






一.内置函数
聚合函数:count(),countDistinct(),avg(),max(),min()
集合函数:sort_array、explode
日期,时间函数:hour、quarter、next_day
数学函数:asin、atan、sqrt、tan、round
开窗函数:row_number
字符串函数:concat、format_number、regexp_extract
其他函数:isNaN、sha、randn、callUDF
主要导入包:org.apache.spark.sql.functions._
案例一:
//模拟用户访问日志信息
val accessLog = Array(
“2016-12-27,001”,
“2016-12-27,001”,
“2016-12-27,002”,
“2016-12-28,003”,
“2016-12-28,004”,
“2016-12-28,002”,
“2016-12-28,002”,
“2016-12-28,001”
)
//创建spark运行配置对象
val conf = new SparkConf().setMaster("local[*]").setAppName("linxi2")
//创建spark上下文环境对象(链接对象)
val sc = new SparkContext(conf)
val spark = SparkSession.builder().master("local[*]").appName("dsD")
.getOrCreate()
//定义一个用户访问信息
val accesslog = Array(
"2016-12-27,001",
"2016-12-27,001",
"2016-12-27,002",
"2016-12-28,003",
"2016-12-28,004",
"2016-12-28,002",
"2016-12-28,002",
"2016-12-28,001"
)
//根据集合数据生成RDD
val RDD:RDD[Row] = sc.makeRDD(accesslog).map(x => {
val strings = x.split(",")
Row(strings(0), strings(1).toInt)
})
//定义DataFrame的结构
val structType:StructType = new StructType(Array(StructField("day",StringType),StructField("userId",IntegerType)))
//根据数据以及Schema信息生成DataFrame
val frame:DataFrame = spark.createDataFrame(RDD,structType)
frame.printSchema() //结果一
frame.show() //结果二
//导入Spark SQL 内置的函数
import org.apache.spark.sql.functions._
//groupBy():分组 agg():在整体DataFrame不分组聚合 count():计数 as:改名 select:查看列 "day" "pb"
//结果三
frame.groupBy("day").agg(count("userId").as("pv")).select("day","pv").show()
结果:

案例二.
使用case class(样例类),操作内置函数
//导入Spark SQL 内置的函数
import org.apache.spark.sql.functions._
//样例类
case class Student(id:Integer,name:String,gender:String,age:Integer)
object LianXi2 {
def main(args: Array[String]): Unit = {
//创建spark运行配置对象
val conf = new SparkConf().setMaster("local[*]").setAppName("linxi2")
//创建spark上下文环境对象(链接对象)
val sc = new SparkContext(conf)
val spark = SparkSession.builder().master("local[*]").appName("dsD")
.getOrCreate()
//seq:对值包装
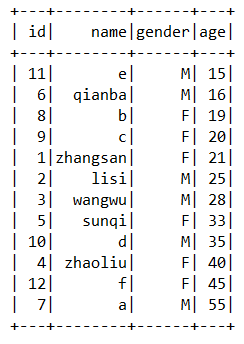
val students = Seq(Student(1, "zhangsan", "F", 21), Student(2, "lisi", "M", 25),
Student(3, "wangwu", "M", 28), Student(4, "zhaoliu", "F", 40),
Student(5, "sunqi", "F", 33), Student(6, "qianba", "M", 16)
, Student(7, "a", "M", 55), Student(8, "b", "F", 19)
, Student(9, "c", "F", 20), Student(10, "d", "M", 35),
Student(11, "e", "M", 15), Student(12, "f", "F", 45))
//导入spark包
import spark.implicits._
//将students转变成DataFrame 方法一
//toDF()方法将RDD转换为DataFrame,DataFrame函数提供很多方法
//val frame = students.toDF()
//将students转变成DataFrame 方法二
//用createDataFrame 产生DataFrame
val frame = spark.createDataFrame(students)
//groupBy:分组 count():统计数量
val frame1 = frame.groupBy("gender","age").count()
frame1.printSchema()//打印表结构
frame1.show()//打印表
//SQL语句
//select age from student order age asc/desc
frame.sort("age").show() //sort:指定列排序 默认升序
frame.sort($"age".desc).show //sort:指定列排序 desc降序
//SQL语句
//select avg(age) as avgage from students group by gender order by avgage desc
//groupBy:分组 agg():在整体DataFrame不分组聚合 sort:排序
frame.groupBy("gender").agg(avg("age").as("avgage"))
.sort($"avgage".asc).show()

















 2043
2043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









