







我有一篇文章很不负责的,没有头绪的分析了一些Volley的源码。我自己回头去看了一下,于是就把他删掉了,于是就有了今天的这篇文章。
Volley的使用步骤
- 创建一个RequestQueue对象。
- 创建一个Request对象。
- 将Request对象添加到RequestQueue里面。
我们可以看到使用非常的简单,顺着这个逻辑我们在来看一遍源码
1.创建RequestQueue对象
RequestQueue mQueue = Volley.newRequestQueue(context);在newRequestQueue方法中创建了一个Cache一个newWork,然后用这两个创建了一个RequestQueue,随后启动这个请求队列,这个队列启动的是5个线程(默认是1个处理走缓存的请求的线程,4个处理网络请求的线程,其实这里可以自己改,走缓存的请求个人觉得1个就足够,处理网络请求的线程数可以根据cpu核数等因素自己来确定一个合理值),在5个线程中主要的工作就是在自己的while循环中不断的读取队列中的内容(1个走缓存的请求队列,之后都称为A,1个走网络的请求队列,之后都称为B),也就是1个线程不断从A中读数据,4个线程不断从B中读数据。A、B中没有数据的时候,也就是take拿到的数据为空时,take就会阻塞所在的线程,take不为空的话,就进行各自的处理,一个走缓存,一个走网络。
走缓存:
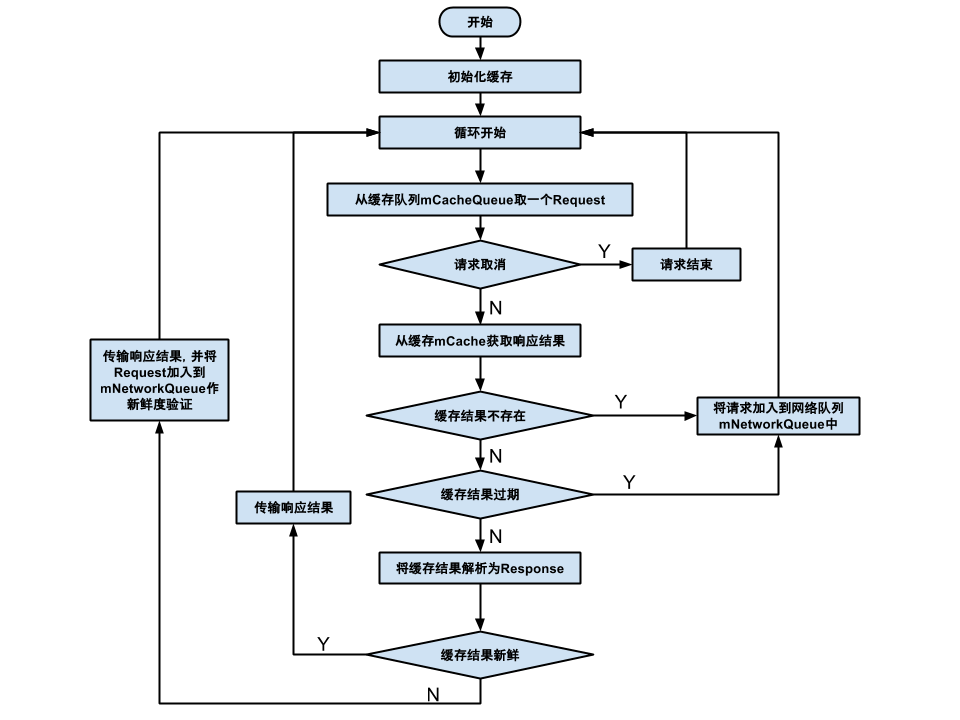
走网络:
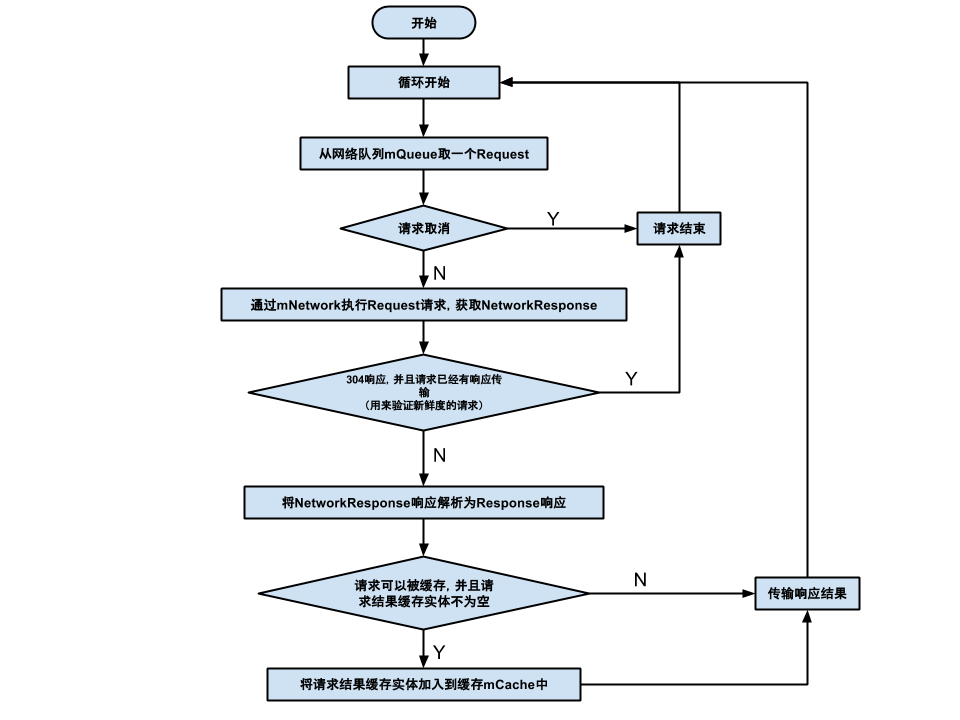
其中一些细节可能大家不太明白,比如:走网络中的304响应、为什么使用队列不用线程池(其实是可以用线程池),像上面这些比较细枝末节的在之后会讲解。
2.创建一个Request对象
这一部分是我当时读源码的时候比较难受的一部分,里面有很多我当时不知道什么用的参数,有http请求报文相关的参数,而且和network紧密相连,而这个network对于我这种一开始http协议不怎么了解的人来说简直就是痛苦,什么请求首部、请求主体,完全就是想要头大,难怪很多人都是建议不要自己来写网络请求框架,是有道理的不容易写,更不容易写好,我也就不谈自己对于其中http请求实现的粗浅的理解,不误人子弟了,有兴趣大家可以和我一样去啃http权威指南。对于我们想要去实现自己的请求,主要关注的就4个方法:
abstract protected Response<T> parseNetworkResponse(NetworkResponse response);子类重写此方法,将网络返回的原生字节内容,转换成合适的类型。此方法会在工作线程中被调用。
abstract protected void deliverResponse(T response);子类重写此方法,将解析成合适类型的内容传递给它们的监听回调。
public byte[] getBody()
protected Map<String, String> getParams()上述两个方法就是写请求主体的内容。像一般我们知道的post是需要有请求主体的
3.将Request对象add到RequestQueue里面
这个将请求add到RequestQueue其实就没什么好讲的,就是将请求添加到队列中。但这里还是展开具体的讲一讲比较能帮助理解,首先,执行添加的add函数之后,就将这个请求和这个请求队列相关联(方便之后结束请求),随后将此请求添加到mCurrentRequests 这个集合中,我们看一下他的声明
private final Set<Request<?>> mCurrentRequests = new HashSet<Request<?>>();它的作用是维护了一个正在进行中,尚未完成的请求集合。因为是set所以其中的请求是不会重复的。
随后给这个请求设置一个请求的标号,判断请求是否要缓存,要就加入到缓存请求队列,否则加入网络请求队列,对于之后重复的请求(前提:要缓存的)都加入到mWaitingRequests 集合中
private final Map<String, Queue<Request<?>>> mWaitingRequests = new HashMap<String, Queue<Request<?>>>();我们再继续讲,将请求添加到请求队列中之后,这个请求就会有很多种后续的可能:请求自然结束(就是请求成功了或者请求失败,我们没有手动的去结束这个请求)、主动结束(比如我们打开一个activity,在其中创建了一个请求添加到队列中,但是我们很快就离开了这个页面,并且我们不想要这个请求还在队列中占用资源,因为它并不重要,于是我们就主动的结束这个请求),结束请求最终调用的是void finish(Request<?> request) 方法,首先从正在进行中请求集合mCurrentRequests中移除该请求。 然后查找请求等待集合mWaitingRequests中是否存在等待的请求,如果存在,则将等待队列移除,并将等待队列所有的请求添加到缓存请求队列中,让缓存请求处理线程CacheDispatcher自动处理。
一开始我读到这里的时候会觉得(如果存在,则将等待队列移除,并将等待队列所有的请求添加到缓存请求队列中,让缓存请求处理线程CacheDispatcher自动处理。)这一步有问题,但仔细理解了之后其实是自己想的太少了,只要最后都执行了请求的finish也就是请求队列的finish方法就不会有问题,所有的请求都会执行。
响应与分发
上面的内容我讲完了创建请求将请求添加到请求队列,并不断从队列中读取请求进行处理,到这里我们自然会问的就是之后呢?对啊!之后呢,请求之后得到响应,并将响应分发给请求者。
响应
响应可以使从网络中拿到数据然后响应,也可以是从Cache中拿到数据然后响应。
首先从简单的开始说起,从Cache中拿到数据然后响应,拿数据的过程不太清楚的看之前的图,拿到了数据之后就需要对其进行解析,使用的是request的parseNetworkResponse方法,这个是可以我们实现的(这也是Volley之所以好的体现之一吧,高扩展性!),如何解析呢,我们先来看看拿到的数据是什么样的:
byte[] data 请求返回的数据(Body 实体)
String etag Http响应首部中用于缓存新鲜度验证的 ETag
long serverDate Http 响应首部中的响应产生时间
long lastModified 所请求的对象上一次修改的时间
long ttl 缓存的过期时间
long softTtl 缓存的新鲜时间
Map<String, String> responseHeaders 响应的 Headers
boolean isExpired() 判断缓存是否过期,过期缓存不能继续使用
boolean refreshNeeded() 判断缓存是否新鲜,不新鲜的缓存需要发到服务端做新鲜度的检测要解析的就是data 数据,如何解析就根据responseHeaders 和我们自己定义的parseNetworkResponse方法,最终将其转换为我们指定的类型,之后要做的就是讲这个解析得到的响应分发,这是下一部分的内容,下一部分再讲。
注意注意!接下来就是要重点攻克的难关了!网络请求包括它的重试机制

从网络中获取请求的数据,取出一个请求之后执行Basicwork(或者自己实现,只要继承Network接口就行)的performRequest方法,在其中首先取得那些缓存了但是已经过期或者不新鲜了的请求的etag 和 lastModified 两个信息,连同用户自己定义的请求头部(默认的是 User-Agent 字段设置为 App 的 packageName/ {versionCode},就是在Volley.newRequestQueue方法中拿段话)一起添加到请求报文中,这部分是在httpstack对象的performRequest方法中,这个方法我就不具体展开了,就是一套流程下来(建立连接,设置超时时间等等),总之最后返回响应报文给Basicwork的performRequest方法,在其中解析这个响应报文,获取起始行中的状态码和所有首部的信息(以键值对的形式),根据不同的状态码执行不同的操作。下面以状态码分类做进一步的讲解
304
如果是304,表示我们现在拥有的数据就是最新数据了,于是就直接拿取请求中保存的缓存数据创建NetworkResponse返回到NetworkDispatcher就行。
301或者302
301和302的意思就是现有的地址访问不到数据需要重定向(应该是这么说吧,关于http协议我也是菜鸟,有错的话请大家积极的指正啊),至于重定向的地址就从响应报文的首部中获取,首部的信息一开始都解析出来放在了一个map中,拿到这个地址之后给请求设置重定向地址,随后设置代表响应主体的参数的时候也就设置为空
200
如果是200,就直接设置代表响应主体的参数,在前面301或者302的时候是设置响应主体为空,因为就没有得到数据,200的时候就不一样了,他是成功返回数据,所以直接设置,只是要将HttpEntity对象转换为二进制数组,这个转换的过程后续也会再讲,因为会牵扯到ByteArrayPool这个类,可以说是内存复用吧,所以值得单独再讲一讲原理。好了,转换成二进制数组之后创建NetworkResponse返回到NetworkDispatcher
小于200大于299
这些都会抛异常,但是要注意,这一步判断是在上述判断之后,所以304是不会执行到这一步判断的,304在这之前就返回了NetworkResponse,而301和302则会抛出异常,在他们的判断之中做的只是得到重定向的地址,然后给请求设置这个重定向地址。
接下来要关注的就是之后的异常捕获处理了,Basicwork的performRequest方法中有若干个异常,有连接超时,io异常等,这些异常都会被捕获处理,大部分会在其中执行重试机制,说道这个重试机制,我一开始看的时候完全就懵逼了,

都没发现它怎么重试的,上网查又自己看了好几遍才明白,那他是怎么实现重试的呢?
重试机制
让我们再看一遍Basicwork的performRequest方法,阿西吧!!外面有个while死循环,这下就了然了,让我来告诉你吧!首先请求由于连接超时或者重定向之类的导致这次请求失败,于是调用attemptRetryOnException得到请求中的重试策略执行其中的retry方法,默认的实现是没有重试的,失败就失败了,但是看他的默认实现我们就能写出自己的重试策略,首先重试次数加1,超时时间非线性增长的,这个也可以自己来定,第一次2秒第二次就是4秒第三次就8秒,类似这样实现是比较好的方式。当重试的此时大于最大的限制时就抛出异常,也就是跳出循环结束这次请求。大致就是这样的。
讲到这里之后就跳回到了NetworkDispatcher中继续执行了,网络部分返回就两种情况:一是成功返回响应,二是抛出异常。对于异常的话就直接捕获然后分发就行,而对于成功响应,首先成功返回的数据包括响应报文的首部和主体部分、是否有被更改、状态码、这次请求到成功返回所有时间(ms)。将响应成功的数据返回之后,就可以再回去看看一开始走网络的那幅图了。
到此响应的部分就基本差不多了
分发
分发就是拿到数据之后通知用户拿到了数据或者没有拿到,也就是在拿到数据之后执行,那么他也就在两个地方,一个是在cache里拿到数据之后分发,一个是从网络中拿到数据之后。但这个分发不用分开讲,默认实现做的工作就是从工作线程分发数据到ui线程,你可以自己再去实现。总的来说这个没啥好讲的,一看就能懂,所以就这样吧!
下面一幅图可以帮助理解上面的响应和分发
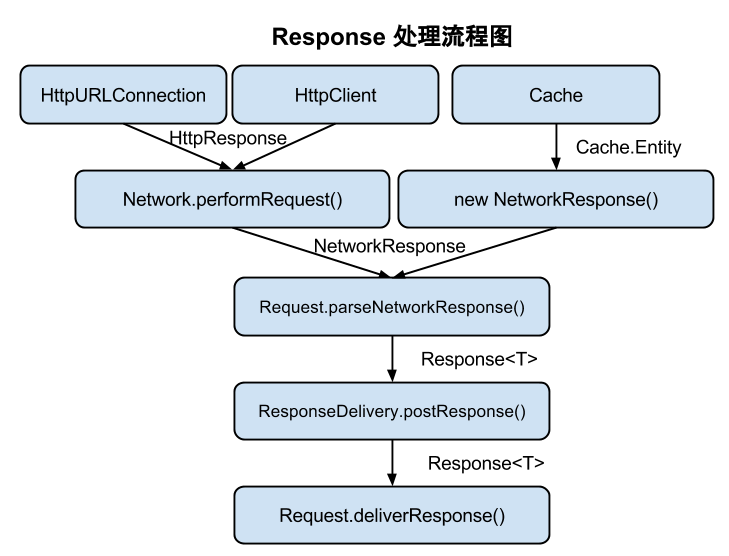
一些细节的讲解
在下面讲解一些比较细的,但是很可能会在阅读源码的时候有问题的点。
为什么在RequestQueue中缓存请求队列和网络请求队列添加数据方法使用的是add而不是put
两个队列声明如下:
private final PriorityBlockingQueue<Request<?>> mCacheQueue = new PriorityBlockingQueue<Request<?>>();
private final PriorityBlockingQueue<Request<?>> mNetworkQueue = new PriorityBlockingQueue<Request<?>>();对于BlockingQueue它的put和add方法是有区别的,add方法在在队列满的时候是直接抛出异常,而put方法是会阻塞,相比之下,RequestQueue基本都是会在ui线程中使用的,如果阻塞就会有anr错误,直接就是程序奔溃,那还是异常比较好一些。(再深入有异常怎么办,好像也没看到异常捕获,我自己也去查了一下,没有查到就没有继续深究,毕竟这种情况基本不会出现,有兴趣可以自己去查查看)
为什么使用工作线程任务队列而不用线程池
不断的创建新的线程销毁线程是很好资源的,所以对于频繁的网络请求就需要复用已有工作线程,这样做同时也可以避免出现同一时间出现大量的线程的情况。就这两点来看,其实是也可以使用线程池的,都能达到要求。但是我们可以先看看Volley的设计目标就是非常适合去进行数据量不大,但通信频繁的网络操作,而对于大数据量的网络操作,比如说下载文件等,Volley的表现就会非常糟糕。从这个目标出发工作线程任务队列适合处理大量耗时较短的任务,并且我个人觉得如果使用线程池的话编写的难度上比使用线程任务队列大,而且就最终的性能上我不觉得会有什么差别,可能就一点:灵活性上来说线程池更加优越,总的来说就是两个能用同样的性能达到同样的效果,当然是选择更容易使用的。
处理走网络的请求中的304响应
304是http响应报文返回时都会携带的一个状态码,304的意思是和服务器的数据比对之后发现没有改变,我们常常会遇到的还有200:表示正确返回,404:没有找到,302:重定向。着一部分其实是http协议的内容,有兴趣的可以去读一下http权威指南这本书,我也正在读,如果自己想要搞一个网站什么的,我觉得是必定要学好http协议的,对于编写http相关程序也是帮助很大。
为什么读取请求队列中请求的5个线程启动之后都指定了优先级
我们可以发现在CacheDispatcher和NetworkDispatcher中都有这么一句话
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);什么意思呢,也就是指定了线程的优先级,不要觉得线程干嘛还要指定优先级啊,不注意使用的话你的ui线程会出现卡顿的情况,详情请看android线程的正确使用姿势看完你就会明白!
NetworkDispatcher中的addTrafficStatsTag方法的作用
跟踪进去你会发现其中使用的是TsafficStats的setThreadStatsTag方法,TsafficStats就是流量监控类,TrafficStats.setThreadStatsTag()方法用来标记线程内部发生的数据传输情况,而且这里是不同的请求都会设置不同的Tag,我们就能比较清楚的通过ddms识别传输峰值所产生的原因,从而去优化我们的网络任务的写法。我自己并没有进行过尝试,也是上网查的,参考:Android—优化下载让网络访问更高效(四),就这个地方要不要去深究我觉得仁者见仁智者见智,优化到一定程度这个点就会有必要去深究,但是一般我觉得这里都可以跳过不看,对于整个Volley的理解基本没什么影响。
为什么要将那些缓存了但是已经过期或者不新鲜了的请求的etag 和 lastModified 两个信息,连同用户自己定义的请求头部一起添加到请求报文中
服务端根据请求时通过If-Modified-Since首部传过来的时间,也就是lastModified ,判断资源文件是否在lastModified 时间 以后 有改动,如果有改动,返回新的请求结果。如果没有改动,返回 304 not modified。这是为了更加准确的获取数据,不要去重复获取相同的数据。etag我不是很了解,但应该也是进行请求再验证,和lastModified 的作用类似,只是lastModified 是判断是否过期,而etag是新鲜度的认证,等我阅读完http权威指南之后我会做确切的解答。在这里可以先将这两个信息理解为帮助服务器做出正确的响应,不要响应给我已经有的数据,如果我已经有这个数据就告诉我304(你已经有这个数据了)。
上面的细节问题都是我自己当时看的时候,会有障碍的地方,所以就列出来给大家提个醒,没有问题的也看看帮我看看我的理解是否有误,如果有朋友还有什么不懂的问题,可以在文章下留言,我会将觉得有必要解释的问题添加到文章中。
今天先到这里,后续更新请看:Volley源码分析二。
参考:这里写链接内容















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









