







0. 说在前面
对于Volley的介绍,网络上有很多,在这里我就不多废话,直接切入到我们进入的重点,在接下来的几篇博客,我将竭尽我的能力去彻底的分析一下Volley的奥秘,可能由于我的水平有限,还是不能与大神们的博客相提并论,但是我的分析还在站在一个新手的角度,最大可能的去让自己理解,也让有些迷惑的同学们去理解,网上看了很多介绍Volley的框架的文章,有些文章讲的很好,但是一开始没有给一个整体的概念,而是直接切入到了源码的层次,我今天要做的就是按照Volley的工作流程,先大概的从源码的层次去了解一下,其工作的原理,随后几篇文章可能会从自定义请求和一些Volley的封装。
开始!!!!
1. 首先我们看一下工作流程图,这也是GOOGLE I/O大会放出的一张图,下面的分析也是基于该图。
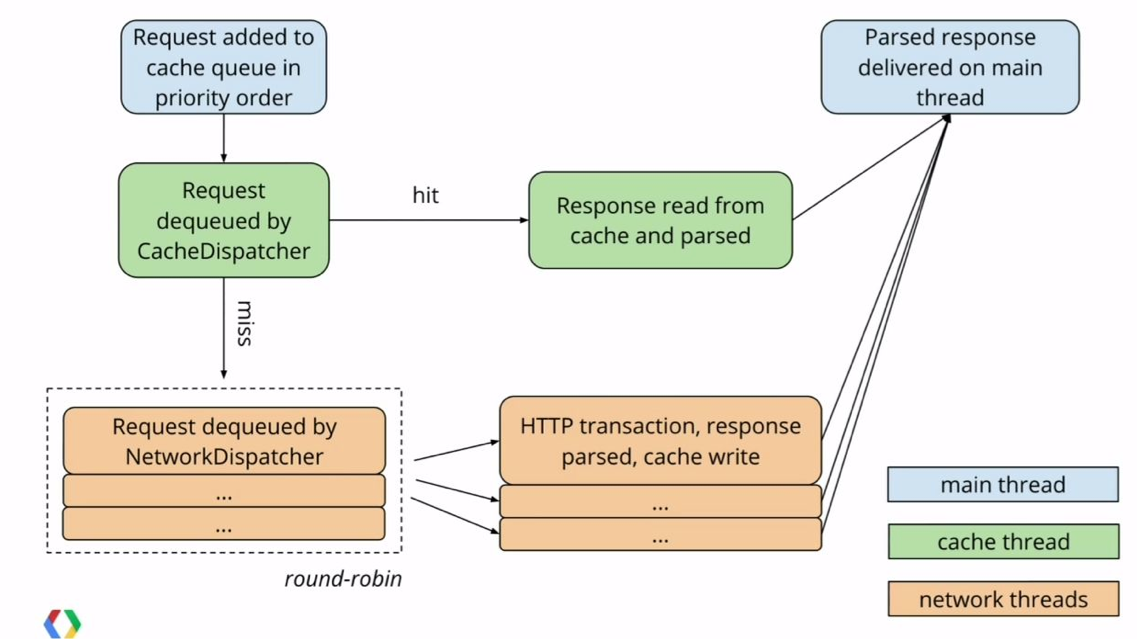
从使用的流程我们知道,首先我们会调用Volley类的newRequestQueue方法,当然,这个类也是Volley框架暴露出来的入口,因为,我们在执行请求时使用的处理队列就是从该方法返回出来的。下面我们看看它到底做了些什么工作?
newRequestQueue(Context context, HttpStack stack, int maxDiskCacheBytes)
我们只需看这个3个参数的方法即可,因为其他参数方法也是直接调用之。
这个方法里面的语句不是很多,我们挑一些重要的语句进行分析;
if (stack == null) {
if (Build.VERSION.SDK_INT >= 9) {
stack = new HurlStack();
} else
stack = new HttpClientStack(AndroidHttpClient.newInstance(userAgent));
}
}
在这里我们先解释一下HttpStack这个接口的作用:
该接口是进行Http请求的,该接口所做的具体工作就是发送Http请求,并将请求的结果返回出来,我们可以理解为它是一个对Http请求的处理,这个之后我会有一些更加细致的说明,现在暂且说到这里。
从上面的语句我们可以发现,这个处理接口有两种具体的实现,一种是HurlStack,另一种就是HttpClientStack。前者是通过HttpURLConnection实现的Http处理类,后一种是通过HttpCient实现的Http处理类。二者的选择是根据开发时使用的SDK版本所决定的(当然如果你自己传入参数时指定了HttpStack时就不会交于系统选择了),选择的原则是当SDK大于等于9时,采用HttpURLConnection的处理方式,而9之前就使用HttpClientStack的处理方式,原因是在9之前,HttpURLConnection有一些小的BUG,造成使用这种方式的请求不稳定,在官方的注释里你可以看到“Prior to Gingerbread, HttpUrlConnection was unreliable.”
再往下来看:
Network network = new BasicNetwork(stack);
下面解释一下NetWork这个接口:
public interface Network {
/**
* Performs the specified request.
* @param request Request to process
* @return A {@link NetworkResponse} with data and caching metadata; will never be null
* @throws VolleyError on errors
*/
public NetworkResponse performRequest(Request<?> request) throws VolleyError;
}
从上面的源码,你会发现这个接口只有一个方法。且该方法就是处理指定的请求,但是并不依赖于特有的请求方式,这是一个很好的设计,通过这种设计,将处理请求者与具体的请求任务相分离,这就大大的增加了扩展性,因为对于HttpStack而言,它只是具有了网络请求的能力,而通过NetWork的包装后就具有了通过这种能力做具体的工作的能力。它的扩展性就可以体现在你可以创建一个同样具有网络请求能力的处理者来满足你的需要,只需NetWork的包装,直接就可以与Volley的整个框架融合在一起。
下面的语句就是在Volley中非常重要的一个功能体: RequestQueue
RequestQueue queue;
if (maxDiskCacheBytes <= -1)
{
// No maximum size specified
queue = new RequestQueue(new DiskBasedCache(cacheDir), network);
}
else
{
queue = new RequestQueue(new DiskBasedCache(cacheDir, maxDiskCacheBytes), network);
}
queue.start();
上句很简单,就是通过是否指定最大磁盘缓存大小来决定创建请求队列的方式,然后,开启队列。这本没有什么好说的,但是看到RequestQueue对整个框架的重要性,我觉得有必要去了解一下它的源代码。
在分析之前,我们有必要简单的了解一下在该类中的几个成员变量:
NetworkDispatcher mDispatchers
一个线程,用于调度处理走网络的请求。启动后会不断从网络请求队列中取请求处理,队列为空则等待,请求处理结束则将结果传递给ResponseDelivery去执行后续处理,并判断结果是否要进行缓存。
CacheDispatcher mCacheDispatcher
一个线程,用于调度处理走缓存的请求。启动后会不断从缓存请求队列中取请求处理,队列为空则等待,请求处理结束则将结果传递给ResponseDelivery去执行后续处理。当结果未缓存过、缓存失效或缓存需要刷新的情况下,该请求都需要重新进入NetworkDispatcher去调度处理。
ResponseDelivery mDelivery
返回结果分发接口,目前只有基于ExecutorDelivery的在入参 handler 对应线程内进行分发。
看到上面的两个分发器你有没有一些疑问?为什么会有两个分发器?
如果你有这样的疑问,请上拉,看最初的那张流程图,当缓存调度线程从队列中取出一个请求的时候会判断当前的请求是否存在与缓存中,如果存在缓存就直接从缓存中读取数据并返回,否则的话就交由网络调度线程去处理,此时网络调度线程就会从请求网络,获取网络中的数据,处理返回的数据,如果允许写入缓存的话就写入缓存(默认开启缓存的写入)。
我们一会可以通过源码来证明我们的分析。
下面看一下 在newRequestQueue方法中使用的RequestQueue的start方法的源码。
public void start() {
stop(); // Make sure any currently running dispatchers are stopped
mCacheDispatcher = new CacheDispatcher(mCacheQueue, mNetworkQueue, mCache, mDelivery);
mCacheDispatcher.start();
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue, mNetwork,
mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
networkDispatcher.start();
}
}
首先会调用stop()方法,确保当前运行的调度器都被关闭。
然后创建了一个缓存调度,并开启。
在创建一个网络调度,并开启。
其实,在这个方法里,就仅仅只是创建了两个调度器,一个是缓存调度,另一个就是网络调度,我在刚才对这两个类做了一些简单的说明,我们可以知道,实际上这两个类是一个线程,调用了线程的start方法就是运行了一个线程,打开各自的run方法,你会发现各自的run方法都是死循环,在这里,笔者只对网络请求的调度工作做说明,对于缓存的调度大家自己分析吧!
之前,我想介绍一个数据结构 BlockingQueue:
特殊的队列,如果BlockingQueue是空的,从BlockingQueue取东西的操作将会被阻断进入等待状态,直到BlockingQueue进了东西才会被唤醒,同样,如果BlockingQueue是满的,任何试图往里存东西的操作也会被阻断进入等待状态,直到BlockingQueue里有空间时才会被唤醒继续操作。(来源于网络)
下面分析网络调度中的流程:
1. 从BlockingQueue中取出一个请求;
request = mQueue.take();
2. 执行网络请求,得到请求的返回数据
NetworkResponse networkResponse = mNetwork.performRequest(request);
3. 解析网络请求数据
Response<?> response = request.parseNetworkResponse(networkResponse);
4. 判断是否需要缓存,默认支持缓存,可通过request.setShouldCache(boolean)来指定此次请求是否缓存来禁用此次缓存。如果本次请求支持缓存,则将本次请求的响应写入到缓存中
if (request.shouldCache() && response.cacheEntry != null) {
mCache.put(request.getCacheKey(), response.cacheEntry);
request.addMarker("network-cache-written");
}
5. 将结果传递给主线程
mDelivery.postResponse(request, response);
上述就是网络调度的工作原理,对于缓存的调度也请读者自己分析。
对于上述的第五步,将结果传送到主线程我觉得还是有必要说一下的,
对于框架中的ResponseDelivery只有一个实现类-ExecutorDelivery
下面我们就注重分析ExecutorDelivery的源代码
public void postResponse(Request<?> request, Response<?> response, Runnable runnable) {
request.markDelivered();
request.addMarker("post-response");
mResponsePoster.execute(new ResponseDeliveryRunnable(request, response, runnable));
}
最终有效的代码就是线程中:
` public void run() {
// If this request has canceled, finish it and don’t deliver.
if (mRequest.isCanceled()) {
mRequest.finish(“canceled-at-delivery”);
return;
}
// Deliver a normal response or error, depending.
if (mResponse.isSuccess()) {
mRequest.deliverResponse(mResponse.result);
} else {
mRequest.deliverError(mResponse.error);
}
// If this is an intermediate response, add a marker, otherwise we’re done
// and the request can be finished.
if (mResponse.intermediate) {
mRequest.addMarker(“intermediate-response”);
} else {
mRequest.finish(“done”);
}
// If we have been provided a post-delivery runnable, run it.
if (mRunnable != null) {
mRunnable.run();
}
}`
首先会判断当前的请求是否已经被删除了,如果被删除了就什么也不做,如果请求成功,就交由当前request去传递给主线程,这也就是通过每个具体的请求都要使用的方法deliverResponse(),
在request的具体实现就是:
@Override
protected void deliverResponse(T response) {
if (mListener != null) {
mListener.onResponse(response);
}
}
而mListener就是我们在new出一个具体请求方式的时候传入了监听器,至此就将结果的处理交给了主线程。
对于整个流程,我们再重新理一下。
- 首先通过Volley的newRequestQueue创建一个RequestQueue,该RequestQueue可以作为整个app的请求队列来用,所以可以一开始在Application中注册一下,随后在项目的其他位置就可以直接使用该队列去处理我们的网络请求,当然你要对Volley进行一下简单的封装,在创建队列的同时,会创建两个调度器,缓存调度器和网络调度器,并阻塞执行,等待着处理并分发请求。
- 创建一个请求,并把请求添加到上述的队列中。
- 首先缓存调度会判断该请求是否存在于缓存中,如果存在于缓存中,就直接将结果传递给主线程。
- 如果在缓存调度中没有命中,就提交到网络调度,由网络调度调用网络请求,之后将网络请求的结果返回给主线程。















 476
476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









