺失。因此,在压力暴露显著的情况下,即使遗传风险变异较低的个体也可能表现出精神病症状。
压力与多种疾病的相关性促使人们致力于早期检测和治疗以避免长期并发症及疾病的发展。压力的多因素起源以及涉及脑网络的复杂性,促使临床医生应用AI和ML方法,通过克服传统方法的局限性来检测和量化压力水平。一方面,这两种方法的目的相同,即通过创建最小的误差平方和来提高准确性。另一方面,AI和ML方法可分析高维数据,应用非线性过程,并基于试错方法提高其准确性,但产生计算负担,而传统方法(如统计方法)处理较低维数据,应用线性过程,使用未经训练的数据和决策树或条件规则(如传统编程)预测结果的可能性。
检测压力相关表型、症状与疾病之间的关联并不容易,一个原因是在自然条件下难以准确测量压力。例如,压力诊断和预测结果的困难之一是人类健康构成非线性系统,输出信号与输入信号变化不成比例[。由于压力检测是一个非线性问题,近年来许多研究人员和科学家主要关注应用AI和ML来识别显著信号并预测压力的后续后果;因此,在下文中AI和ML在此背景下将互换使用。根据压力相关的ML研究的集体发现,这些方法在预测患者压力结果(尤其是PTSD)方面具有巨大潜力。例如,这些方法可以将PTSD患者根据特定的表观遗传生物标志物划分为亚群,或评估皮质醇水平如何预测PTSD。此外,多种压力源的存在可能混淆与PTSD及其他精神疾病之间的关联。这些压力源可以是单次、重复或慢性的;涉及不同情境(如车祸、创伤或童年虐待);既可能是因果性的,也可能是情境依赖的。
广义上讲,AI和ML方法可解决的问题包括:a)压力检测问题(即压力水平及其生物物理测量);b)适应不良压力反应后的疾病状态(即应激刺激消退后的行为或生理差异);以及c)分类问题(即不同压力类别及外部刺激的分类)。然而,与普遍存在的压力暴露不同,长期压力或适应不良的压力(即心理困扰)扰乱了生理稳态,导致压力反应系统即使在压力刺激消退后也可能持续低活化或高活化状态。本文批判性地回顾并评估了应用于检测压力及压力相关疾病(而非慢性压力长期或过度效应)的AI和ML方法。我们深入介绍了多种不同的AI技术示例,说明AI和ML如何帮助临床医生诊断、预测和缓解压力及相关健康问题,尤其是与PTSD相关的特征。特别地,由于预测问题的非线性特性,贝叶斯网络、支持向量机(SVM)、随机森林(RF)和人工神经网络(ANN)等ML方法在本文中受到特别关注。我们还提出一种名为群智能(SI)的AI方法子类,能够用于未来压力和PTSD检测方法的开发。本文最后还讨论了目前关于AI、ML与压力之间关联研究的局限性。
基于人工智能的方法
人工智能(AI)指的是利用计算机执行通常需要人类智能的任务。最近几十年,我们观察到了一系列机器学习(ML)方法的出现,这些方法是实现AI的一整套技术。机器学习最初受到人类学习和推理行为的启发。机器学习方法主要分为两个类别:a)监督学习,即对每个输入的训练数据产生一个输出类别(“标签”);b)无监督学习,即输入的训练数据没有相应的输出标签。在监督学习中,机器学习模型接收一个训练数据集,用于训练模型,然后在独立的数据集中预测已训练的结果。例如,对于压力检测问题,以监督方式训练模型并进行推理是相关的;而对于分类问题,可以采用无监督方式将高维特征空间划分为不同的压力类别。有了机器学习技术,临床医生便拥有了一个优雅的工具,能够将人类大脑中的压力状态与其他状态清晰地区分开来。
更广泛地说,机器学习方法已被广泛探讨其在生物医学领域的应用,包括神经科学。尽管机器学习在由患者经历、环境以及应激刺激所塑造的精神疾病(例如双相情感障碍)中的重要性,与其他精准医疗方法相比尚未被充分认识(关于精准医疗的回顾,请参见引文[46]),然而近年来,机器学习方法在这一领域的应用呈现指数级增长。值得注意的是,这一趋势的加速还源于生物传感器数据、分子谱数据以及遗传信息的大量积累。尽管如此,这些方法并非毫无挑战,其中包括内在挑战(例如算法偏差)和外部因素(例如人为操控),其进一步描述已超出本文范围(有关综述请参阅引文[52])。
数据和预处理
存在多种数据类型可用于检测和理解压力状况。选择合适的机器学习算法很大程度上取决于可用的数据类型。最易测量的生理数据包括心率、心率变异性(HRV)、呼吸频率和身体运动。诸如心电图(ECG)、脑电图(EEG)和磁共振成像(MRI)等研究技术则可提供更为详细的信息,这些数据通常是在临床过程中采集的。当不同模式下的多种类型数据合并时,被称为“多模态数据”。这些数据可通过将不同类型数据的特征提取到共享的输入空间(然后输入到所有典型的监督学习算法中)进行处理,也可使用更复杂的模型,例如图神经网络。例如,多视图学习是一种机器学习框架,将数据模态视为所研究现象的不同“视图”,并为给定任务统一处理这些视图。同样地,多模态融合是一种深度学习技术,将各个模态融合成整体表征供机器学习模型使用。值得一提的是,生理数据通常产生含有噪声的信号,需要采用预处理方法来清洁这些信号;例如,EEG信号在记录时经常受到环境噪声污染。因此,通常采用不同类型的低频和高频滤波器以降低噪声。
在尽量减少数据缺失(如缺失数值)的情况下采集和分析大量样本,对于提高分类器或预测模型的效率与性能至关重要。数据样本在应用机器学习技术时具有重要作用,因为每个样本包含多个特征或属性,这些特征或属性又可能导致不同的目标、标签、类型或数值。
在分类或预测之前或过程中,一些重要的步骤包括异常值去除、标准化、特征选择、降维和特征提取。然而,在某些情况下,“特征选择”可以成为机器学习模型的一部分。例如,在人工神经网络中,模型会自动学习提升重要特征的权重,同时降低不相关特征的权重。特征选择是指选取最重要的变量并删除其中不相关的特征。统计和机器学习技术通常用于提取有效特征并作为分类器的输入。在一些研究中,采用了一种称为主成分分析(PCA)的技术,该技术可识别将多个特征组合成为一个特征。PCA是一种降维方法,是一种无监督学习。虽然一些研究指出统计输入特征对分类器检测压力有效,但其他研究则认为非线性和频谱特征(如傅里叶变换)更为有效。值得注意的是,有些方法同时应用非线性、统计和频谱特征,并在最后应用特征选择技术,以提取最佳特征集。此外,深度学习方法,例如人工神经网络模型,也可用于学习特征重要性的非线性关系。例如,自动编码器可用作机器学习流程的预处理步骤,执行非线性降维,以提取对监督任务最相关的特征组合,例如分类[63]和预测压力反应[64]。
去噪(移除噪声)或数据白化(如零相位成分分析白化变换)可以去除特征之间的相关性,使输入数据更少冗余,同时保留原有维度。在特征提取过程中,从原始特征集中生成一组新的特征,以捕捉数据中所有重要信息。一些机器学习模型,如基于随机森林的方法,使用评分方法对特征重要性进行量化,即通过去除特定特征后观察预测误差的增加来确定其重要性。
图1展示了机器学习进行数据分类(例如用于检测压力水平)的通用流程图,包括如下步骤:原始数据输入、标准化与异常值去除、训练/测试/验证集划分、训练与测试机器学习模型(特征选择)以及对未见数据的推理过程。
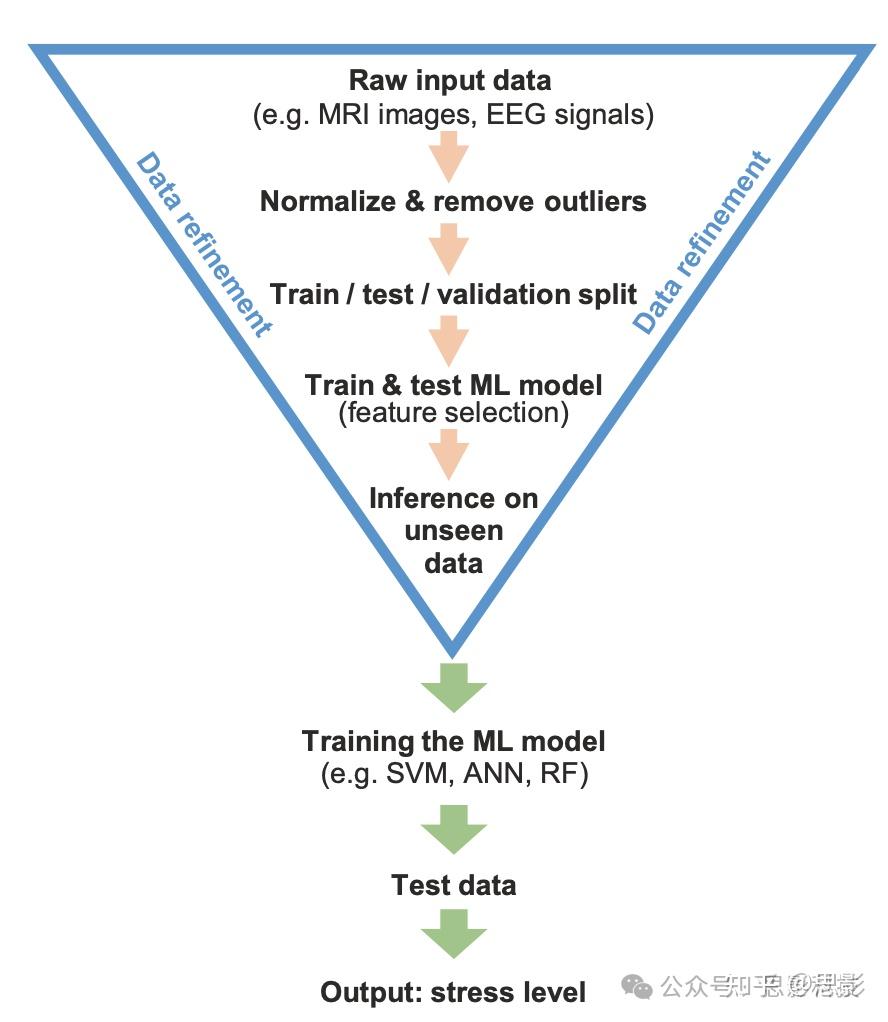
图1:基于生理信号的数据分类通用流程图。(图中蓝色三角形表示数据的精细化过程)
模型选择
存在多种机器学习算法可用于对压力水平和创伤后应激障碍(PTSD)进行分类与预测。这些方法包括分类算法,如逻辑回归、朴素贝叶斯、支持向量机、贝叶斯推断模型、人工神经网络以及随机森林算法。相对较新的深度学习方法则包括卷积神经网络(CNN)和自然语言处理(NLP)技术。然而,“天下没有免费的午餐”定理指出,不存在一种万能的机器学习方法适用静所有问题;例如,神经网络并非在所有预测问题中都表现最优。因此,为了用机器学习解决任何特定问题,研究者需要尝试多种不同的方法,并根据评价指标来选择最合适的方法,例如分类任务中的曲线下面积(AUC),或回归任务中的均方误差(MSE)(更多讨论参见“框1”)。
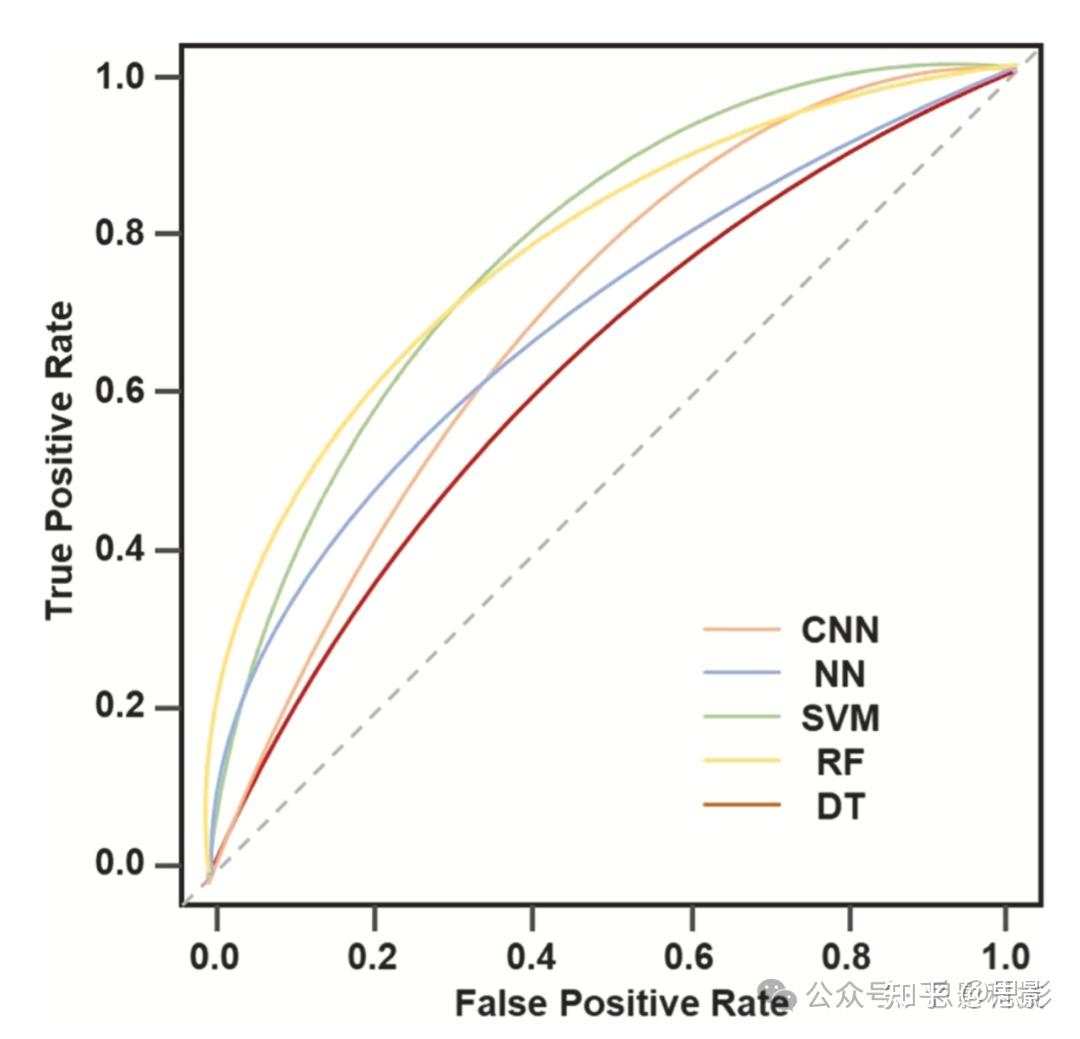
图2:受试者工作特征(ROC)曲线示例;曲线下面积(AUC)用于衡量模型性能。数值表示每种机器学习方法的假阳性和假阴性率假设值。
选择合适模型时需要考虑的一个因素是计算复杂性。模型复杂性越高,所需的训练和推理计算资源也就越多。当需要快速从机器学习模型中得到推理结果时,计算复杂性高的模型就不太合适;不过,在压力检测相关的机器学习应用中,很少出现这种高时间敏感度的情况。此外,有时适合采用组合模型而非单一模型。这种组合方法称为“集成学习(ensembling)”,通常是通过加权多个模型的输出,得到最终单一的预测结果。这种方法通常可以轻松地使用常见的程序库(例如R语言的h2o包)或无代码工具(例如JADBio)来实现[。
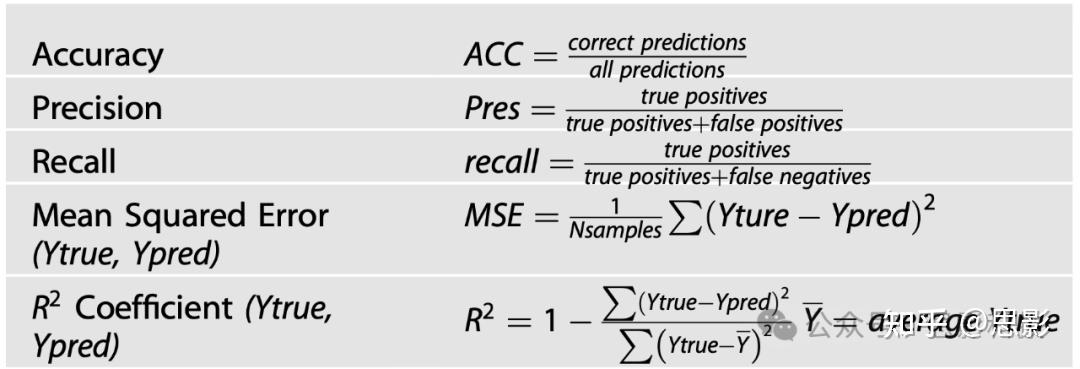
有多种由机器学习得出的指标可用来评估模型性能,并用于选择表现最优的模型(表1)。基于人工智能的方法最终目的是提高模型的准确率(accuracy)、精确率(precision)、召回率(recall)、预测能力以及模型决定系数等,同时尽可能降低代价函数,例如均方误差(MSE)和假阳性率(false positive rate)。当经过训练的机器学习模型能将所有样本正确地预测到相应组别时,准确率会提高。例如,若定义压力患者类为“0”,无压力患者类为“1”,则准确率为100%的机器学习分类器应能正确识别所有“0”和“1”所属的类别。需注意以下几点:
a) 当分类器发生错误分类时,准确率会不利地降低;
b) 当模型预测为有压力患者(假设为类“1”)的样本全部实际属于类“1”时,精确率会提高;
c) 当模型能正确预测出所有真正有压力的患者时,召回率则会提高。
例如,假设用机器学习模型预测400名患者的压力状况,其中200名患者实际有压力,200名没有。如果模型预测其中100名患者有压力,但在这100名预测有压力的患者中只有70名实际确实有压力,则此时精确率为0.7(即70/100),召回率则为0.35(即70/200)。
表1:智能方法性能评估指标
逻辑回归算法(Logistic regression algorithm)
逻辑回归算法广泛应用于二元分类,它可以计算事件发生的概率;例如,用于评估个体是否存在压力或非压力相关行为的概率。在一项研究中,作者开发了一种非侵入式的可穿戴设备,个体可在日常生活中佩戴,用于测量生理信号,并自动检测压力状态。该系统首先去除信号噪声,然后从信号中提取特征,包括平均振幅、刺激响应延迟、标准差、均方根(RMS)和恢复峰值时间。随后,作者使用支持向量机(SVM)、逻辑回归(LR)、多层感知机(MLP)和随机森林(RF)对处理后的数据集进行训练,并在两个实验组中进行了测试:
a) 第一组测量了心率和皮肤电活动(EDA),利用这些信号对“压力”与“非压力”状态进行分类;b) 第二组(压力与情境组)则在测量上述活动基础上增加了加速度传感器信号,同时结合个体活动信息进行分类。
逻辑回归在第一组(仅压力)中预测压力的准确率约为92%,而在第二组(压力与情境)中的准确率约为90%。表2展示了机器学习算法(例如针对心率变异性HRV)所使用的信号特征提取示例。
表2:从心率变异性中提取用于压力检测的特征示例(基于文献[68])

朴素贝叶斯算法(Naïve Bayes algorithm)
朴素贝叶斯(NB)分类器基于贝叶斯定理,假设待考察的所有特征之间相互独立。NB是一种监督学习算法,将类别标签分配给训练数据集中代表特征值的每个样本。NB算法快速、简单,相比逻辑回归等模型,NB收敛速度更快(更多讨论参见文献[69])。此外,NB模型不表达复杂行为,且不易过拟合数据。在一项研究中,作者测量了心率均值、标准化HRV、平均呼吸频率、低频功率(LF)、高频功率(HF)以及HRV功率比值等输入特征,这些生理参数是在认知压力测试期间测得的,并使用NB对数据集进行压力检测。结果表明,NB模型区分有压力与无压力个体的准确率约为80%。
支持向量机(SVM)
支持向量机(SVM)是一种监督学习模型,使用输入数据特征的非线性变换(而不是只涉及乘法的线性变换)。SVM通过“核函数”(kernel functions)实现这一点,例如线性核、径向基函数(RBF)核和多项式核,能够高效地进行非线性变换。由于SVM灵活的核函数特性,使得它特别适合于非线性模式识别问题,从而被广泛用于压力水平检测中。图3展示了SVM分类压力与非压力群体的通用原理图(示意情境,圆圈代表有压力者,三角形代表无压力者),使用的是线性核函数。
在一项利用脑电图(EEG)信号进行压力诊断的SVM研究中,作者采用了鲸鱼优化算法(Whale Optimization Algorithm)对SVM使用的核函数进行优化,用于检测14名受试者的压力水平(压力水平通过问卷定义)。研究结果显示,这一方法实现了约96%的高准确率,突显了SVM算法在精神科医生及心理健康专业人士进行诊断工作时的潜在应用价值。
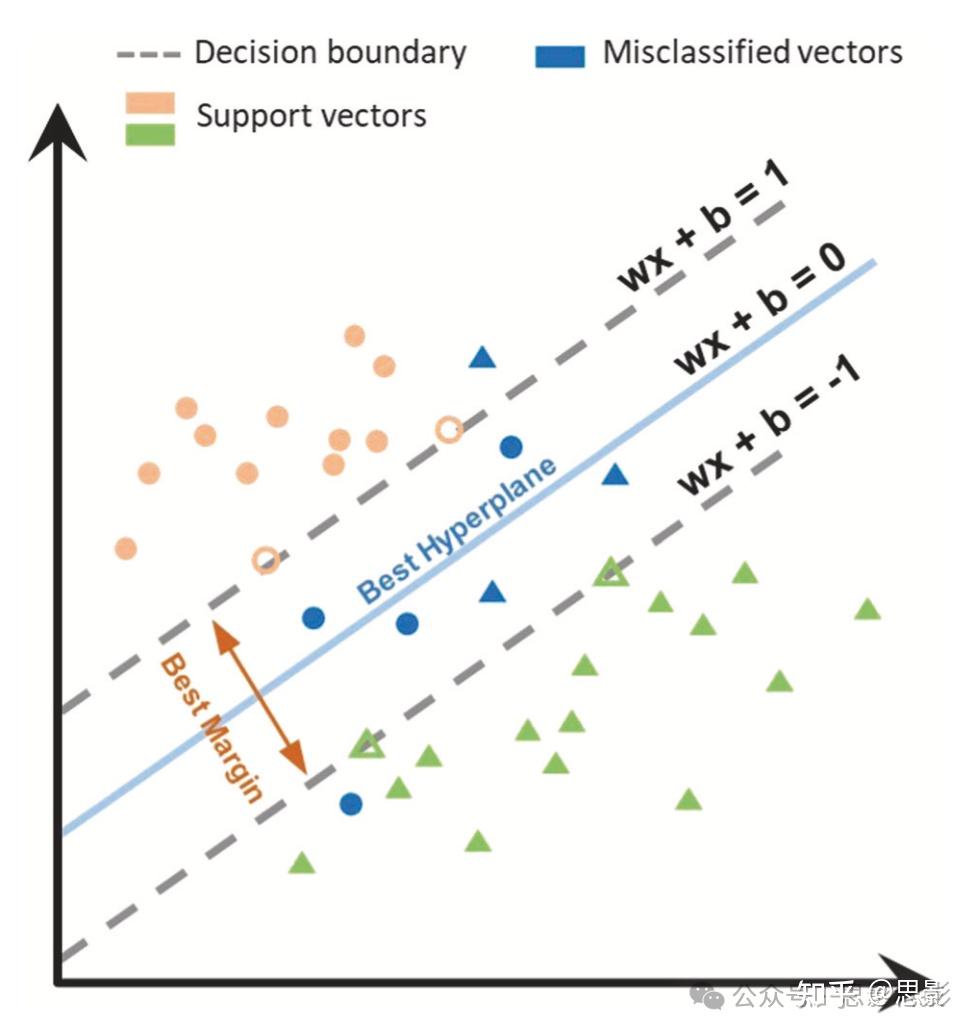
图3:支持向量机(SVM)与线性核函数示意图
在该示意情境中,位于超平面wx+b=1wx + b = 1wx+b=1 上方的圆圈表示第一组(有压力的个体),位于wx+b=−1wx + b = -1wx+b=−1 下方的三角形表示第二组(无压力的个体)。最佳间隔(Best margin)表示两个超平面之间的最佳区分距离。最佳超平面则指最大化距离最近数据点与超平面之间距离(即间隔)的超平面。
在此背景下,研究人员开发了一种基于SVM的方法,通过脑电图(EEG)记录所得的模式来识别正在经历压力的个体。值得注意的是,脑电图与心电图(ECG)是用于机器学习方法评估认知功能及其与压力关系的数据来源(如前所述)。在采集EEG信号并使用带通滤波器去除伪迹(artifacts)后,这些信号随后被转换至频域。其他研究也证实了SVM模型在压力检测方面具有良好的表现。一项研究中,作者基于EEG信号的统计特征生成数据集。值得注意的是,其他研究也观察到了机器学习模型在识别EEG信号提取特征与压力之间非线性关系方面的有效性。
随机森林算法(Random Forest Algorithm)
决策树(DT)是一种简单的算法,通过根据输入变量的某一截断值(cut-off value)对数据集进行迭代式划分,直至所有输入数据被归入合适的类别(在本综述的背景下,通常为“压力”与“非压力”两类)。随机森林(RF)算法通过构建多个决策树来实现,每个决策树都是基于训练数据的一个特征子集。最终的随机森林模型是所有树的预测表现的平均值。随机森林算法的主要优点之一在于它避免了过拟合(overfitting),因为其功能建立在特征子集和结果平均化的基础之上。此外,随机森林算法还可以通过用平均值替代缺失值来处理数据缺失问题。RF还具备确定每个特征重要性并从中选择最重要特征的能力。
在一项分析驾驶引起压力的研究中,作者利用随机森林从驾驶员生理功能变量中选择特征,以识别驾驶员的压力水平。研究中使用便携式传感器捕获驾驶员在多个城市路线驾驶时的生理变化,测量指标包括足部和手部的皮肤电活动(EDA)、心率及呼吸状态等多种生理测量值。这些特征的提取采用了一种范围校正(range correction)方法[78]。研究者使用基于随机森林的递归特征消除(Recursive Feature Elimination),发现呼吸状态、足部与手部EDA是确定驾驶员压力水平最显著的特征。
贝叶斯推断模型(Bayesian inference models)
贝叶斯推断模型属于贝叶斯概率模型家族,这类模型已广泛应用于机器学习领域。特别是,由于贝叶斯方法在分析数据序列方面表现突出,因此广泛应用于现实问题中。例如,贝叶斯结构时间序列模型(Bayesian structural time-series model)与因果影响模型(Causal Impact model)可基于时间序列数据评估某项干预的影响与有效性,而不仅仅是干预的时间点。值得注意的是,这种通用框架适用于任意纵向数据;例如,数据来源可包括可穿戴生物传感器(相关应用请参见文献[81])。
贝叶斯推断模型在机器学习领域得到了广泛应用。尤其由于它们在分析序列数据方面的强大能力,这类模型已被应用于许多现实问题中。时间序列数据通常被分割为干预(即引发压力的事件)之前和之后两个阶段,模型在先验数据(priors)上进行训练,并利用后验数据(posteriors)推断事件的影响。
值得注意的是,这种通用框架适用于任何类型的纵向数据;例如,这些数据可涵盖非常广泛的数据来源,从环境或气候数据、犯罪数据,甚至到可穿戴生物传感器相关的数据(后者的应用实例参见文献[81])。在这种情况下,这种贝叶斯方法能够应用于心理健康领域的压力分析,例如评估各种外部刺激对患者或个体(尤其是那些经历高压力状态的个体)的影响程度。每位患者(或个体)对于相同的压力刺激可能表现出不同的耐受性,模型可通过对可穿戴传感器数据进行建模,评估这种个体化的影响
人工神经网络(Artificial Neural Networks, ANN)
人工神经网络(ANN)是一种高级的机器学习工具,其构想来源于人类的学习行为。人工神经网络本质上是一个多层感知器网络,类似于人类的大脑学习机制。学习过程基于数学函数,以确定每个连接的权重。典型的前馈式(feedforward)ANN结构包括输入层、隐藏层和输出层。在一些情况下,如果网络包含不止一个隐藏层,则被称为深度神经网络(DNN)。图4a和4b分别展示了单层神经网络与深度神经网络的结构。特别地,卷积神经网络(CNN)是一种专门用于图像分析的人工神经网络。CNN应用卷积“滤波器”,以计算高效的方式考虑输入图像中不同像素之间的空间关系。非线性方法(例如自动编码器,autoencoder)能更有效地建模生物反应中经常出现的复杂非线性现象,但代价是降低了解释性。
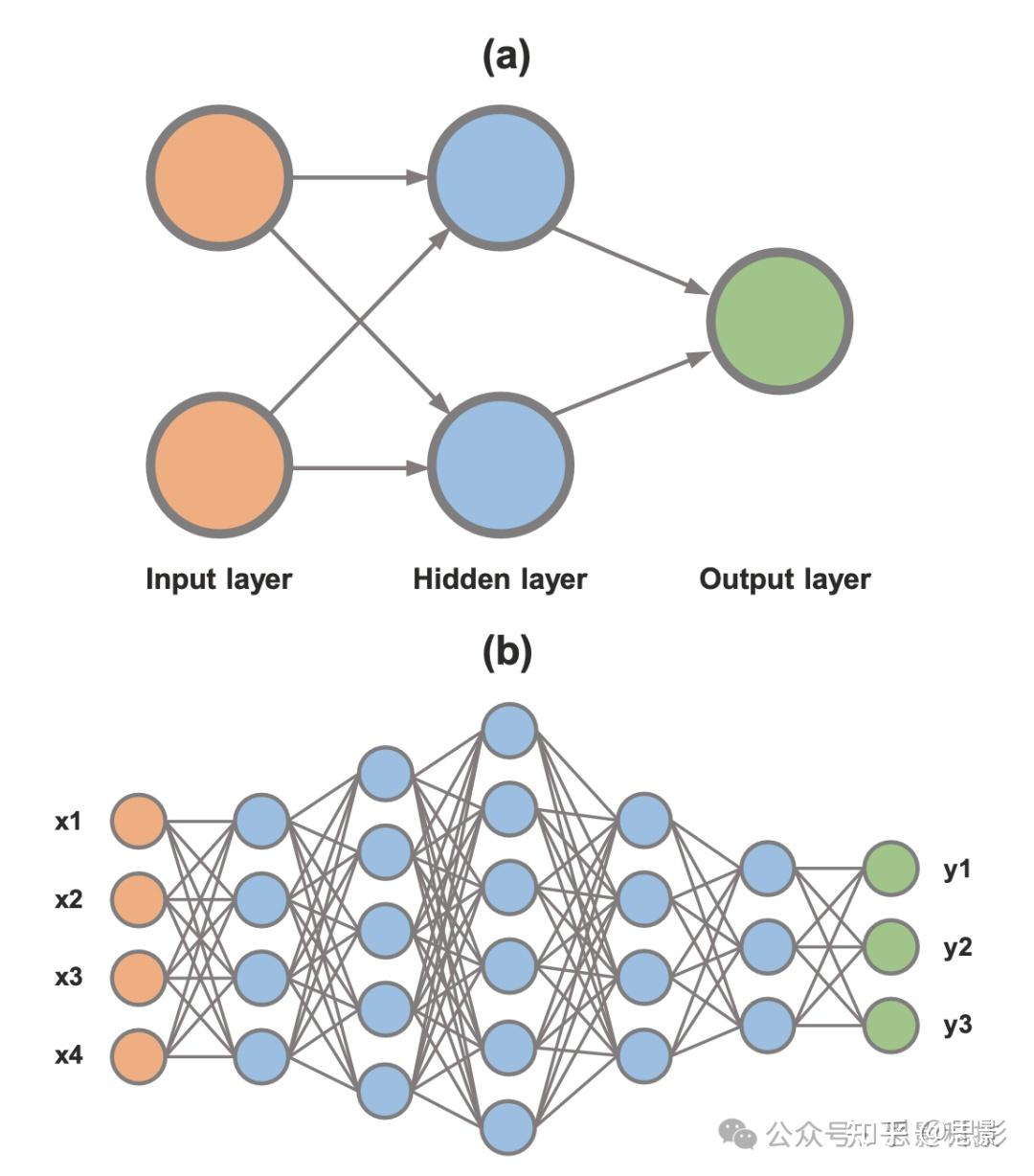
图4:简单神经网络与深度神经网络示意图
a) 简单神经网络;b) 深度神经网络(基于文献[76]内容修改)。输入层、隐藏层和输出层节点分别以浅灰、中灰和深灰色表示。特征值用x1、x2、x3和x4表示,输出值则用y1、y2和y3表示。 在最近的一项研究中,作者提出一种基于CNN的方法,通过ECG记录进行压力检测。CNN特别适合这一任务,因为它们可以分析ECG波形,而ECG波形的当前时刻与之前时刻之间的空间关系非常重要。研究人员采集了130名学生在口试期间的ECG记录,并从记录中提取重要统计特征,如HRV信号的时域特征。结果表明,CNN检测压力的准确率达到约97%。CNN中的隐藏层负责分析特征之间的非线性关系,使CNN在压力和PTSD检测中具有强大的性能。
CNN的实用性也在另一项研究中得到证实,该研究分析了用于压力水平检测的呼吸热成像。Cho等人利用热成像相机采集人们呼吸时的热图像。经过图像预处理、生成光谱序列和训练后,CNN对压力水平检测的准确率约为80%。因此,人工神经网络在预测压力状况方面表现良好。未来,这类方法可以进一步应用到可穿戴设备(如智能手表)进行压力检测,遵循类似的技术路径,这些设备可记录ECG和可能的血氧饱和度(SpO2)信息,以实现实时压力水平检测。
| 框1 机器学习评价指标示例1.1 受试者工作特征曲线(ROC曲线) 受试者工作特征曲线(ROC曲线)是一种信息丰富的图形方法,用于评估机器学习工具在将数据分类为二元类别(例如患者是否有压力)时的性能表现。ROC曲线定义为假阳性率(False Positive Rate)与真阳性率(True Positive Rate)之间的图形关系,其中阈值介于“0”与“1”之间(示例参见图2)。ROC曲线下面积(AUROC)用来度量分类器的性能,其中AUROC值为“1”代表完美预测,AUROC值为“0.5”则意味着分类器完全无法区分类别。本文稍后针对创伤后应激障碍(PTSD)的章节中,将展示一个ROC曲线的有趣实例。值得注意的是,精确率-召回率曲线(Precision-recall curve)是另一种评价指标,在使用未加权数据时更具信息量,但对其的详细描述已超出本综述的范围(参见文献[146,147])。1.2 K折交叉验证(K-Fold Cross-Validation) 数据过拟合(overfitting)或欠拟合(underfitting)是机器学习模型训练中常见的两个问题。为了解决这些问题,通常对数据集采用K折交叉验证(K-fold cross-validation)方法,其中数据被划分为K个互不相交的子集,并将模型训练K次,每次用其中一个子集作为测试集,其余K-1个子集作为训练集。最终的测试性能由所有测试性能的平均值决定。K折交叉验证方法用于提高机器学习算法性能的泛化能力。 |
|---|
自然语言处理(Natural Language Processing)
自然语言处理(NLP)是人工智能的一种技术,可用于从文本数据源中识别并提取信息。多种文本数据源被用于检测压力,例如已有研究使用来自Twitter和Facebook的文本数据检测压力及其他精神疾病。为了解决任何自然语言处理问题,并满足“天下没有免费的午餐”定理(No Free Lunch theorem),研究者通常会应用多种机器学习方法,以获得最佳性能。已有一些算法在自然语言(NL)应用方面表现出色,包括支持向量机(SVM)、朴素贝叶斯(NB)、随机森林(RF)、集成学习方法、循环神经网络(如长短期记忆网络LSTM与门控循环单元GRU),以及近期出现的基于注意力机制的网络(如生成式预训练转换器3,即GPT-3,以及贝叶斯加性回归树BART)。上述方法均已被用于判断心理健康问题和行为特征。在NLP中一些常用的文本特征包括文档情感关键词(如语气)、可读性等指标。一项研究中,研究者使用了来自1746名Twitter用户的数据训练SVM,以预测抑郁症及创伤后应激障碍(PTSD)患者。研究提取的文本特征包括正面词汇数量、负面词汇数量、抑郁相关词汇数量,以及词袋模型(Bag-of-Words)。SVM在识别Twitter用户中抑郁与PTSD个体的表现为召回率0.8020,精确率0.1237。在另一项研究中,研究人员使用NLP基于创伤受害者撰写的文本而非医患面对面访谈来检测PTSD患者。有趣的是,使用机器学习进行检测所需的时间更短,成本也更低。研究者随后评估了决策树(DT)、朴素贝叶斯(NB)和支持向量机(SVM)三种机器学习方法的性能,结果显示SVM和NB的准确率分别达到约70%和78%。
检测压力水平的其他方法
用于检测压力水平的电生理信号(Electrophysiological signals)
脑电图(EEG)和心电图(ECG)是用于机器学习评估认知状态的数据源。压力水平与EEG及ECG模式之间的相关性已在先前研究中有所阐述。基于这些信息,研究人员开发出一种利用EEG记录并结合SVM的方法来识别个体是否处于压力状态。在收集EEG信号后,通过带通滤波器去除干扰信号,随后信号被转换为频域。最终生成的数据集包含功率谱密度和能量谱密度特征。研究中SVM使用了一种径向基函数(RBF)的非线性核函数,生成非线性超平面以区分处于压力与非压力状态的个体。通过五折交叉验证,该方法的整体准确率达到约83%。
此前研究还表明,深度神经网络(DNN)在基于EEG信号识别人类压力状态方面具有较高的准确率(如超过70%)。具体来说,训练于EEG信号提取特征的DNN在检测压力状态方面表现出了良好的潜力。例如,Cho等人利用一种改进的DNN方法通过ECG数据检测个体压力水平,其检测准确率相比之前的DNN方法有所提升,达到了约90%。
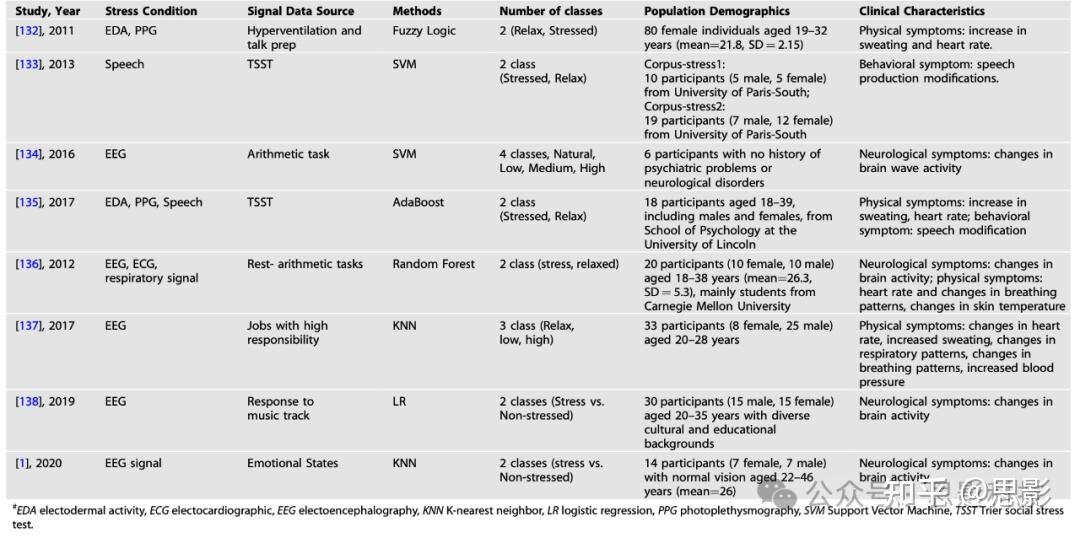
另一项研究中,作者基于EEG信号的统计特征生成数据集,收集了来自36名受试者的颞叶、额叶、中央区、枕叶及顶叶通道的EEG信号。提取的特征包括中位频率、谱矩(spectral moments)和修正频率均值特征。利用这些统计特征,研究者分别训练了支持向量机(SVM)、随机森林(RF)和K近邻(KNN)分类器,以区分压力相关与非压力相关的行为。结果表明SVM的准确率约为99%,表现优于其他分类器。表3总结了多个研究中所使用的方法、分类任务及相应的准确率表现。
表3:基于机器学习方法进行压力检测的代表性研究 (#)
最后,尽管EEG信号是检测压力的丰富信息源,但在记录过程中经常受到环境噪声的干扰。Subhani等人开展的研究中,利用不同压力水平个体的EEG信号训练了机器学习模型进行压力检测。信号经预处理及模型训练后,该机器学习模型能够以约94%的准确率检测压力相关与非压力相关的行为。这些结果证明,机器学习模型在发现EEG信号提取特征与压力之间的非线性关系方面表现有效。
机器学习在预测创伤后应激障碍(PTSD)中的应用
机器学习(ML)的应用领域非常广泛,其中在诊断创伤后应激障碍(PTSD)方面的应用尤为重要。PTSD是一种表现为内侧前额叶皮层、海马、杏仁核功能发生改变,以及记忆功能受损的障碍。PTSD的主要症状包括由创伤相关记忆引起的痛苦感受、对创伤相关线索的情绪反应、回避创伤相关的记忆和环境线索、对活动丧失兴趣、睡眠困难以及注意力不集中等。
在Wshah等人的一项重要研究中,作者使用随机森林(RF)算法基于基尼指数(Gini Index)预测特征重要性。基尼指数用于计算数据集中随机选取的特征被错误分类的概率,概率为0表示完全正确分类,概率为1表示随机分布在所有类别中。根据基尼指数,PTSD诊断中最重要的特征包括对自身和周围世界的负面信念、对日常活动缺乏兴趣、睡眠困难;而最不重要的特征包括距创伤事件发生的天数、注意力困难以及回避创伤相关的环境提示。
另一项研究中,研究者利用支持向量机(SVM)、随机森林(RF)和Lasso分类器预测PTSD。特征从超过160名因创伤住院并患有PTSD的儿童医疗数据中提取,共收集了105个特征。研究者应用了多种ML方法(其中SVM表现最佳,高于Lasso和RF)以筛选重要特征。最终,通过选取排名前十的重要特征,模型预测PTSD的准确率达到约74%。被选中的重要特征包括已有的PTSD病史、先前的外化症状、过往丧失经历、父母的急性压力或疼痛症状、保护性因素(如母乳喂养或参与宗教活动)、候选基因、先前寻求帮助的经历、氯胺酮使用(即某些儿童接受的一种谷氨酸药物,与PTSD的发生呈正相关)以及临床PTSD症状。
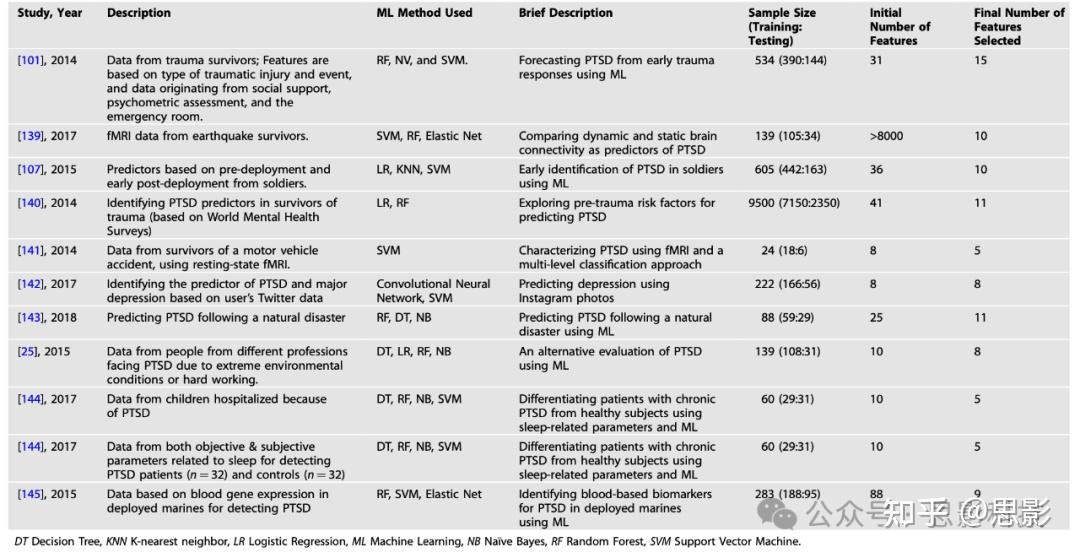
此前一些研究还成功预测了成年创伤者的PTSD。支持向量机(SVM)是预测PTSD最常用的机器学习方法之一,原因是其能够在高维搜索空间中找到最佳超平面,做出明确的分类(PTSD或非PTSD)。其他研究也应用了集成学习方法,如随机森林RF(例如参见引文[107])。表4展示了以往使用机器学习预测PTSD的一些重要研究示例。
表4:基于机器学习方法预测PTSD的代表性研究
最后,ROC曲线下面积(AUROC)是一种评价机器学习工具性能的指标,广泛用于预测压力行为或PTSD。例如,在一项研究中,作者应用机器学习预测服役10个月的现役军人是否会出现PTSD,预测依据的特征包括性别、年龄、种族、血液生物标志物、临床自我报告及神经认知功能评估[。研究者使用RF和SVM两种分类器进行分析,因为二者均被证实在解决非线性问题时能够有效减少偏差。结果表明,基于临床及生物特征,RF与SVM预测PTSD的AUC分别达到0.78和0.87,证明了机器学习方法在复杂特征环境下仍具有良好的分类能力。
另一项研究中则利用实时心率数据对退伍军人进行PTSD检测。研究人员通过可穿戴健康监测系统采集了107名退伍军人的生理信号。该设备可识别非运动引起的心率变化,有助于管理PTSD的发病。在预处理阶段应用了卡尔曼滤波器对心率数据进行滤波处理,然后利用Benjamini-Hochberg方法进行特征选择,以识别与PTSD最相关的特征。数据随后被划分为训练集与测试集,并使用了多种分类器进行PTSD检测,包括SVM、RF、K近邻(NN)、CNN和决策树(DT)学习算法。前四种分类器表现出较高的预测性能,但由于其“黑盒”(black-box)计算过程而难以解释,而决策树则在二元分类中具有更高的可解释性。
讨论与未来趋势
我们在本文综述了机器学习(ML)在检测压力与创伤后应激障碍(PTSD)方面的应用,简单介绍了机器学习和人工智能(AI)的基础概念,并列举了多个使用生理信号(如脑电图EEG)作为数据源的研究实例,这些研究从生理信号中提取特征,并利用提取的特征训练机器学习模型。此外,我们还展示了应用自然语言处理(NLP)技术从Twitter和社交媒体中提取特征用于检测压力的研究,以及最近一些预测压力相关障碍的ML方法的性能评估研究。总体而言,我们认为机器学习技术对医疗保健专业人员从现有数据中获取洞察具有重要潜力。
在检测压力或PTSD方面,对于高维且含噪的MRI数据,使用深度神经网络(DNN)通常能达到超过80%的准确率。而在以EEG信号为输入数据时,通常将信号转换至频域或能量密度,再从标准差、中位数等统计参数中提取特征,随后应用随机森林(RF)或支持向量机(SVM)进行预测。当患者数据为数值型,例如年龄、心率及父母病史等时,RF、逻辑回归(LR)及SVM的准确率通常高于70%。其中,RF模型由于其预测基于多个决策树的平均结果,因此可有效避免过拟合或欠拟合问题。
上述研究结果支持了机器学习在预测压力和PTSD并改善医疗质量方面的高效性。与传统统计方法相比,机器学习方法在处理高维数据、从大量变量中获得数据洞察方面表现出明显优势。然而,机器学习方法本身相对复杂,因此透明的研究报告对分析、解释和重复结果至关重要。
在选择机器学习模型时,需要考虑的一个主要问题是偏向于模型的可解释性与简洁性,还是更高的预测准确性。不同研究目标下的选择也不同,例如,如果研究目标是探究变量之间的关联,那么即使准确性较低,也应选择容易解释和透明度高的模型,如线性回归模型。相反,如果研究目标是实现最高的预测与分类准确性,则需要在模型准确性与解释简洁性之间做出权衡。
另一个关键点涉及数据源的合理使用、数据模态的选择,以及未来可用的新数据来源(例如遗传/基因组数据、环境数据(也称为非纯遗传数据[12])以及暴露组学(exposomics)数据等),这些数据对未来研究压力都可能非常有用。例如,“数字与情绪流行病学”(digital and emotional epidemiology)方法可利用在线社交媒体的数据资源,以深入分析心理压力状况,尤其适用于广泛的网络社群。
目前所描述的技术大多集中于检测日常压力源引起的急性压力反应。未来研究应扩大范围,整合多维数据,探索AI和ML如何检测创伤后应激的长期轨迹(例如恢复、抵抗力、韧性、延迟发作及慢性功能障碍,这些概念详见文献[114,115]),这些轨迹在临床实践中更具相关性。类似的分析方法可以采用潜在增长混合模型(Latent Growth Mixture Models),这一方法已成功应用于急诊就医后PTSD的检测。例如,可以将急性阶段的数据与额外的数据结合,以预测PTSD的长期发展轨迹。
未来建议方法:群智能(Swarm Intelligence, SI)用于压力检测
我们建议未来在压力检测与预测问题中可采用一种称为群智能(SI)的AI子类方法,这种方法涉及集成学习(ensemble)方法(详细的分类已超出本文综述范围),该方法在解决复杂与集体系统问题方面已展现出强大有效性。群智能方法基于多个方法合作的群体行为,以找到最佳解决方案。具体而言,每种方法都向可能的解决方案靠近,并最终选择整体最优解作为最佳结果。这种方法可有效地确定在任何研究问题中获得最佳准确率的机器学习方法。以均方误差(MSE)等函数评估每种方案,当所有患者被正确分类时,即可确定为最佳方案。SI算法在临床环境中的另一个重要优势是能够保护隐私,因为敏感的患者信息可以在本地进行处理。SI方法之一是粒子群优化算法(Particle Swarm Optimization, PSO),该方法通过位置和速度方程更新智能体(详情参见文献[125])。一些研究已使用组合式的SI算法检测疾病,例如冠心病、肺癌、乳腺癌以及精神障碍[129]。初步研究显示,SI算法(特别是鲸鱼优化算法与模拟退火算法的混合元启发式方法)能有效地检测压力水平。因此,我们认为SI是一种适合用于压力和PTSD预测的方法。
当前存在的局限性
基于机器学习的研究的常见局限性包括用于模型训练的数据规模有限(ML方法需要大量数据训练),潜在的患者隐私问题,以及训练数据中固有的偏差(如种族公平问题等)。此外,建立包含PTSD和压力相关表型信息的数据库将极大推动新的训练数据集生成,以及开发更强大的高性能机器学习方法。这些数据库将能更好地划分训练和测试数据集,并提供更合理的验证结果。小型数据集可能导致误分类,而更丰富的数据则增强了预测模型的泛化能力。未来研究应更加注重应用大数据进行知识提取和预测开发。然而,医疗领域的AI应用需要更谨慎的评估和验证,因为其影响远大于其他领域(如娱乐产业)。定义准确一致的“压力”概念至关重要,但压力的定义在文化内外存在显著差异,这也构成了机器学习研究的挑战。此外,未来研究应在概念和技术层面系统比较AI与传统统计方法,后者通常比AI方法更易于理解。
结论
本文强调机器学习方法在预测压力与PTSD方面表现可靠、准确性高,尤其在涉及大量变量时能有效筛选最佳特征。此外,EEG等生理信号可作为重要的数据来源,其中包含丰富的信息特征。尽管所述研究都具有积极的意义,但仍应注意其存在的重要局限性。解决这些局限需要大量工作,但最终将推动我们开发出更精确、更自动化的压力相关障碍检测、诊断与治疗系统。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









