 Python实现朴素贝叶斯算法详解
Python实现朴素贝叶斯算法详解








 本文介绍了如何使用Python从底层实现朴素贝叶斯算法,包括数据导入、数据集划分、类别标签计数和比例计算。详细讲解了朴素贝叶斯的原理,对比了拉普拉斯修正的方法,并探讨了其在大数据量时的效率问题。同时,文章提供了完整代码的GitHub链接。
本文介绍了如何使用Python从底层实现朴素贝叶斯算法,包括数据导入、数据集划分、类别标签计数和比例计算。详细讲解了朴素贝叶斯的原理,对比了拉普拉斯修正的方法,并探讨了其在大数据量时的效率问题。同时,文章提供了完整代码的GitHub链接。
历史文章:
1、python底层实现KNN:https://blog.csdn.net/cccccyyyyy12345678/article/details/117911220
2、Python底层实现决策树:https://blog.csdn.net/cccccyyyyy12345678/article/details/118389088
1、导入数据
使用的数据和决策树数据相同,使用贷款数据,详情如下:
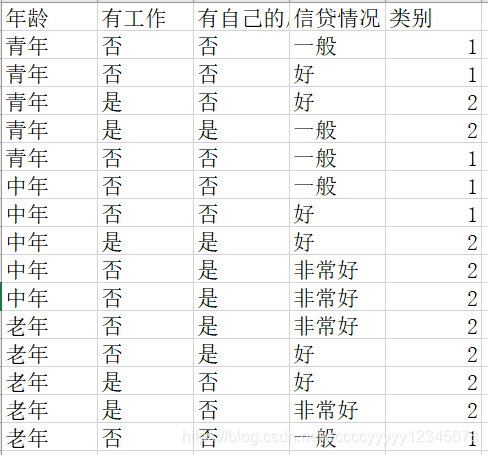
导入数据步骤和之前文章提到的KNN,决策树相同,借助python自带的pandas库导入数据。
def read_xlsx(csv_path):
data = pd.read_excel(csv_path)
print(data)
return data2、划分数据集
def train_test_split(data, test_size=0.2, random_state=None):
index = data.shape[0]
# 设置随机种子,当随机种子非空时,将锁定随机数
if random_state:
np.random.seed(random_state)
# 将样 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









