





使用脑电图(EEG)诊断抑郁症是一个新兴的研究领域。当心理健康设施不可用时,在个人层面上使用EEG作为抑郁症管理的客观测量变得必要。然而,公开可获取的抑郁症EEG数据集有限,以及任务范式不标准,限制了研究的范围。本研究通过提供一个包含受试者静息状态EEG数据和患者健康问卷(PHQ-9)评分的数据集,为该领域做出了贡献。这些记录包括睁眼(EO)和闭眼(EC)两种条件下的EEG信号。此外,本研究使用新创建的数据集,记录了各种基准抑郁症分类任务的高性能表现,采用了传统的监督式机器学习算法,即决策树、随机森林、k-最近邻、朴素贝叶斯、支持向量机、多层感知器和极限梯度提升树(XGBoost),其中每位患者的类别标签由其PHQ-9评分确定。然后,使用ANOVA检验和相关性分析对二十三个线性、非线性、时域和频域特征进行特征选择,以识别具有统计学显著性的特征,这些特征进一步分别输入上述算法,用于区分健康受试者和抑郁患者。在这些分类器中,XGBoost的表现最佳,在EO状态下的准确率达到87%。所得结果表明,我们所提出的方法优于十四种现有方法。本文发表在Applied Intelligence杂志。
1 引言
大脑控制着人体的每一个行为,使其成为最重要的器官之一。然而,世界上每四个人中就有一个人在生命中的某个时候会受到精神障碍的影响,而缺乏适当的诊断会增加他们的痛苦。全世界有超过3亿人患有抑郁症。在最坏的情况下,抑郁症可能导致自杀。这是一种精神障碍,患者感到情绪低落、极度内疚或无价值感、精力和对愉悦活动兴趣的丧失,伴随着持续的负面甚至自杀念头,这种状态会持续相当长的时间。体重的显著变化、失眠或过度睡眠、注意力不集中和精神运动性激动也是抑郁症的主要症状之一。它影响大脑的化学和电活动,因此是一种持续的障碍,会导致日常生活中可观察到的功能损害。先前对抑郁个体的研究考察了认知过程以及这些过程与情绪调节障碍之间的关系原因。通过探索与抑郁症中情绪调节障碍相关的信息处理偏差的可能机制,研究人员发现抑郁症如何改变注意力、工作记忆、感知、信息处理和解释等认知过程。这些机制包括无法利用奖励线索来调节负面情绪、抑制过程和短时间内存储和操纵数据的缺陷,以及对负面情绪状态的深思熟虑的反应。然而,通过适当的诊断和治疗,抑郁症及其对认知健康的影响是可以治愈的。
EEG正在被考虑用于诊断各种疾病,如失眠、其他睡眠障碍、焦虑、癫痫、阿尔茨海默病和抑郁症。阿尔法不对称和阿尔法抑制是使用EEG诊断抑郁症中研究最多的主题。然而,研究人员仅使用基于阿尔法不对称的指标未能成功分类抑郁症患者。在抑郁症和焦虑症的情况下,不同脑区的频带功率相关性已有记录[。在[参考文献17]中,Mumtaz等人通过分别为每个参数训练模型来分析与抑郁症相关的参数。Khodayari-Rostamabad等人提出了一种基于生物标志物的方法,用于预测MDD对SSRI治疗的反应。在[参考文献19]中,Mohammadi等人考虑了谱特征和决策树(DT)分类器进行抑郁症分析。
1.1 抑郁症诊断的传统方法
为了观察抑郁症的症状,医疗从业者使用标准问卷与患者进行交谈会话,例如贝克抑郁量表和汉密尔顿抑郁量表。焦虑症的筛查可以通过问卷完成,如广泛性焦虑障碍量表-7。这些问题涉及工作、家庭和人际关系历史、过去的任何悲惨事件、药物和酒精使用、医疗状况和自杀念头[23]。要求患者完成心理自我评估。医生可能进行进一步的体检和检查,如血液检查,以排除特定症状的身体原因。
患者健康问卷-9(PHQ-9)是一组九个问题,用于诊断、筛查和监测抑郁症的严重程度。通过比较受试者对这九个问题的回答来计算PHQ-9得分。除了这九个计分问题外,还有一个非计分问题,用于观察抑郁问题对个人的影响。PHQ-9由患者自己完成,使其除了精神病学用途外,还适用于自我评估。它遵循DSM-IV标准,其中问题检测至少持续两周的持续性抑郁症状。事实上,DSM-5也推荐使用PHQ-9作为评估抑郁症严重程度的工具。每个问题有四个选项:1)完全没有,2)几天,3)超过半数天,4)几乎每天,分别赋予0、1、2和3的权重。PHQ-9的得分通过将所有问题的权重相加计算得出。表1显示了得分范围与抑郁程度的对应关系。
表1 PHQ-9得分和抑郁程度

尽管这些问卷被广泛使用并被认为是目前最可靠的方法,但有时它们无法准确反映抑郁程度。此外,患者对问卷的回答通常是主观的,缺乏准确性。很多时候,轻微的情绪变化可能被误解为抑郁症或严重焦虑。另一方面,也有一些情况下,患者不愿承认他们需要治疗,而且大多数人会中途放弃治疗。在这些情况下,一种能够显示大脑特定活动并能报告抑郁严重程度的方法变得必不可少。
1.2 动机和贡献
2012年,Puthankattil和Joseph基于受试者的EEG记录对抑郁症进行了分类。他们使用相对小波能量和基于信号熵的特征训练了一个两层前馈人工神经网络(NN)来进行分类任务。同年,Ahmandlou等人使用基于小波的滤波器组、非线性特征和分形维数训练了一个增强的概率神经网络。许多其他工作,如[参考文献8, 28,29,30,31,32,33,34],利用手工制作的特征和传统机器学习方法进行分类。上述研究为各种机器学习算法相对于传统的基于问卷的抑郁症诊断方法的有效性提供了充分的证据。然而,在当今背景下,以往方法的表现并不令人满意。此外,大多数过去的研究没有公开他们的数据集,这限制了他们结果的可重复性。这些点促使我们朝着改进抑郁症检测方法和创建可以帮助其他研究人员的数据集的方向努力。本研究的贡献列举如下:
1.据我们所知,目前公开可用的抑郁症分析数据集很少。因此,本研究提供了一个公开访问的原始EEG数据集,用于分析抑郁症。
2.新创建的数据集包含33名志愿者的EEG信号及其PHQ-9分数。这个数据集还包括每个志愿者两种状态下的EEG信号信息,即睁眼(EO)和闭眼(EC)。
3.本研究使用传统的监督机器学习算法在新创建的数据集上报告了各种基准抑郁症分类任务的高性能表现,其中每个患者的类别标签由其PHQ-9分数确定。
4.最初,本研究从23个特征开始。之后,选择了最佳的统计显著特征集进行进一步处理。
5.即使从3秒的短时EEG记录中,所提出的工作也可以使用统计显著特征预测受试者的抑郁水平。这提高了该方法在实际场景中的可用性。
本文的其余部分如下:第2节介绍了数据采集过程。第3节解释了用于特征提取和使用PHQ-9分数作为标签对受试者进行分类的方法。第4节报告了实验结果。最后,第5节得出结论。
2 数据采集
如今,有多种技术可用于理解人脑各种活动的行为。一些方法包括功能性磁共振成像、扩散张量成像、脑电图和脑磁图。本研究选择了脑电图,因为它具有高时间分辨率,并且可以对任何心理障碍期间大脑状态的变化进行多种分析。数据采集使用EEG Traveler Braintech 32+ CMEEG-01,该设备可通过计算机USB供电。它工作在0.1赫兹(Hz)到100 Hz的频带。模数转换器的采样频率为1024 Hz,内部存储的采样频率为256 Hz。它包括一个截止频率为0.5 Hz到100 Hz的高通数字滤波器和一个截止频率为0.1 Hz到7 Hz的低通数字滤波器。记录时使用含盐的EEG凝胶将电极粘贴在头皮上。
在EEG实验之前,设计了一个基于Django的Web应用程序,使用MySQL数据集来存储受试者的详细信息和他们的PHQ-9分数。Django数据库模型包含每个受试者的姓名、年龄、性别、实验时间和日期以及PHQ-9分数。运行在本地主机上的Web应用程序展示给参与者。要求他们回答屏幕上显示的十个英文问题。然而,在计算分数时不计入最后一个问题。所有的多项选择题包含四个选项,每个选项的权重为0、1、2和3。根据受试者选择的选项,使用JavaScript将所有答案的权重相加来估算总分。分数立即存储在数据集中,但不显示给参与者。应用程序的设计保持简单,使用可读的字体样式,以确保用户在回答问题时不会分心。
2.1 电极定位
电极定位是EEG数据记录中最关键的步骤。电极位置的轻微变化可能导致不同的电压值。国际10-20系统是一种国际公认的方法,用于确定EEG电极在头皮上的位置。本研究的实验考虑了Fp1、Fp2、F7、F3、Fz、F4、F8、T3、C3、Cz、C4、T4、T5、P3、Pz、P4、T6、O1、O2、A1、A2通道,接地电极位于Fpz,参考电极位于鼻根。
2.2 阻抗检查
接触阻抗在生物信号记录过程中起着至关重要的作用。皮肤与电极接触不当、汗液形式的多余盐分、EEG凝胶不足、电极和皮肤之间存在油脂以及头发不洁都会导致EEG电极的不良(高)阻抗。如果阻抗高,主要会在信号中添加低频噪声。原始EEG电压的幅度会降低,导致整体信噪比下降。因此,实验过程中将最大阻抗保持在20 kOhm以下。图1显示了实验过程中皮肤-电极阻抗值的示例。
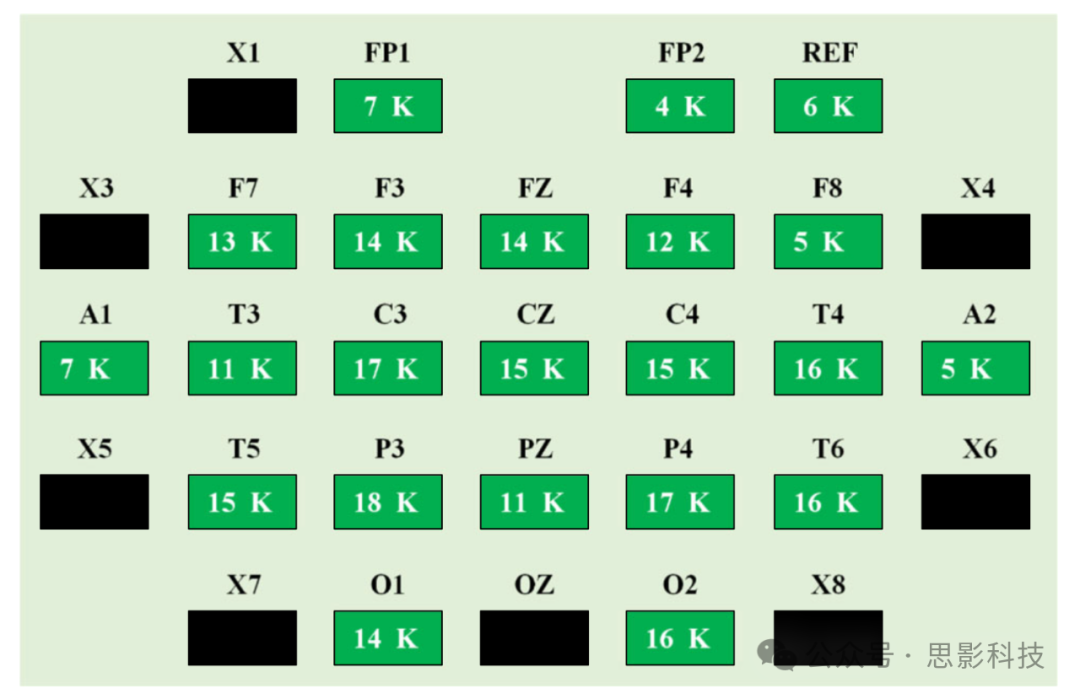
图1 实验过程中皮肤-电极阻抗值的示例
2.3 参与者
本研究包括33名右利手参与者的数据,他们均提供了书面知情同意。在33人中,15人患有抑郁症,其他人健康。总参与者中有6名女性,其余为男性。年龄范围从19岁到36岁,平均年龄为21.45岁,标准差为3.29。在数据采集之前未提供临床治疗、抗抑郁药或止痛药。健康组的平均年龄为21岁,而抑郁组的平均年龄为21.86岁。健康和抑郁的男性参与者的性别比例为16:11,而女性受试者的性别比例为1:2。健康组的平均PHQ-9分数为5.7,而抑郁组的平均PHQ-9分数为12。
2.4 实验设计
超过一半的先前与抑郁症相关的研究处理的是受试者处于静息状态(即不执行任何高认知负荷任务)时收集的数据。第二大类研究与涉及事件相关电位的实验有关。因此,本研究中的数据是在静息状态下记录的。数据集有两个部分,一个是包括PHQ-9分数在内的个人详细信息,另一个是EEG数据。通过Web应用程序将姓名、年龄、性别、日期、时间和PHQ-9分数等属性存储在数据库中。表2报告了参与者信息和PHQ-9分数的摘要。然后要求受试者以放松的姿势坐在椅子上,面对白墙(距离椅子2米)。清洁头皮后,使用EEG凝胶放置电极。通过检查皮肤-电极阻抗确保电极的适当接触。然后要求受试者放松并闭上眼睛。在开始实验之前,提供足够的时间让电极值稳定。EEG实验持续9分钟。有三个周期,每个周期包括1.5分钟的闭眼(EC)状态和1.5分钟的睁眼(EO)状态。实验持续时间的定义是为了确保受试者不会感到疲劳或困倦。连续4.5分钟的EC静息状态可能导致疲劳。在EO状态下,建议参与者不要进行扫视以避免与眼球运动相关的伪影。实验在一个基本上没有可能作为参与者负面刺激并为实验增加噪音的不必要信号的环境中进行。每1.5分钟给予参与者口头指示以改变眼睛状态。语音指示的持续时间为1秒。记录数据后,手动删除从一种状态过渡到另一种状态期间的信号以及某些不可避免的噪音,如运动活动、深呼吸等。在一次实验中,EC状态持续4.5分钟,EO状态持续4.5分钟,因为两个阶段都有三个1.5分钟的周期。
表2 参与者信息摘要,如年龄、性别及其PHQ-9分数

2.5 数据集特征
实验的设计方式集中于大脑的放松状态。可以使用此数据集研究抑郁症和其他障碍,如某个区域的抑制活动、区域间活动失衡以及大脑默认模式网络中正常脑活动的改变。一些参数会影响脑活动,如年龄、性别、实验时间、身体先前活动和药物使用。因此,在实验之前,确保受试者未服用任何止痛药、抗抑郁药或任何其他可能显著改变大脑活动的药物。数据集存在一些弱点,这些弱点是由于机器的限制和非理想的实验条件造成的。机器存储的值以微伏为单位,采用整数数据类型,因此不可能有小数值,即机器的分辨率为1微伏。在观察到从一种状态过渡到另一种状态时,会移除数据(持续1秒)。数据移除会在数据中产生不连续性,但这无法避免,因为它可能导致错误的结果。数据集有一些优点,使其成为可行的基准数据集。使用干电极可能导致大幅度的基线偏移。因此,为了最小化低频噪声,本研究使用湿电极。清洗头皮并涂抹足够量的凝胶以避免皮肤导电引起的噪声。这确保了电极与皮肤的适当接触。对数据使用尽可能少的处理,以避免不必要的数据丢失。用户有更多的自由度根据自己的要求去除噪声。
3 方法
数据集是促进多个计算领域发展的基础,为结果提供范围、稳健性和可信度。据我们所知,文献中用于分析抑郁症的数据集很少。在这个意义上,数量有限且不足。表3显示了公开可用数据集与新开发数据集的比较。创建数据集并非易事。因此,第一个创新点在于通过考虑重要的协议或方面来创建新的数据集,以促进抑郁症早期检测的发展,因为它是最普遍的精神障碍之一,全球影响超过3亿人。特征工程是通过利用领域知识从原始EEG信号中选择和转换最相关的特征,以设计和开发使用机器学习进行重度抑郁障碍或抑郁症早期检测的预测模型。新创建的数据集用于训练和评估新系统。这是当前工作的第二个贡献。图2显示了所提出系统的示意框图。整个过程分为四个部分,即数据采集、预处理、特征提取和分类。数据通过EEG设备和Web应用程序记录。
表3 公开可用数据集以及新创建数据集的摘要
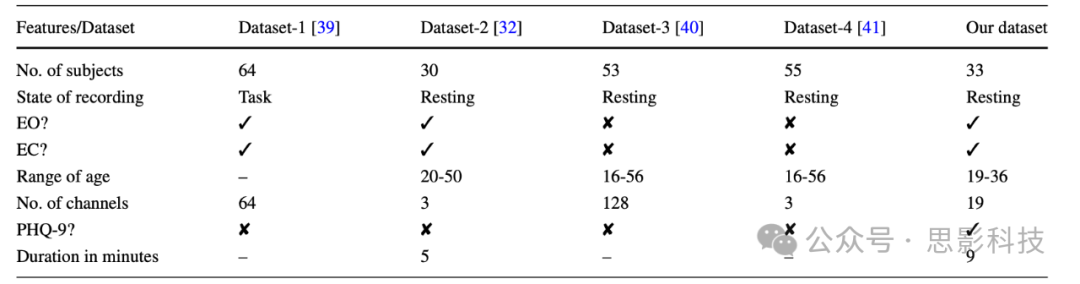
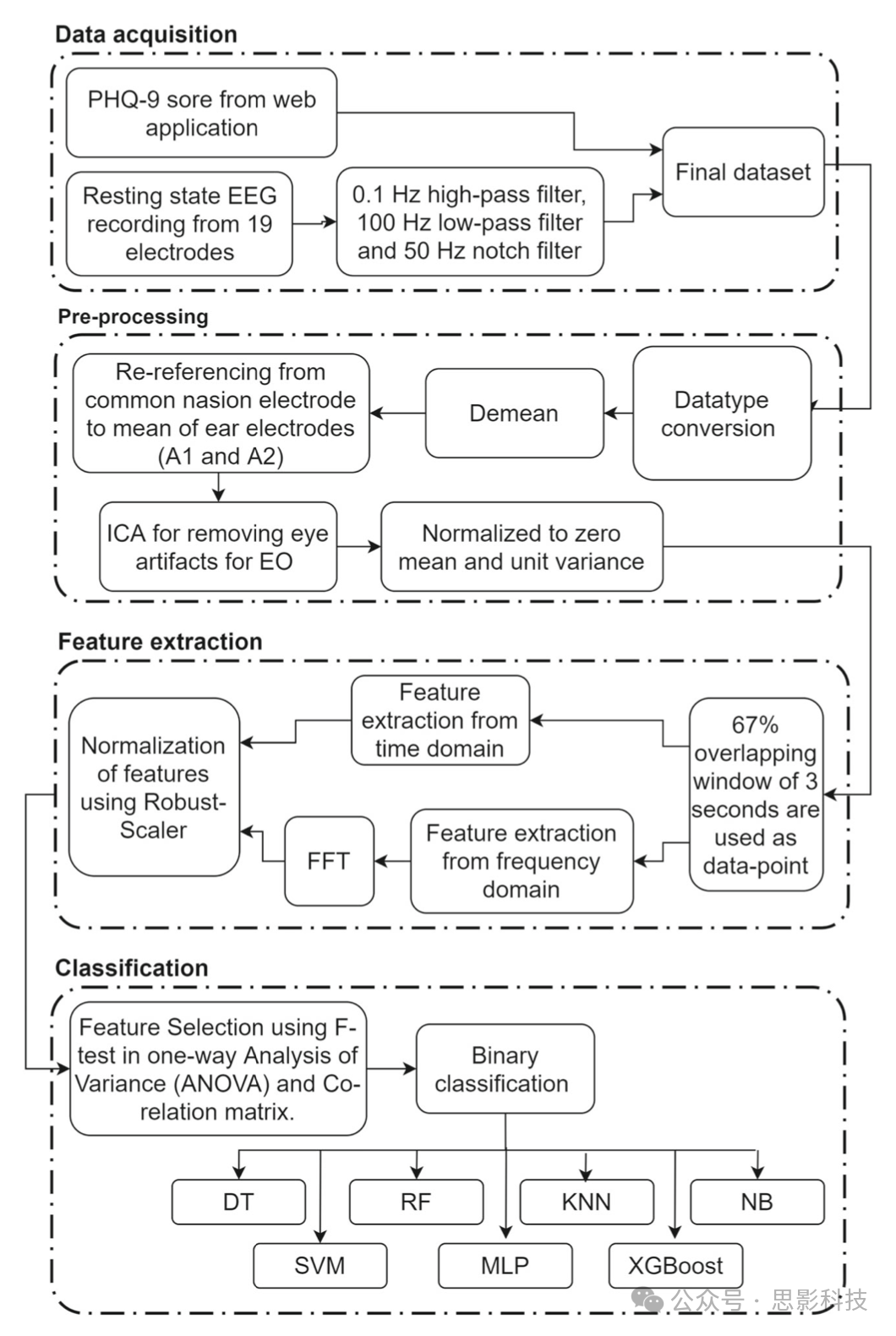
图2 提出方法的流程框图
EEG信号记录设备在记录过程中使用0.1 Hz高通滤波器、100 Hz低通滤波器和50 Hz陷波滤波器。由于使用了高通滤波器并且电极与头皮接触良好,数据中不存在基线漂移。因此,没有应用额外的滤波器来去除低频噪声。分析分别针对睁眼(EO)和闭眼(EC)两种情况独立进行,并比较结果。对于EO状态,数据集中存在眨眼伪影,使用独立成分分析(ICA)去除。ICA用于将数据分解为其统计独立的非高斯分量。它被考虑用于从EEG数据中去除伪影。将ICA应用于EEG数据有几个假设。原始EEG数据和伪影应线性相加并具有统计独立性。信号传播的延迟应为零,通道数应大于或等于源或独立分量(ICs)的数量。使用EEGLAB工具箱的'runica'算法及其默认设置将ICA应用于信号。图3显示了算法获得的19个ICs的样本输出。图4根据ICs的属性显示了对应于眨眼的IC。为了验证,比较了眨眼去除前后的结果(图4)。在预处理的最后一步中,每个信号都标准化为零均值和单位方差(图5)。
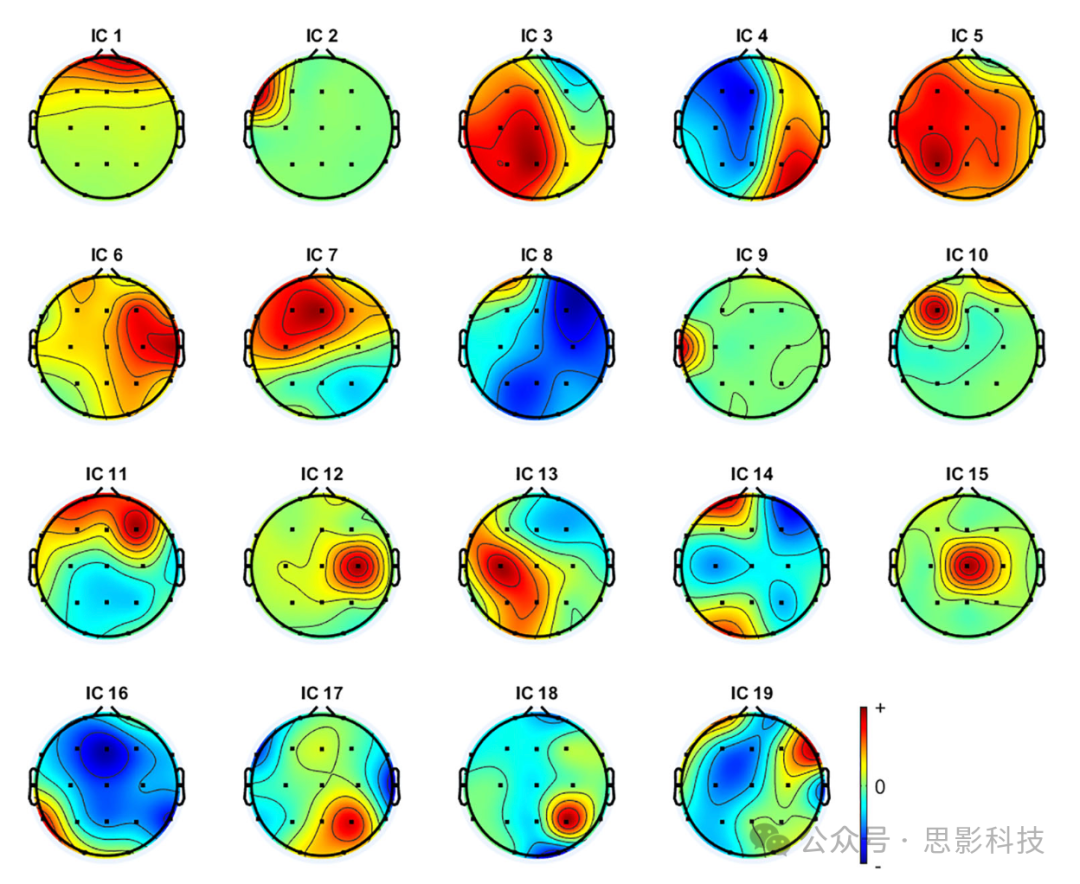
图3 EO状态下一个受试者的ICs热图样本
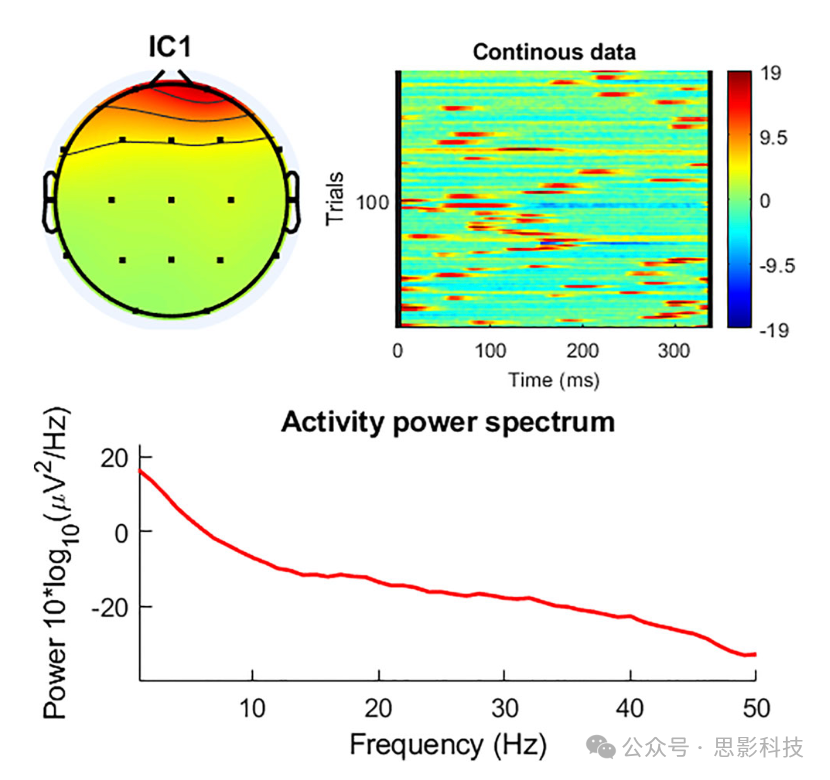
图4发现IC-1负责眨眼,因为其激活(红色)源位于FP1、FP2和FPz通道位置周围,其激活频率与实验期间眨眼的频率匹配
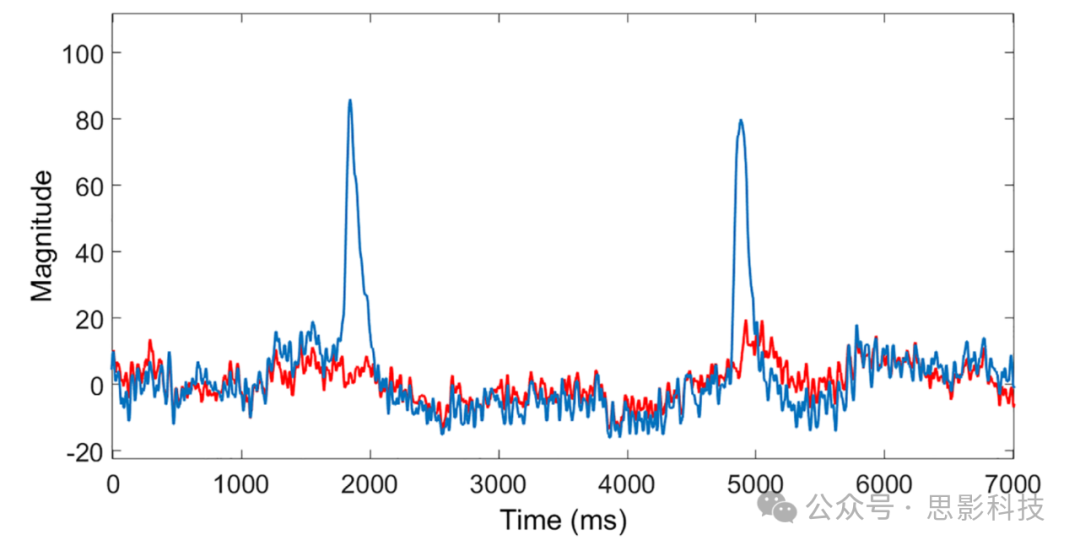
图5Fp1通道的EEG信号样本,显示了眨眼去除前(蓝色)和去除后(红色)的对比
3.1 特征提取
特征提取是从输入信号中揭示隐藏模式的过程。换句话说,一组特征可以表示输入信号。此外,这个特征集展示了原始输入信号所描绘的特定行为或模式。本研究考虑了23个时域和频域特征,并在以下方程中进行了解释。在这些方程中,x是表示一个电极的EEG信号的向量,xi是向量的第i个采样点的值,N是EEG信号的长度:
i带功率 它通过计算信号中所有采样点的平方均值来计算,使用方程(1)计算。

ii均值 它是通过将信号中所有采样点xi的总和除以样本大小N来计算的。公式(2)用于计算样本均值。

iii中位数 它是通过首先将采样点按照数值大小升序或降序排列,然后提取中间值来计算的。它通过公式(3)获得。
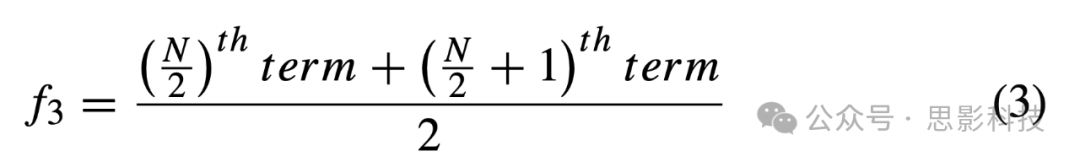
iv众数 它是最频繁出现的采样点,用f4表示。
v均值立方 公式(4)用于估计均值立方,它表示信号中所有采样点的立方的平均值。

vi标准差 它是衡量信号偏离均值程度的指标,通过公式(5)进行估计。
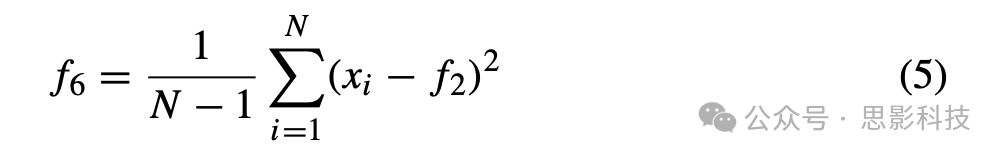
vii一阶差分 公式(6)用于计算信号的一阶差分。
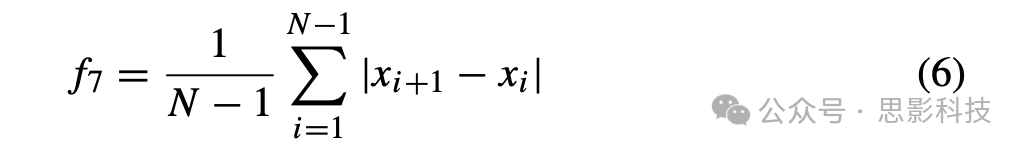
viii归一化一阶差分 它是一阶差分与标准差的比率,通过公式(7)计算。

ix二阶差分 它通过公式(8)进行估计。
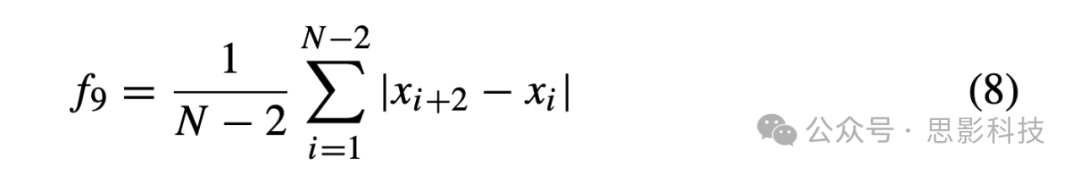
x归一化二阶差分 它是二阶差分与标准差的比率,通过公式(9)计算。

xi活动性 这被定义为信号一阶导数的方差除以该信号方差的平方根,使用公式(10)进行估计。EEG信号的活动性和复杂度参数被认为是大脑功能状态的良好指标。此外,它们对几种类型的生理变化高度敏感。

xii复杂度 它是信号一阶差分的活动度与该信号活动度的比率,用f12表示。
xiii皮尔逊偏度系数 它基于公式(11)计算。

xiv香农熵 公式(12)用于估计香农熵。

Shannon熵测量确实在本研究中被采用。我们观察到,所有熵的定义,包括响应熵和状态熵、近似熵、样本熵、模糊熵、Shannon置换熵、Shannon小波熵和Hilbert-Huang谱熵,都基于Shannon信息理论,根据[参考文献45],这是一个短程或广泛的概念。因此,我们认为这些熵测量之间的相关性很高。如果我们考虑它们,那么方差分析(ANOVA)将有助于保留一个特征并移除其他特征。上述列出的14个特征是时域特征。其余特征是在频域中提取的。使用Daubechies 8离散小波变换将输入的EEG信号分解为近似和细节子带,直到第6级。这些子带及其频率是delta (0.1–4 Hz)、theta (4–8 Hz)、alpha (8–13 Hz)、beta (13–30 Hz)和gamma (30–100 Hz)。感兴趣的读者可以参考[46]了解子带分解程序的详细信息。然后使用公式(1)计算全局相对delta功率(f15)、全局相对theta功率(f16)、全局相对alpha功率(f17)、全局相对beta功率(f18)、全局相对gamma功率(f19)、相对前额中央beta功率(f20)和相对前额中央低gamma功率(f21)。全局相对功率,即f15、f16、f17、f18和f19被定义为所有通道的平均带功率除以所有通道的平均功率。另一方面,相对前额中央功率,即f20和f21表示为前额中央通道(即Fp1、Fp2、F3、Fz、F4、C3、Cz、C4、P3、Pz和P4)的平均带功率除以前额中央通道的总平均功率。
xv Alpha不对称性1 这是抑郁症分析中常用的特征之一。它依赖于F3和F4通道,使用公式(13)计算:

其中αF3和αF4分别是F3和F4通道的alpha功率。
xvi Alpha不对称性2 它也依赖于F3和F4通道的alpha功率,使用公式(14)计算。
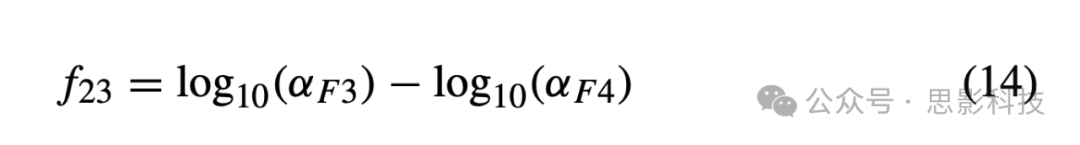
所有提取的特征都经过归一化处理,使其均值为零,标准差为1。
3.2 分类
在机器学习中,分类器是一种算法,它根据包含预定义类别成员资格的观测值的特征向量训练集,将输入特征向量映射到特定类别。提取特征后得到的两个特征矩阵(一个用于EO状态,一个用于EC状态)作为输入提供。进行内部验证以测试机器学习方法的稳健性。然而,每个特征矩阵都按67%/33%的比例分为训练数据和测试数据。图6显示了内部验证的图形表示。本研究采用了七种广泛使用的监督机器学习算法,即KNN [47]、NB [48]、DT [49]、RF [50]、SVM [51]、MLP [52, 53]和XGBoost [54],以确定一个人是否患有抑郁症。
KNN分类器使用的邻居数为45。MLP分类器在第一隐藏层使用200个感知器,第二隐藏层20个感知器,第三隐藏层20个感知器,迭代2000次,采用Adams优化算法,自适应学习率为0.0001。SVM使用径向基函数核和gamma缩放实现。RF分类器使用200棵树。DT的最大深度为100。对于NB和XGBoost,除了特征向量和类别标签外,没有使用其他外部参数。研究中使用的参数值是在尝试多种组合后确定的。在验证集(训练集的20%)上具有最佳准确率的参数集用于最终模型。
在监督学习中,有两个阶段,即训练和测试。在训练阶段,分类器需要训练数据和类别标签。这里,每个观测值的类别标签是根据PHQ-9分数决定的。为了简化问题陈述并将观测值分类为抑郁或正常类别,我们根据心理学家的建议,将轻微症状归入健康类,而将中度、中重度和重度归入抑郁类。因此,我们将PHQ-9分数9作为阈值。换句话说,如果观测值的分数低于阈值,则该观测值属于正常类,用类别0表示。另一方面,当观测值的分数大于或等于阈值时,将类别1分配给抑郁类。
分析通过将整个实验分为子实验来进行,以观察EC和EO状态下数据的最佳特征和算法。本研究考虑了四个性能评估指标,即准确率、精确率、召回率和F1分数,以验证实验结果。
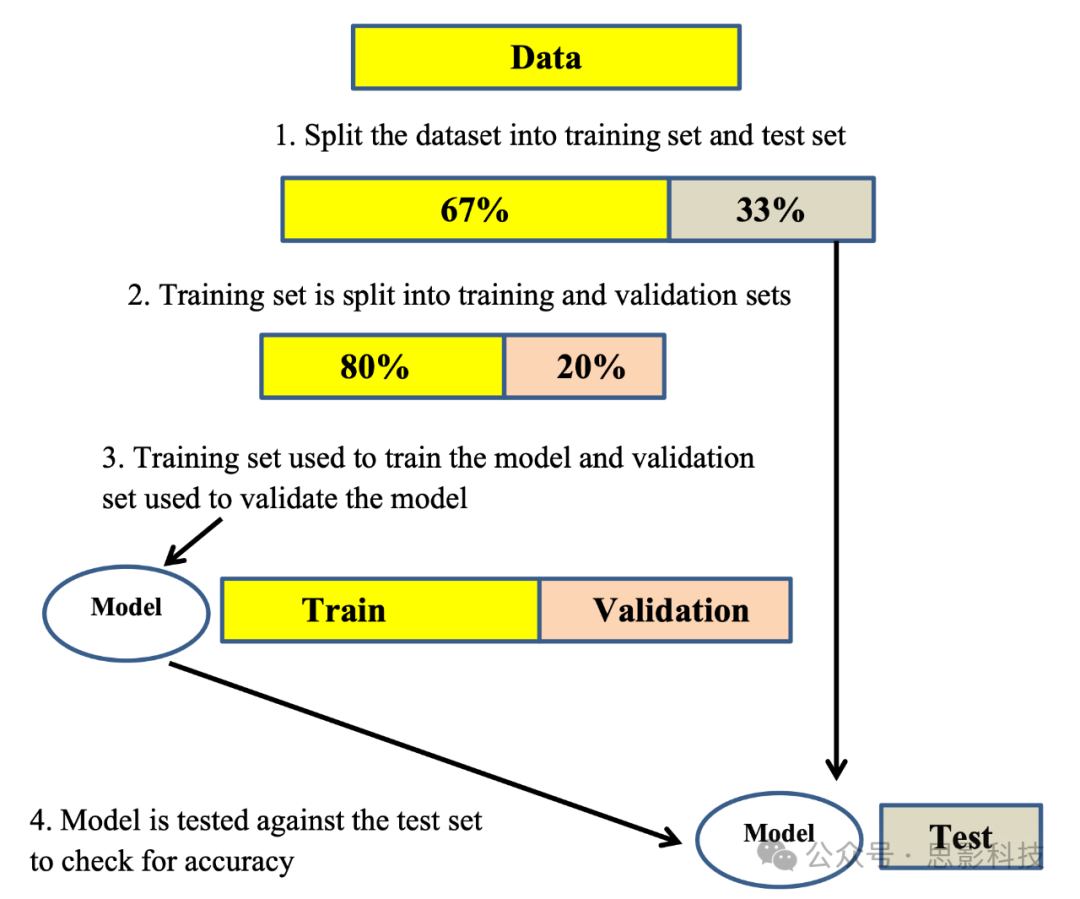
图6 抑郁症分析内部验证的详细描述
4 实验结果与讨论
4.1 环境设置
所有程序都在Python 3.8.2中实现,并在以下规格的笔记本电脑上执行:Intel(R) Core(TM) i5 6200U CPU @ 2.30 GHz,12 GB DDR3 RAM,NVIDIA GeForce 930MX图形引擎,以及64位Windows 10操作系统。
4.2 结果与讨论
从2.4节可以看出,每种状态分别分配了4.5分钟或4.5 × 60 = 270秒。由于CMEEG-01设备的采样频率为256 Hz,每秒有256个采样点。由于本研究中分类器是针对EO和EC状态独立训练的,因此每个个体的数据被分为两部分。信号使用预定义的3秒时间窗口进行分段,每个窗口重叠67%。因此,每个窗口有256 × 3 = 768个样本。每个受试者创建了268个epoch(所有受试者共8844个),19个通道中的每一个都提取了时间和频率信息。因此,特征向量的维度为166036 × 23(8844 × 通道数 = 168036)。选择3秒时间窗口和67%重叠的原因是:
a. 3秒包含768个样本,足以表示高达384Hz的频率分量(奈奎斯特-香农采样定理)[57]。因此,时间窗口确保了所有列出特征的适当提取。
b. 使用3秒67%重叠的数据分段后,从33个受试者构建了8844个数据点。8844个数据点足以训练二元分类器。
c. 67%的重叠消除了数据中的任何相位偏移效应,并且在不使用任何其他数据增强技术的情况下增加了数据点的数量。
d. 由于我们的目标是提供一种可在实际环境中实施的方法,他们使用短时间窗口作为数据点。提出的方法只需使用3秒的数据记录就可以对受试者进行分类。它也可用于当今大多数便携和经济实惠的EEG设备。
然后选择具有统计显著性和非冗余的特征。特征选择是通过移除不相关或冗余特征来减少特征大小的过程。它使我们能够构建更简单、更快速的机器学习模型。通常,它用于预测建模过程中。它可以以多种方式使用。它是对抗"维度灾难"的最有效武器。它也是避免过拟合的好方法。它使模型的泛化能力更容易利用。在这项工作中,通过分析特征的p值的统计显著性并考虑特征之间的相关性,对EO和EC状态的训练特征矩阵进行特征选择。由于所有特征几乎都遵循正态分布,因此进行了ANOVA测试。表4报告了通过ANOVA测试获得的23个特征的p值。图7显示了特征之间的相关性热图。p值小于0.05且相关性小于0.7的特征被认为是统计显著的特征。为了在两个高度相关的特征中选择一个,比较了两个特征与所有其他特征的相关值之和。相关性较小的特征被考虑用于进一步处理,而其他特征被拒绝。
表4 特征及其p值

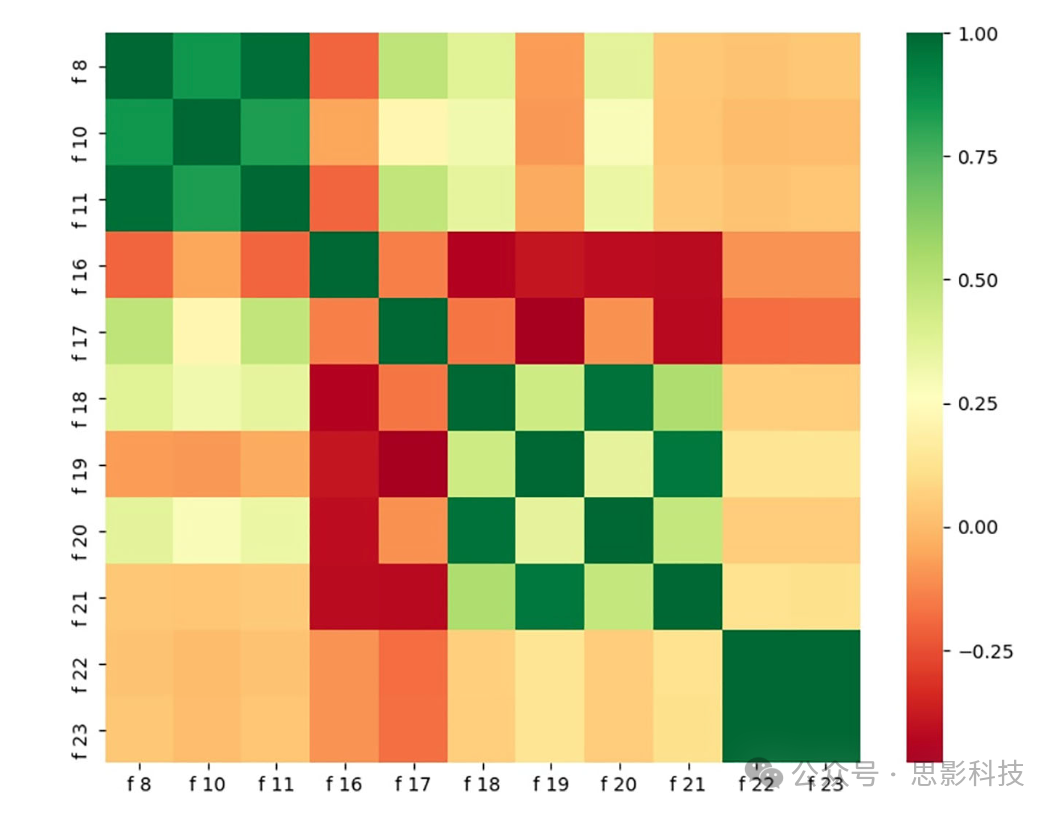
图7 显示特征相关性的热图
表4中用粗体字突出显示了具有统计显著性的p值。选定的特征是f8、f10、f11、f16、f17、f18、f20、f21和f23。然后将训练特征矩阵和类别标签分别输入KNN、NB、DT、MLP、SVM、XGBoost和RF,并在表5和表6中分别报告了EO和EC状态的准确率、精确率、召回率、F1分数和Cohen's Kappa分数。
从表5可以看出,EO状态下最佳准确率为87%,由XGBoost分类器实现。其他性能指标的值也相当令人满意。同样,从表6可以得出结论,EC状态下最佳准确率为86%,由XGBoost获得。此外,从两个表中发现,在大多数情况下,EO状态的结果优于EC状态。从表5和表6观察到,在本研究中用于区分健康人和抑郁症患者的所有分类器中,XGBoost表现最佳。
此外,进行了一项实验,以找出使用ANOVA测试和相关矩阵进行特征选择的重要性。图8显示了有无特征选择的准确率性能。此外,图9和图10分别显示了EO和EC状态下7个模型(包括提出的模型)的接收器操作特性曲线。
表5 EO状态下各种性能指标的值

表6 EC状态下各种性能指标的值

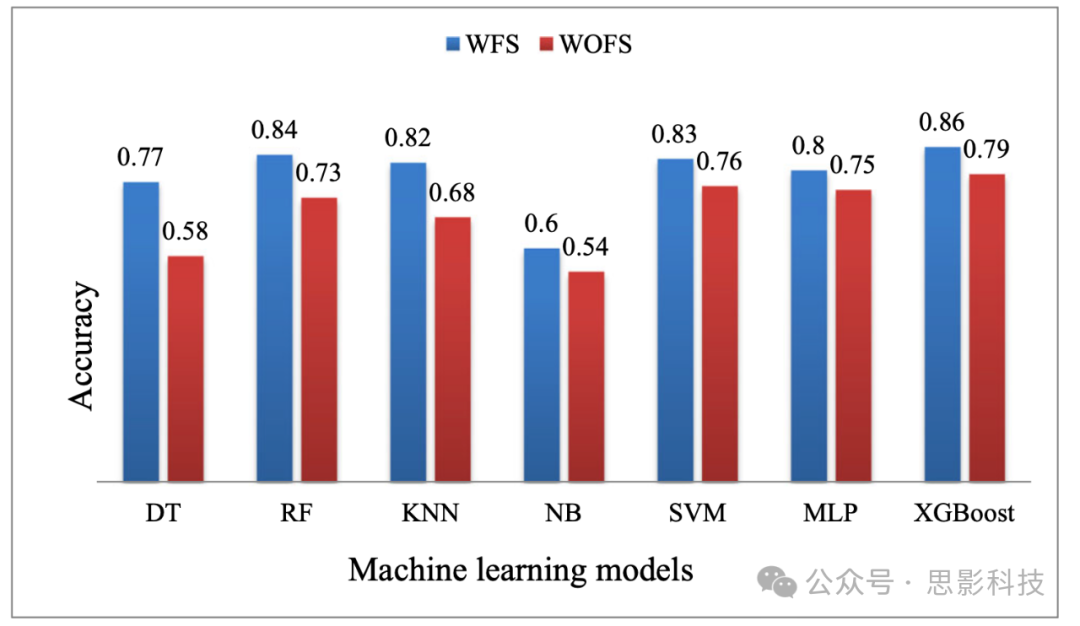
图8 各种机器学习模型有无特征选择的性能。这里,WFS→使用特征选择,WOFS→不使用特征选择

图9 EO状态下七种机器学习分类器的接收器操作特性曲线
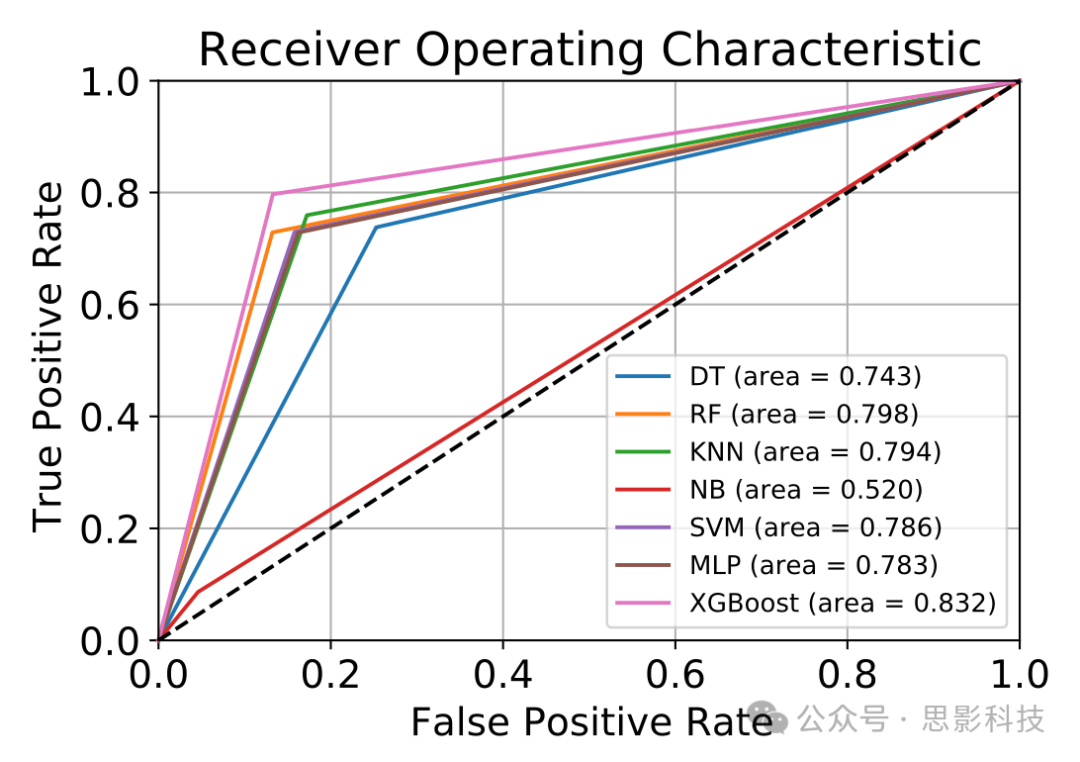
图10 EC状态下七种机器学习分类器的接收器操作特性曲线
从图8可以观察到,在使用ANOVA测试和相关矩阵选择特征后,各种机器学习模型在分类抑郁和非抑郁方面表现良好。然而,XGBoost在考虑所有特征时也给出了令人满意的性能,即79%。为XGBoost模型选择的参数是:n_estimators为500,学习率为0.3,基分类器名称为DT,树的最大深度(RF的最大深度)为30,训练集的子样本比例为0.8,权重lambda的正则化项默认选择(默认值=1)。
我们还进行了另一项实验,通过随机选择两个受试者使用3秒窗口数据(一个用于抑郁类,另一个用于非抑郁类)来确定模型的弹性。表7报告了每个机器学习模型的抑郁和非抑郁预测概率得分及其准确率。从每个受试者中提取了268个窗口。然而,只选择前10个窗口进行实验。从表7中,我们可以观察到XGBoost获得了更好的属于每个类别的预测分数。因此,3秒窗口数据可以表征抑郁/非抑郁信息。
表7 两个受试者前10秒窗口的每个机器学习模型的预测概率及其准确率
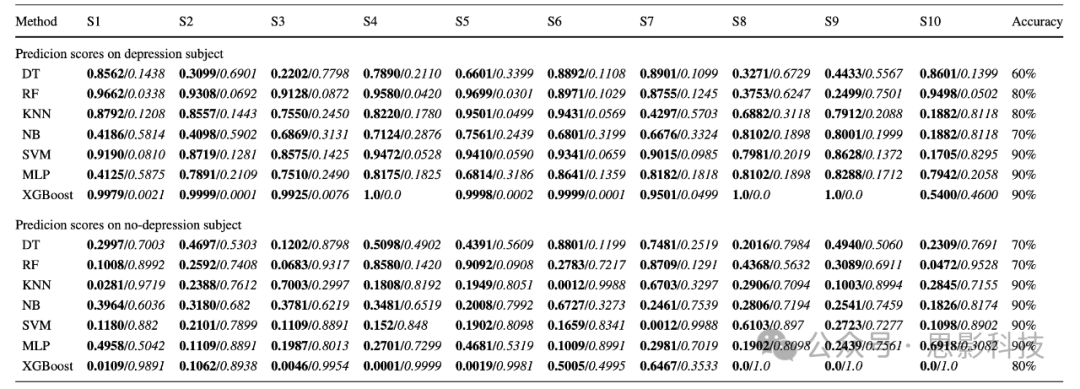
这里,粗体值表示抑郁症类别的概率得分,斜体值表示非抑郁症类别的概率得分。
提出的数据集确实很小。由于样本量与分类总体结果的可靠性成正比,因此初步工作的新创建数据将在未来进行分析。然而,我们相信新创建的数据集对抑郁和非抑郁信息具有真实代表性。众所周知,包含真实表示的小数据集提供更好的泛化。未来,我们将尝试开发个人心理健康监测系统。该系统将包括基于单电极便携式EEG头戴设备的数据采集系统、用于快速诊断的本地服务器和用于计算密集型数据处理的远程服务器。远程服务器上的数据可以被精神病学家作为治疗的一部分访问和处理。用户EEG历史记录的可用性可以帮助精神病学家诊断心理障碍。
本文研究试图提供一个公开可访问的数据集,用于非侵入性脑活动数据,这些数据与静息状态下的抑郁症相关。然而,提出的方法有一些局限性:i)提出的方法使用EEG设备进行分类。EEG设备相对昂贵。ii)由于EEG信号是非线性时变信号,使用线性滤波器进行处理会增加噪声。通过使用非线性特征,可以提高提出方法的准确性。iii)患者的焦虑会导致抑郁和非抑郁的错误分类。这是一个值得探讨的重要主题,我们将在未来涵盖患有焦虑症的受试者。
4.3 比较研究
所提出方法的分类报告与五种基于深度学习的模型进行了比较,即:一个两层前馈人工神经网络(NN),该网络使用相对小波能量和基于信号熵的特征进行分类任务训练[26];使用EEG信号的深度表示和序列学习进行自动抑郁症检测[60];使用深度卷积神经网络进行基于EEG的自动抑郁症筛查[61];用于自动检测临床抑郁症的基于EEG的深度学习模型[62];以及用于基于EEG的抑郁症筛查的混合神经网络。
此外,还与九种基于手工制作特征的方法进行了比较,即:Ahmandlou等人使用基于小波的滤波器组、非线性特征和分形维度训练了增强的概率神经网络[27]。在[28]中,从EEG数据中提取小波包分解和非线性特征,并使用机器学习技术进行分类。在[29]中,作者提出了一种基于EEG的自动抑郁症诊断方法,利用非线性方法如分形维度、最大Lyapunov指数、样本熵、去趋势波动分析、Hurst指数、高阶谱和重现量化分析。一种用于诊断重度抑郁障碍的计算机辅助技术[63],基于EEG的抑郁症检测的普适方法[8],基于多模态EEG数据的特征级融合方法用于抑郁症识别[33],用于抑郁症检测的脑电图信号改进经验模态分解[34],使用局部小波滤波器组自动检测异常EEG信号[64]和使用带有三电极EEG采集器的深度信念网络进行普适EEG抑郁症诊断[30]。
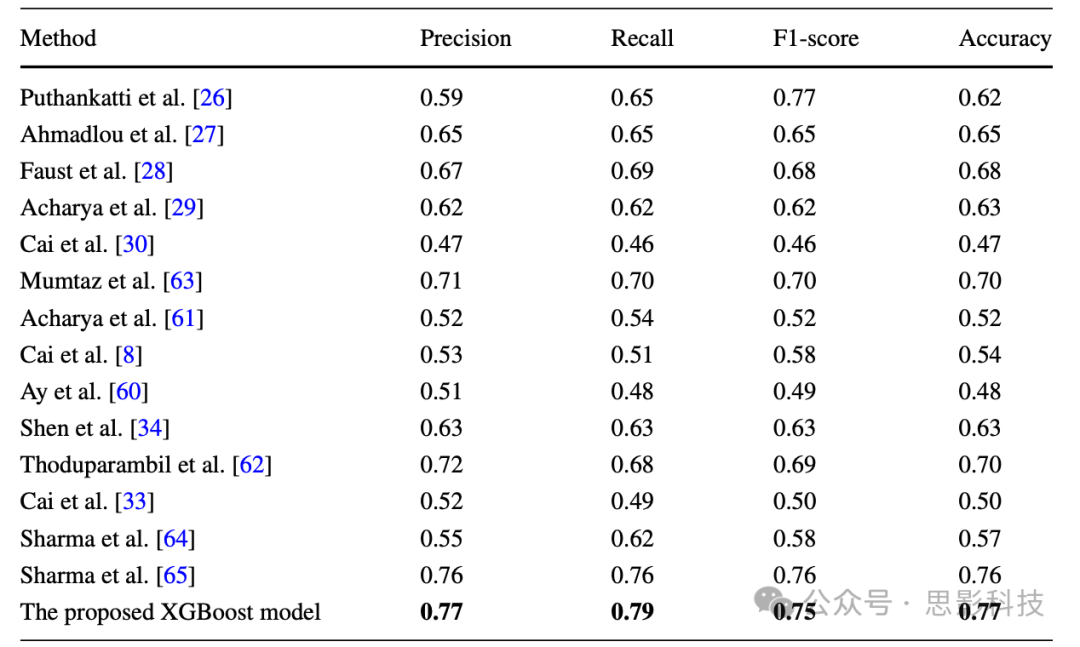
这些模型的详细描述超出了本研究的范围。感兴趣的读者可以参考相应的工作以获取这些方法的更多细节。然而,在实现上述九种方法时考虑的参数值与其各自原始研究文章中的保持一致。比较结果在表8中呈现。这些先前的方法在当前的数据集上实施,以确保与表现最佳的XGBoost模型进行公平比较,后者以粗体字突出显示。我们的模型比先前的方法取得了更好的性能,并显示了其在抑郁症分类中的潜在应用价值。
表8 十四种先前方法和提出的XGBoost模型的分类报告
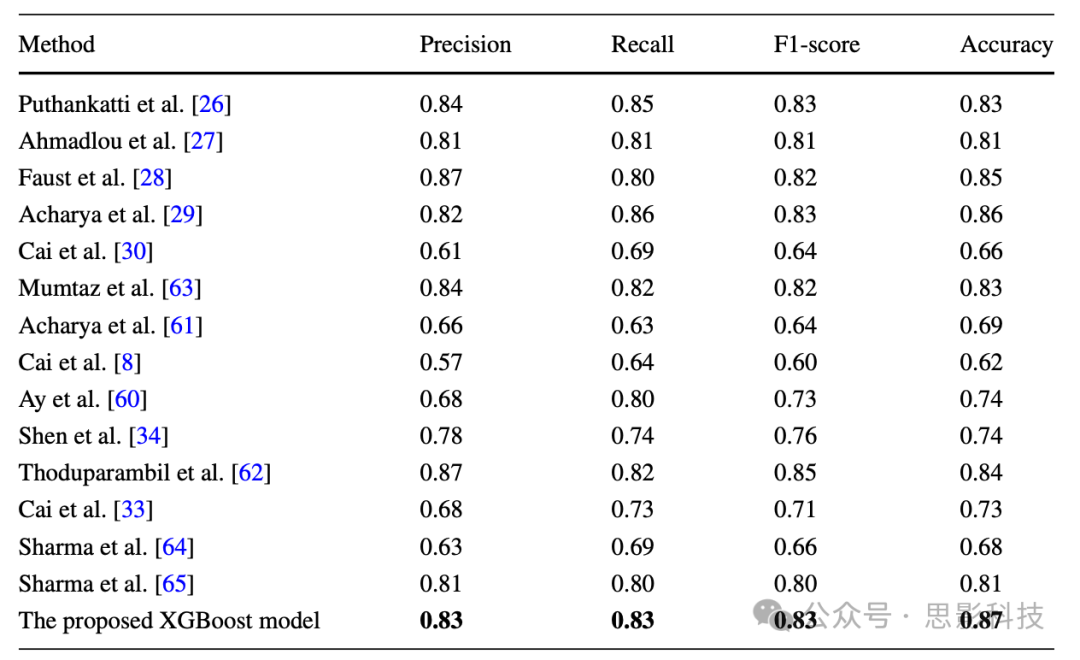
为了找出提出方法的稳健性,采用了10折交叉验证技术,并使用所有结果的平均值来计算最终分类性能。换句话说,在10个子集中,8个用于训练,1个用于验证,剩下1个用于测试。现有方法也使用10折交叉验证进行了检验,以便与提出的方法进行公平比较。实验结果报告在表9中,其中提出方法的结果用粗体标记。在这种情况下,选择XGBoost分类器进行比较,因为它在留出验证中优于其他机器学习分类器。
表9 十四种先前方法和提出的XGBoost模型的10折交叉验证结果的平均性能
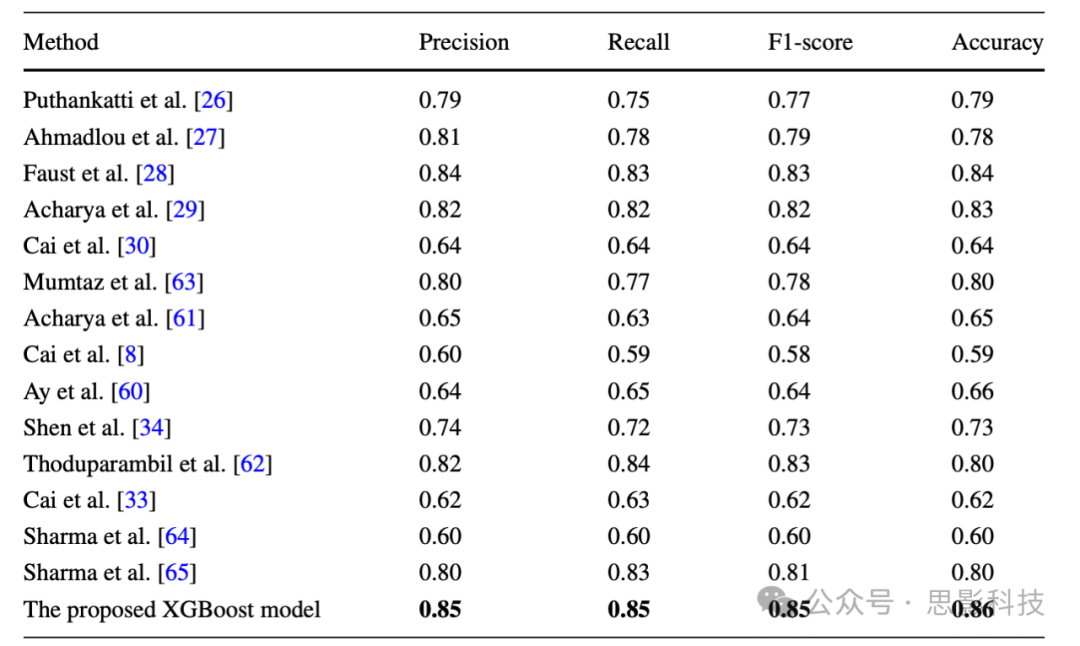
这些先前技术在当前的数据集上使用10折交叉验证实施,以确保与表现最佳的XGBoost模型进行公平比较。我们的模型优于先前方法,并已证明在抑郁症分类中有效。此外,对提出的方法和现有方法进行了基于受试者的交叉验证。33名受试者分成10部分,9部分用于训练,剩下1部分用于测试。我们特别努力确保相同受试者的样本不会同时用于训练和测试。基于受试者评估的实验结果报告在表10中,显示了10折的平均结果。粗体字显示了提出方法获得的结果。这里选择XGBoost分类器进行比较,因为它在留出验证中优于其他机器学习分类器。从表10可以观察到,我们提出的方法获得了比其他现有方法更好的性能。
表10 十四种先前方法和提出的XGBoost模型的10折基于受试者验证结果的平均结果
5 结论
本研究提出了一个用于分析静息状态抑郁症的数据集。该数据集包含33人的EEG信号及其由心理学家标注的PHQ-9评分。考虑了七种机器学习算法,即KNN、NB、DT、MLP、SVM、XGBoost和RF,用选定的具有统计显著性的特征报告初步基准分类性能,这些特征包括归一化一阶差分、归一化二阶差分、移动性、全局相对theta功率、全局相对alpha功率、全局相对beta功率、相对额中心beta功率、相对额中心低gamma功率和AASI2。在本研究中使用的机器学习分类器中,XGBoost分类器的性能最佳,EO状态下的准确率为87%。将向数据集添加更多受试者的EEG信号,既包括相同任务设计,也包括不同任务设计,并加入刺激。基于刺激的实验可以作为治疗基础。XGBoost模型可以在临床环境中作为使用EEG信号诊断抑郁症的工具。
本研究提出的数据集确实很小。由于疫情,数据集扩展过程已经停止。我们很快会在数据集的更新版本中添加更多不同年龄组的受试者。我们将尝试开发个人心理健康监测系统。该系统将包括基于单电极便携式EEG头戴设备的数据采集系统、用于快速诊断的本地服务器和用于计算密集型数据处理的远程服务器。远程服务器上的数据可以被精神病学家作为治疗的一部分访问和处理。用户EEG历史记录的可用性可以帮助精神病学家诊断心理障碍。本研究试图提供一个公开可访问的数据集,用于非侵入性脑活动数据,这些数据与静息状态下的抑郁症相关。

















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









