






在Shein中,商品标签的合规性至关重要。如果标签不合格,可能会导致商品被下架、扣除赔付金等严重后果。那么,当遇到TEMU标签不合格的情况时,商家应该如何应对呢?是否有标准的标签模板可供参考呢?
甩手跨境工具箱支持Shein、Temu等多个跨境电商平台的标签合成制作,可用于发货使用。它提供了丰富的标签模板,商家可以根据需要自行创建自定义的标签模板,也可以使用现有的模板进行快速制作。
使用地址:跨境工具![]() https://dztool.shuaishou.com/tool/toolEntry?inviteCode=2RdakK
https://dztool.shuaishou.com/tool/toolEntry?inviteCode=2RdakK
一、工具优势
1、多平台支持:甩手跨境工具箱不仅支持Shein,还兼容TEMU、Tiktok、速卖通等多个跨境电商平台,满足商家多样化的标签制作需求。
2、模板丰富:软件内置了多种通用模板,商家可以快速选择并编辑,节省时间。同时,商家也可以自行创建自定义模板,灵活满足个性化需求。
3、编辑功能强大:在标签编辑界面,商家可以添加线条、文字、图片、标志、警示语等元素,并调整它们的大小及位置。此外,还支持批量处理功能,如批量修改标签内容、批量导出等。
4、合成效率高:甩手跨境工具箱采用先进的合成技术,能够快速将多个标签内容整合到一张纸上,减少打印次数和纸张浪费。同时,支持合成单个或多个PDF文件,方便商家管理和打印。
5、操作简便:软件界面简洁直观,商家可以轻松上手,快速完成标签合成操作。无需复杂培训,即可提高工作效率。
二、将条码合成为标签
1、打开甩手跨境工具箱网页,注册登录后,点击【标签合成】。
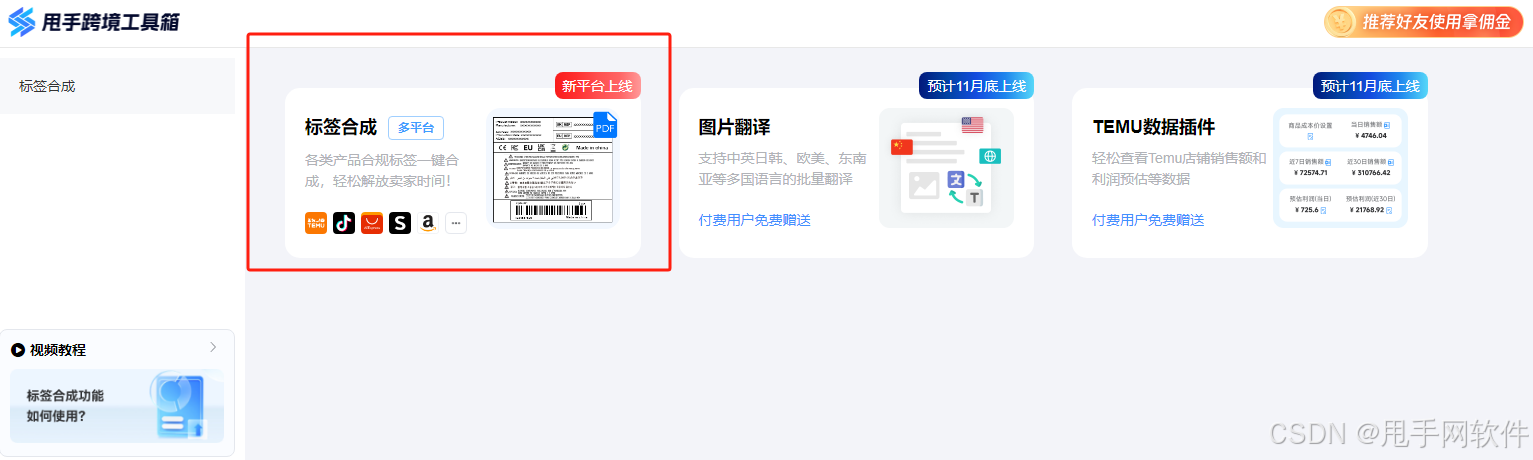
2、进入编辑界面,选择推荐模板或自定义制作
如何创建自定义标签模板?
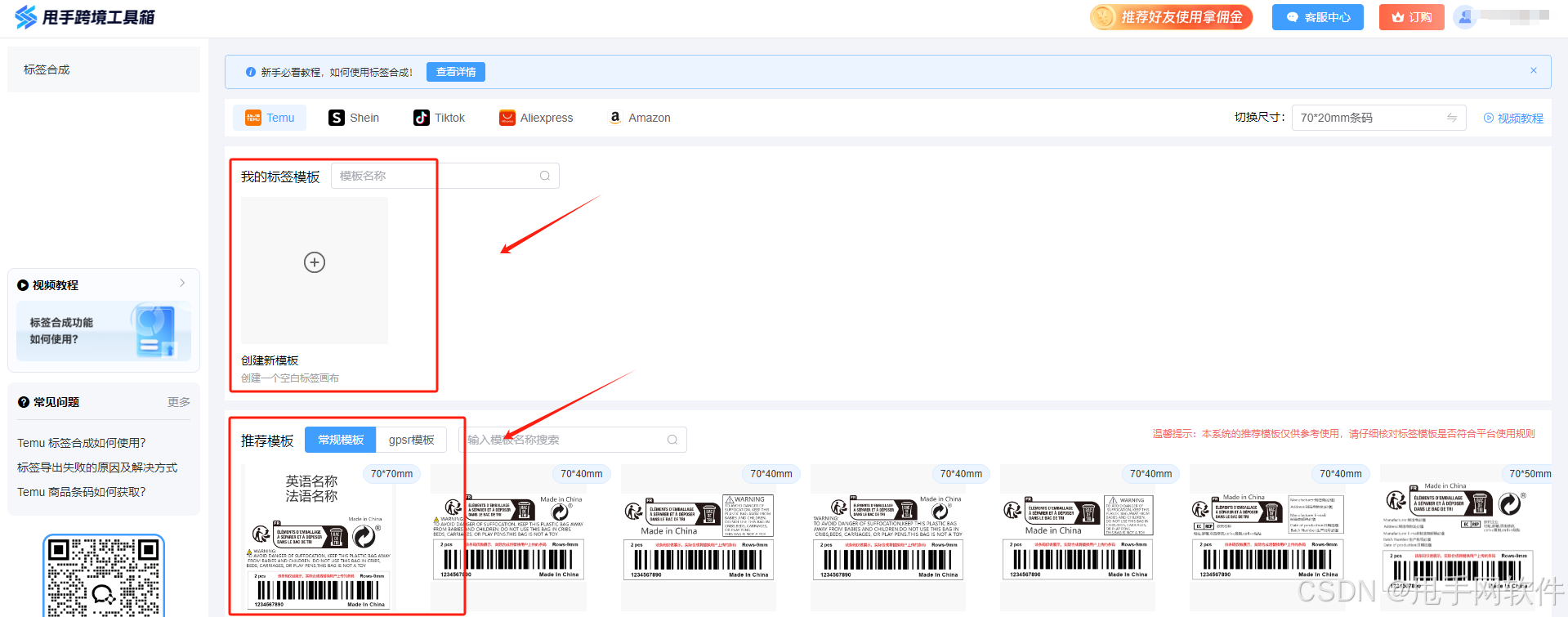
编辑界面功能介绍:
编辑界面支持自定义线条、矩形、文字、图片、警示语等,也支持保存标签或是条码标签合成。
请注意!!!若出现文字无法编辑的情况,请看下模板上是否存在【矩形框】;
若有【矩形框】请选中后,选择【图层】--【图层置底】后,再 进行编辑文字!

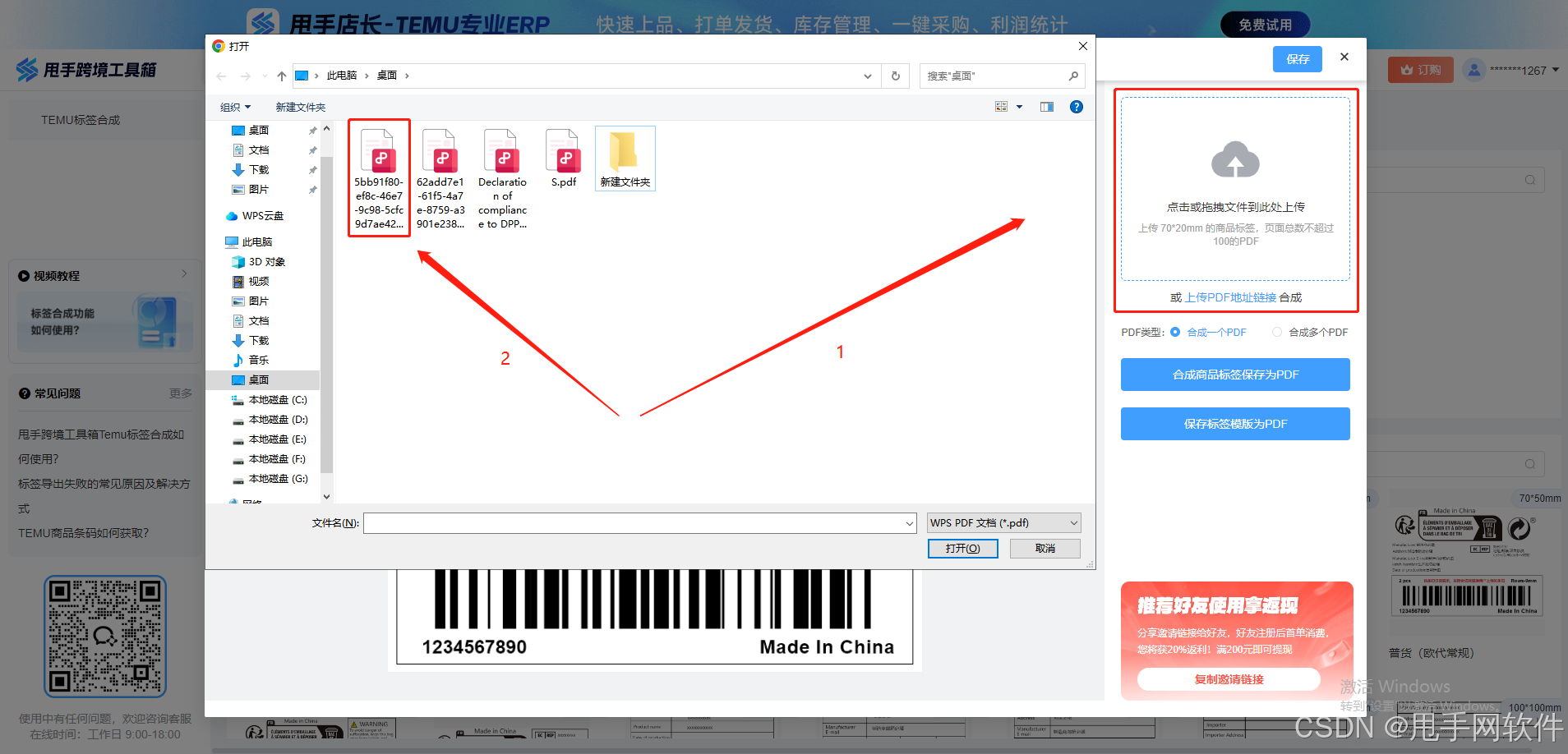
3、上传发货条形码,一键合成
发货条形码支持批量上传,备货时可批量打印,另存为PDF即可。
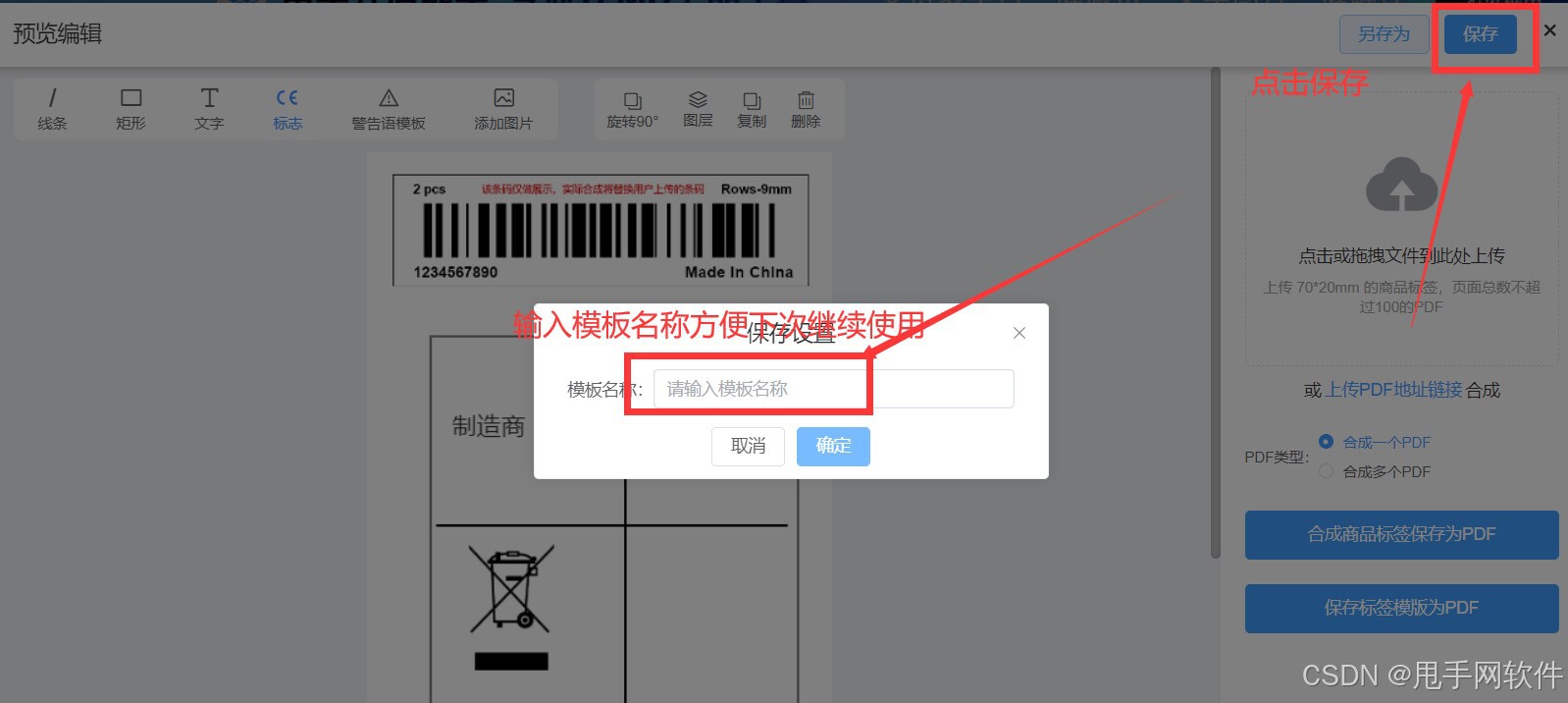
4、保存模板
系统模板被修改后,为方便下次直接找到需要的模板合成标签,点击【保存】,输入模板名称,可保存为自己的标签模板,方便下次使用。
注意!!!如果不保存,直接关闭,则下次模板信息需要重新修改。

















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









