









在 InfluxData,开发人员和架构师经常问我们的常见问题之一是:“在时间序列工作负载方面, InfluxDB 与Elasticsearch相比如何?” 提出这个问题可能有几个原因。首先,如果他们正在启动一个全新的项目并进行面对面评估一些解决方案的尽职调查,这可能有助于创建他们的比较网格。其次,他们可能已经在现有监控设置中使用 Elasticsearch 提取日志,但现在想了解如何将指标收集集成到他们的系统中,并相信对于此任务可能有比 Elasticsearch 更好的解决方案。
在过去的几周里,我们开始比较 InfluxDB 和 Elasticsearch 在时间序列工作负载方面的性能和功能,特别关注数据摄取率、磁盘数据压缩和查询性能。InfluxDB 在两项测试中优于 Elasticsearch,与 Elastic 的时间序列优化配置相比,写入吞吐量提高了3.8倍,同时使用的磁盘空间减少了9倍。与 Elasticsearch 的缓存查询的响应时间相比, InfluxDB为测试查询提供的响应时间快了7.7倍。
还需要注意的是,为时间序列配置 Elasticsearch 并非易事 — 它需要预先决定索引、堆大小以及如何使用 JVM。另一方面,InfluxDB 可以开箱即用地用于时间序列工作负载,无需额外配置专为处理时间序列而设计的模式和查询语言。
我们认为这些数据对于评估这两种技术对其用例的适用性的工程师来说是有价值的;具体来说,时间序列用例涉及自定义监控和指标收集、实时分析、物联网 (IoT) 和传感器数据,以及容器或虚拟化基础设施指标。基准测试并未考虑 InfluxDB 对于除基于时间序列的工作负载之外的工作负载的适用性。InfluxDB 并非旨在满足全文搜索或日志管理用例,因此超出了范围。对于这些用例,我们建议坚持使用 Elasticsearch 或类似的全文搜索引擎。
要阅读基准和方法的完整详细信息,请下载“时间序列数据和指标管理的 InfluxDB 与 Elasticsearch 基准测试”技术论文或观看录制的网络研讨会。
我们的首要目标是创建一致的、最新的比较,反映 InfluxDB 和 Elasticsearch 的最新发展以及后来对其他数据库和时间序列解决方案的报道。我们将定期重新运行这些基准测试,并根据我们的发现更新我们的详细技术论文。这些基准测试的所有代码都可以在 Github 上找到。如果您有任何问题、意见或建议,请随时在该存储库上提出问题或拉取请求。
现在,让我们看看结果......
已测试版本
InfluxDB v1.8.0
InfluxDB 是一个用 Go 编写的开源时间序列数据库。其核心是一个称为时间结构合并(TSM)树的定制存储引擎,它针对时间序列数据进行了优化。InfluxDB 由名为InfluxQL的自定义类 SQL 查询语言控制,为跨时间范围的数学和统计函数提供开箱即用的支持,非常适合自定义监控和指标收集、实时分析以及物联网和传感器数据工作负载。
弹性搜索 v7.8.0
Elasticsearch 是一个用 Java 编写并构建在Apache Lucene之上的开源搜索服务器。它提供了适合企业工作负载的分布式全文搜索引擎。虽然 Elasticsearch 本身不是时间序列数据库,但它使用 Lucene 的列索引,用于聚合数值。结合查询时聚合和时间戳字段索引功能(这对于存储和检索日志数据也很重要),Elasticsearch 提供了用于存储和查询时间序列数据的原语。
在构建代表性基准套件时,我们确定了处理时间序列数据时最常评估的特征。我们考察了三个向量的性能:
- 数据摄取性能– 以每秒的值来衡量
- 磁盘存储要求– 以字节为单位
- 平均查询响应时间– 以毫秒为单位
由于 Elasticsearch 是一种特殊用途的搜索服务器,不适用于开箱即用的时间序列数据,因此 Elastic 建议更改一些配置来存储这些类型的指标。在我们的测试中,我们发现这些变化:
- 对写入或查询性能没有影响
- 存储要求确实有所不同
关于数据集
对于此基准测试,我们重点关注对常见 DevOps 监控和指标用例进行建模的数据集,其中一组服务器定期报告系统和应用程序指标。我们每 10 秒对 9 个子系统(CPU、内存、磁盘、磁盘 I/O、内核、网络、Redis、PostgreSQL 和 Nginx)采样 100 个值。为了进行关键比较,我们查看了代表 24 小时内 100 台服务器的数据集,这代表了相对适度的部署。
- 服务器数量:100
- 每台服务器测量的值:100
- 测量间隔:10s
- 数据集持续时间:24小时
- 数据集中的总价值:每天87M
这只是整个基准测试套件的一个子集,但它是一个具有代表性的示例。如果您对更多详细信息感兴趣,可以在GitHub上阅读有关测试方法的更多信息。
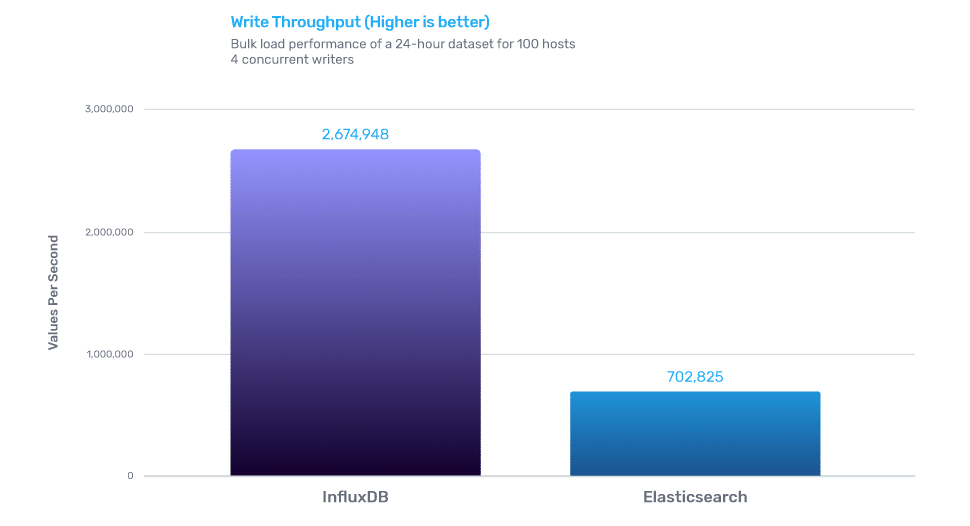
写入性能
在数据摄取方面,InfluxDB 的性能比 Elasticsearch 高出 3.8 倍。
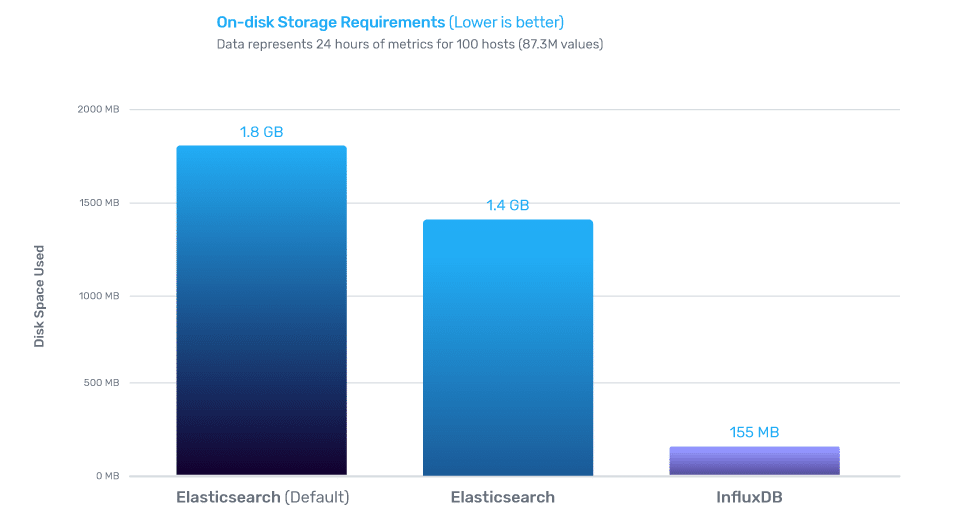
磁盘压缩
InfluxDB 在时间序列方面的性能优于 Elasticsearch,压缩率提高了 9 倍。
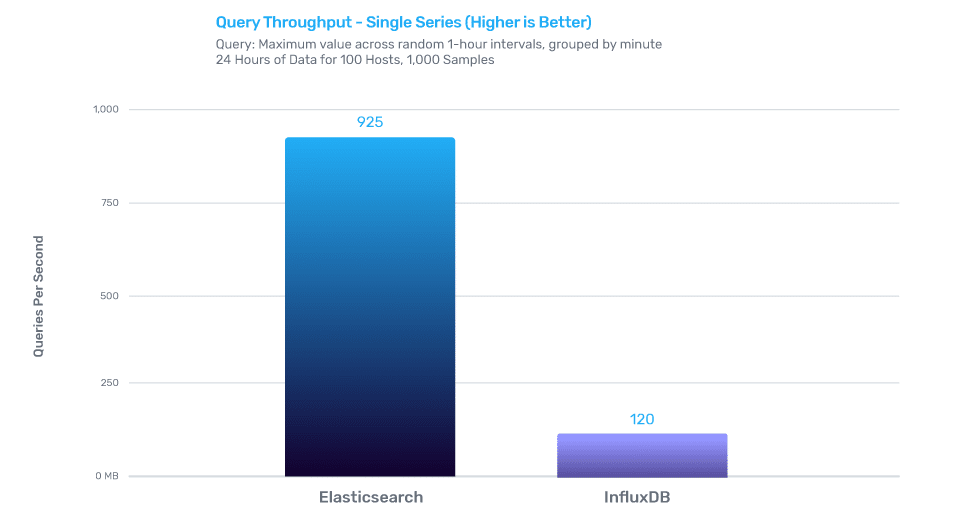
查询性能
返回缓存查询时,时间序列 InfluxDB 的性能提高了 7.7 倍。
概括
最终,对于这些类型的工作负载,旨在处理指标的专用时间序列数据库将显着优于搜索数据库,许多人可能对此并不感到惊讶。尤其引人注目的是,当工作负载需要可扩展性时(这是实时分析和传感器数据系统的共同特征),像 InfluxDB 这样专门构建的时间序列数据库就会发挥作用。
总之,我们强烈鼓励开发人员和架构师自己运行这些基准测试,以独立验证其所选硬件和数据集的结果。然而,对于那些寻找有效起点的技术将提供更好的“开箱即用”时间序列数据摄取、压缩和查询性能的人来说,InfluxDB 在所有这些维度上都是明显的赢家,特别是当数据集变得更大,系统运行的时间更长。

















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









