






目录
一、项目介绍
1.项目背景:
本项目旨在开发一个垃圾分类器,通过使用深度学习模型对垃圾图片进行分类,帮助人们更好地理解和处理垃圾问题。垃圾分类是一个重要的环保议题,通过自动化和智能化的方法,可以提高垃圾分类的准确性和效率。
2.项目目的:
- 利用深度学习技术,训练一个垃圾分类模型,能够准确识别不同种类的垃圾。
- 开发一个用户界面,方便用户选择垃圾图片并查看分类结果。
- 提供实时反馈,帮助用户更好地了解垃圾分类的重要性和方法。
3.项目实现:
- 数据处理:使用ImageDataGenerator对数据集进行预处理,包括缩放、翻转、裁剪等操作,以增加数据的多样性和鲁棒性。
- 模型创建:采用预训练的VGG16模型作为基础网络,添加自定义的全连接层进行分类任务。通过冻结部分层,保留VGG16的特征提取能力,同时减少计算量。
- 模型训练:使用SGD优化器和交叉熵损失函数进行模型训练,迭代50个epoch以提高模型性能。
- 模型评估:使用验证集对模型进行评估,计算损失和准确率,确保模型的泛化能力。
- 预测功能:通过加载训练好的模型,对输入的垃圾图片进行分类预测,并返回分类结果。
- 用户界面:使用tkinter库创建一个图形用户界面,方便用户选择垃圾图片并查看分类结果。
4.数据来源:
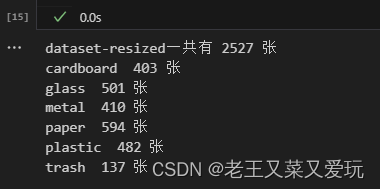
数据集dataset-resized,通过自行采集和从公共数据集获取 ,分别存放着纸板、玻璃、 金属、纸张、塑料、其他垃圾的图片
5.网络结构:
该神经网络主要由两部分组成:VGG16预训练模型和自定义的全连接层。VGG16预训练模型用于提取图像特征,自定义的全连接层用于进行分类任务。具体结构如下:
VGG16预训练模型:使用VGG16模型作为基础,加载在ImageNet数据集上预训练的权重。冻结前10层的权重,使其在训练过程中不发生改变,以保留这些层的特征提取能力。
自定义全连接层:包括一个输入层、一个展平层、一个具有256个神经元的全连接层、一个Dropout层(丢弃率为0.5)和一个具有6个神经元的输出层(对应6个类别)。
为什么采用这种结构:
VGG16预训练模型在图像分类任务中表现优秀,具有较高的准确率。通过使用预训练模型,可以节省大量计算资源和时间。
冻结预训练模型的前10层,可以保留这些层的特征提取能力,同时减少计算量。
添加自定义的全连接层,使得网络能够适应具体的分类任务。
使用Dropout层可以有效防止过拟合现象的发生。
6.损失函数:
损失函数选择为categorical_crossentropy,这是一种多分类任务常用的损失函数,可以衡量预测概率分布与实际概率分布之间的差异。
7.超参数调节过程:
优化器:尝试了SGD、Momentum SGD、RMSprop和Adam等优化器,最终选择了SGD优化器,因为它在训练过程中收敛速度较快且稳定性较好。
学习率:初始学习率为0.001,使用学习率衰减策略,每10个epoch衰减一次,衰减率为0.1。尝试了不同的学习率,如0.01、0.001等,最终发现0.001的学习率可以使模型的训练效果最佳。
批次大小:尝试了32、64、128三个批次大小,最终选择了32,因为这个批次大小下模型的训练速度和模型的效果都达到了较好的平衡。
迭代次数:尝试了10、50、100等迭代次数,最终选择了50,因为在这个迭代次数下模型的训练效果较好,且训练时间适中
迭代10次:![]()
迭代50次:![]()
迭代100次:![]()
在训练过程中出现了轻微的过拟合现象,通过增加Dropout层(丢弃率为0.5)来解决。
在整个训练过程中没有出现明显的梯度消失或梯度爆炸的现象。
此外还尝试了ResNet50模型:
![]()
VGG16模型在ImageNet数据集上进行了预训练,ResNet50没有进行预训练。VGG16模型的深度和复杂度也比ResNet50更高,可能更适合这个任务。
二、系统实现
1.主要代码
import os
# 导入操作系统模块,用于处理文件和目录相关的操作
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
#禁用TensorFlow中的OneDNN优化,我在运行的时候遇到兼容性问题,设置环境变量'TF_ENABLE_ONEDNN_OPTS'的值为'0',可以禁用OneDNN优化,以避免这个问题
from tensorflow.keras.layers import Input, Dense, Flatten, Dropout, Conv2D, MaxPooling2D
# 从 TensorFlow 的 Keras 库中导入各种层类型,用于构建神经网络模型
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 导入用于图像数据增强和预处理的类
from tensorflow.keras.callbacks import TensorBoard
# 导入 TensorBoard 回调函数,用于可视化训练过程
from tensorflow.keras.models import load_model, Model, Sequential
# 导入用于加载、创建和操作模型的类
from tensorflow.keras.optimizers import SGD
# 导入随机梯度下降优化器
from tensorflow.keras.applications.vgg16 import VGG16
# 导入预训练的 VGG16 模型
import matplotlib.pyplot as plt
# 导入用于绘图的模块
import glob, os, cv2, random, time
# 导入用于文件操作、图像处理和其他相关操作的模块
import numpy as np
# 导入数值计算库
# 数据处理函数
def processing_data(data_path):
"""
数据处理
:param data_path: 数据集路径
:return: train, test:处理后的训练集数据、测试集数据
"""
train_data = ImageDataGenerator(
rescale=1. / 255,
# 将图像像素值缩放到 0 到 1 之间
shear_range=0.1,
# 随机错切变换的范围
zoom_range=0.1,
# 随机缩放的范围
width_shift_range=0.1,
# 随机水平平移的范围
height_shift_range=0.1,
# 随机垂直平移的范围
horizontal_flip=True,
# 随机水平翻转
vertical_flip=True,
# 随机垂直翻转
validation_split=0.1,
# 划分验证集的比例
)
validation_data = ImageDataGenerator(
rescale=1. / 255,
# 验证集也进行像素值缩放
validation_split=0.1)
train_generator = train_data.flow_from_directory(
directory=data_path,
# 数据集的目录
target_size=(150, 150),
# 统一图像的大小
batch_size=32,
# 每个批次的样本数量
class_mode='categorical',
# 类别模式为多类别
subset='training',
# 表示这是训练子集
seed=42)
validation_generator = validation_data.flow_from_directory(
directory=data_path,
target_size=(150, 150),
batch_size=32,
class_mode='categorical',
subset='validation',
# 表示这是验证子集
seed=42)
return train_generator, validation_generator
# 返回处理后的训练集和验证集生成器
# 创建模型函数
def create_model():
vgg16_model = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3))
# 加载预训练的 VGG16 模型,不包括顶部全连接层,指定输入形状
# 冻结 VGG16 模型的前 10 层
for layer in vgg16_model.layers[:10]:
layer.trainable = False
top_model = Sequential([
Input(shape=vgg16_model.output_shape[1:]), # 首先定义输入层的形状
Flatten(),
# 展平层
Dense(256, activation='relu'),
# 全连接层,256 个神经元,激活函数为 ReLU
Dropout(0.5),
# 随机失活层,防止过拟合
Dense(6, activation='softmax')
# 输出层,6 个神经元,激活函数为 softmax 用于多类别分类
])
model = Sequential([
vgg16_model,
top_model
])
model.compile(
optimizer=SGD(learning_rate=1e-3, momentum=0.9),
# 使用随机梯度下降优化器,指定学习率和动量
loss='categorical_crossentropy',
# 损失函数为多类别交叉熵
metrics=['accuracy']
# 评估指标为准确率
)
return model
# 返回创建好的模型
# 训练模型函数
def train_model(model, train_generator, validation_generator, save_model_path):
history = model.fit(
x=train_generator,
epochs=50, # 修改迭代次数为 50
validation_data=validation_generator
)
model.save(save_model_path + '.keras')
return history
# 训练模型并保存,返回训练历史
# 评估模型函数
def evaluate_model(validation_generator, save_model_path):
model = load_model(save_model_path + '.keras')
loss, accuracy = model.evaluate(validation_generator)
print("\nLoss: %.2f, Accuracy: %.2f%%" % (loss, accuracy * 100))
# 加载模型并在验证集上评估,打印损失和准确率
# 预测函数
def predict(img_path):
target_size = (150, 150)
# 使用 OpenCV 读取和调整图像大小
img = cv2.imread(img_path) # 读取图像文件
img = cv2.resize(img, target_size) # 调整图像大小
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 转换图像格式为 RGB
img = np.array(img).astype('float32') / 255.0 # 将图像转换为 numpy 数组并归一化
img = np.expand_dims(img, axis=0) # 扩展维度,适应模型输入
model_path = 'esults/knn.keras'
try:
# 测试用
model_path = os.path.realpath(__file__).replace('main.py', model_path)
except NameError:
model_path = './' + model_path
model = load_model(model_path)
y = model.predict(img)
labels = {0: '纸板/可回收垃圾', 1: '玻璃/可回收垃圾', 2: '金属/可回收垃圾', 3: '纸张/可回收垃圾', 4: '塑料/可回收垃圾', 5: '其他垃圾'}
prediction = labels[np.argmax(y)]
return prediction
# 根据输入的图像路径进行预测并返回分类结果
# 主函数
def main():
data_path = "E:/computer-vision/dataset-resized"
save_model_path = 'esults/knn'
train_generator, validation_generator = processing_data(data_path)
model = create_model()
history = train_model(model, train_generator, validation_generator, save_model_path)
evaluate_model(validation_generator, save_model_path)
if __name__ == '__main__':
main()
代码首先导入所需的库,然后定义数据处理函数、创建模型函数、训练模型函数、评估模型函数和预测函数。最后在主函数中调用这些函数完成整个流程。
2.结果展示
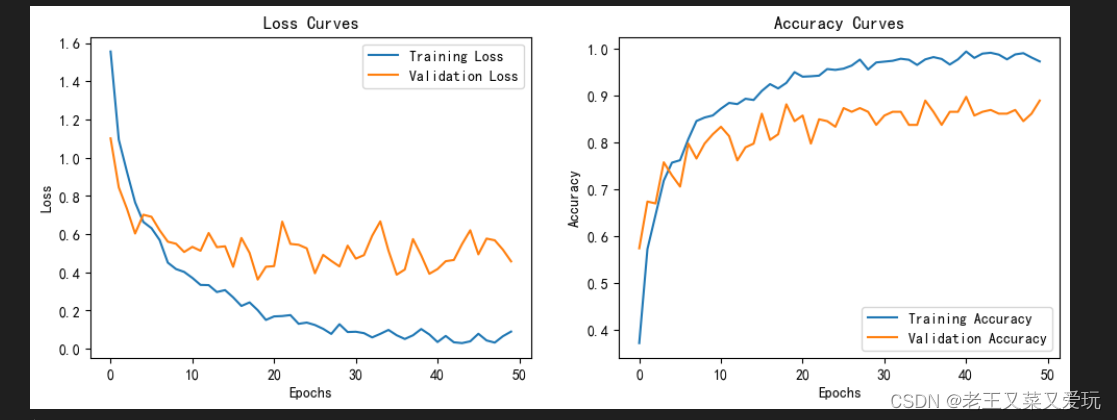
图中可以看出,训练损失(橙色线)随着时间(或训练轮数,即Epochs)的增加而逐渐降低,这表明模型在训练集上的表现正在改善。而验证损失(蓝色线)虽然总体上也在下降,但下降的速度较慢,且有一些波动,说明模型在未见过的验证集上的表现有所提升,但不够稳定。
总体来说模型在训练集上的表现持续改善,但在验证集上的表现改善速度较慢且不稳定,这可能意味着需要调整模型或训练策略以提高模型的泛化能力。
三、GUI界面
页面代码:
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageTk
def browse_image():
global image_path
# 打开文件对话框,选择图片文件
image_path = filedialog.askopenfilename()
# 使用PIL库打开图片
img = Image.open(image_path)
# 调整图片大小为200x200像素
img = img.resize((200, 200), Image.ANTIALIAS)
# 将图片转换为PhotoImage对象
img = ImageTk.PhotoImage(img)
# 更新面板显示的图片
panel.config(image=img)
# 保存图片对象,防止被垃圾回收
panel.image = img
def predict_image():
# 调用predict函数进行预测
prediction = predict(image_path)
# 更新结果标签的文本
result_label.config(text=f"属于: {prediction}")
# 创建主窗口
root = tk.Tk()
root.title("图像分类-垃圾分类器")
# 创建选择图片按钮,点击时调用browse_image函数
browse_button = tk.Button(root, text="选择图片", command=browse_image)
browse_button.pack()
# 创建图片显示面板
panel = tk.Label(root)
panel.pack()
# 创建预测按钮,点击时调用predict_image函数
predict_button = tk.Button(root, text="看一看属于什么垃圾", command=predict_image)
predict_button.pack()
# 创建结果标签,用于显示预测结果
result_label = tk.Label(root, text="属于: ")
result_label.pack()
# 设置窗口大小
root.geometry("400x300")
# 进入主循环,等待用户操作
root.mainloop()
这段代码是一个简单的图像分类器界面,使用tkinter库创建了一个图形用户界面(GUI)。以下是代码的详细实现过程:
1. 导入所需的库和模块:首先导入tkinter库,用于创建GUI界面;导入filedialog模块,用于打开文件对话框;导入PIL库中的Image和ImageTk模块,用于处理图像。
2. 定义browse_image()函数:该函数用于打开文件对话框,选择一张图片,并将其显示在GUI界面上。首先,使用filedialog.askopenfilename()函数获取图片的路径;然后,使用Image.open()函数打开图片;接着,使用resize()函数将图片大小调整为200x200像素;最后,使用ImageTk.PhotoImage()函数将图片转换为Tkinter可以显示的格式,并更新panel的image属性。
3. 定义predict_image()函数:该函数用于预测选中的图片属于什么垃圾。首先,调用predict()函数进行预测,并将结果存储在prediction变量中;然后,更新result_label的text属性,显示预测结果。
4. 创建主窗口:使用tk.Tk()创建一个主窗口,并设置窗口标题为"图像分类-垃圾分类器"。
5. 创建按钮和标签:使用tk.Button()和tk.Label()分别创建"选择图片"、"看一看属于什么垃圾"按钮和显示图片、预测结果的标签。
6. 布局组件:使用pack()方法将按钮和标签添加到主窗口中,并设置窗口的大小为400x300像素。
7. 运行主循环:使用root.mainloop()启动GUI的主循环,使程序持续运行并响应用户操作。
通过这个简单的图像分类器,用户可以选择一个图片文件,点击"选择图片"按钮加载图片,然后点击"看一看属于什么垃圾"按钮进行预测,最后在界面上显示预测结果。

















 7793
7793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









