






【CVPR 2024】联邦学习+基础模型微调
一、摘要
最近,基础模型在多模态学习方面表现出显着的进步。这些模型配备了数百万个(或数十亿个)参数,通常需要大量数据进行微调。然而,由于不同的隐私法规,从不同部门收集和集中训练数据变得具有挑战性。联邦学习 (FL) 作为一种有前途的解决方案出现,使多个客户端能够在不集中本地数据的情况下协同训练神经网络。为了减轻客户端计算负担和通信开销,以前的工作已经调整了 FL 的参数高效微调 (PEFT) 方法。因此,在联邦通信过程中,只有一小部分模型参数被优化和通信。然而,以往的研究大多集中在单一模态上,而忽略了一种常见的现象,即客户之间存在数据异质性。因此,在这项工作中,我们提出了一个针对异构多模态 FL 量身定制的微调框架,称为联邦双自适应教师 (FedDAT)。具体来说,我们的方法利用双适配器教师 (DAT) 通过正则化客户端本地更新并应用相互知识蒸馏 (MKD) 来解决数据异质性,以实现高效的知识转移。FedDAT 是第一个能够为各种异构视觉语言任务实现基础模型的高效分布式微调的方法。为了证明其有效性,我们在四个具有不同类型数据异质性的多模态 FL 基准上进行了广泛的实验,其中 FedDAT 大大优于适用于 FL 的现有集中式 PEFT 方法。
二、动机
解决问题:采用基础视觉-语言预训练模型解决联邦学习中客户端数据模态异构问题。文中以VQA(视觉语言问答)问题举例。
三、方法
3.2 PEFT Method: Adapter
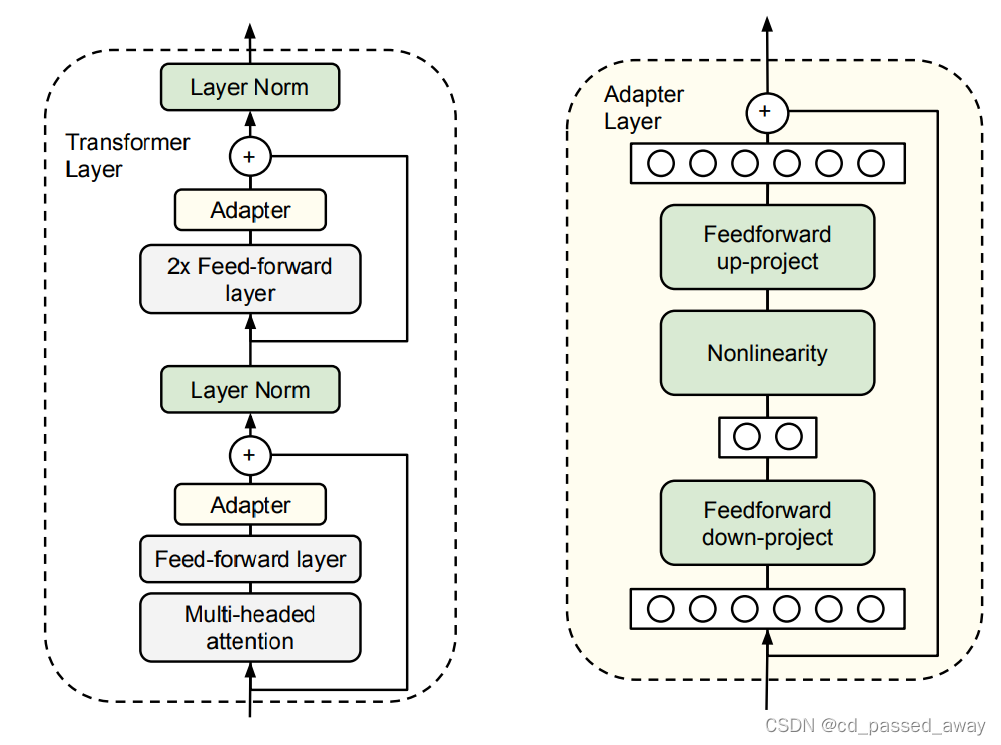
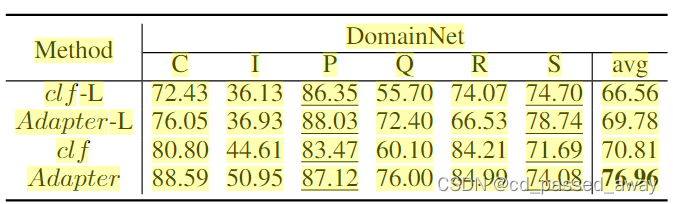
1. Adapter微调更强 2.联邦平均效果优于客户端独立微调 3. 特定于客户端的微调在P和S上比较重要
指出:1. Adapter微调更强 2.联邦平均效果优于客户端独立微调 3. 特定于客户端的微调在P和S上比较重要
3.5 方法
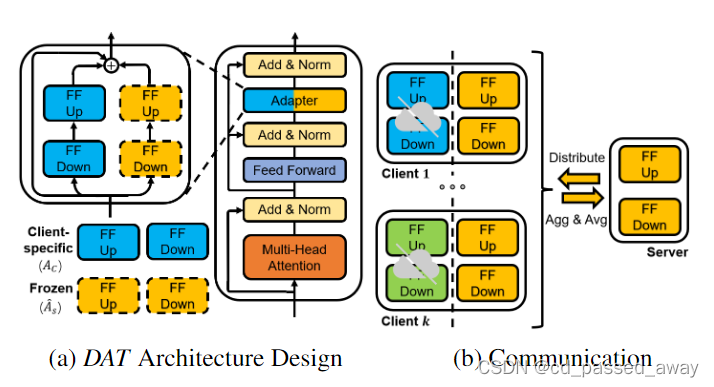
服务器更新
其实就是联邦平均
客户端更新
(1) Dual-Adapter Teacher (DAT):
通过利用 DAT 作为每个客户端 局部优化的指导,我们的目标是将特定于客户端的知识提取到
中,并减轻
对其与客户端无关的知识的遗忘。
DAT由客户端本地Adapter和复制服务器的
组成,
训练过程中冻结。
DAT的特征处理办法:
(2) Mutual Knowledge Distillation (MKD)
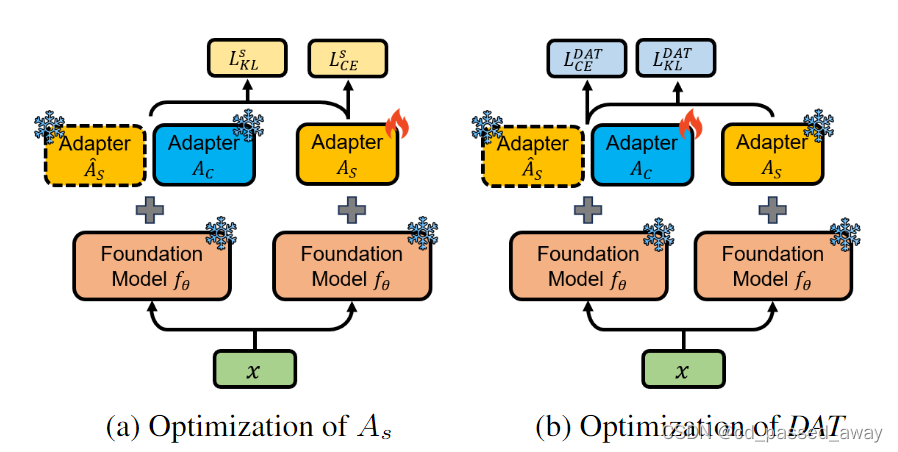
互更新:其实就是用DAT的预测logits来指导服务器adapter的训练,用服务器的预测logits来指导DAT的训练
分类损失:
服务器:
客户端:
总损失:
四、实验
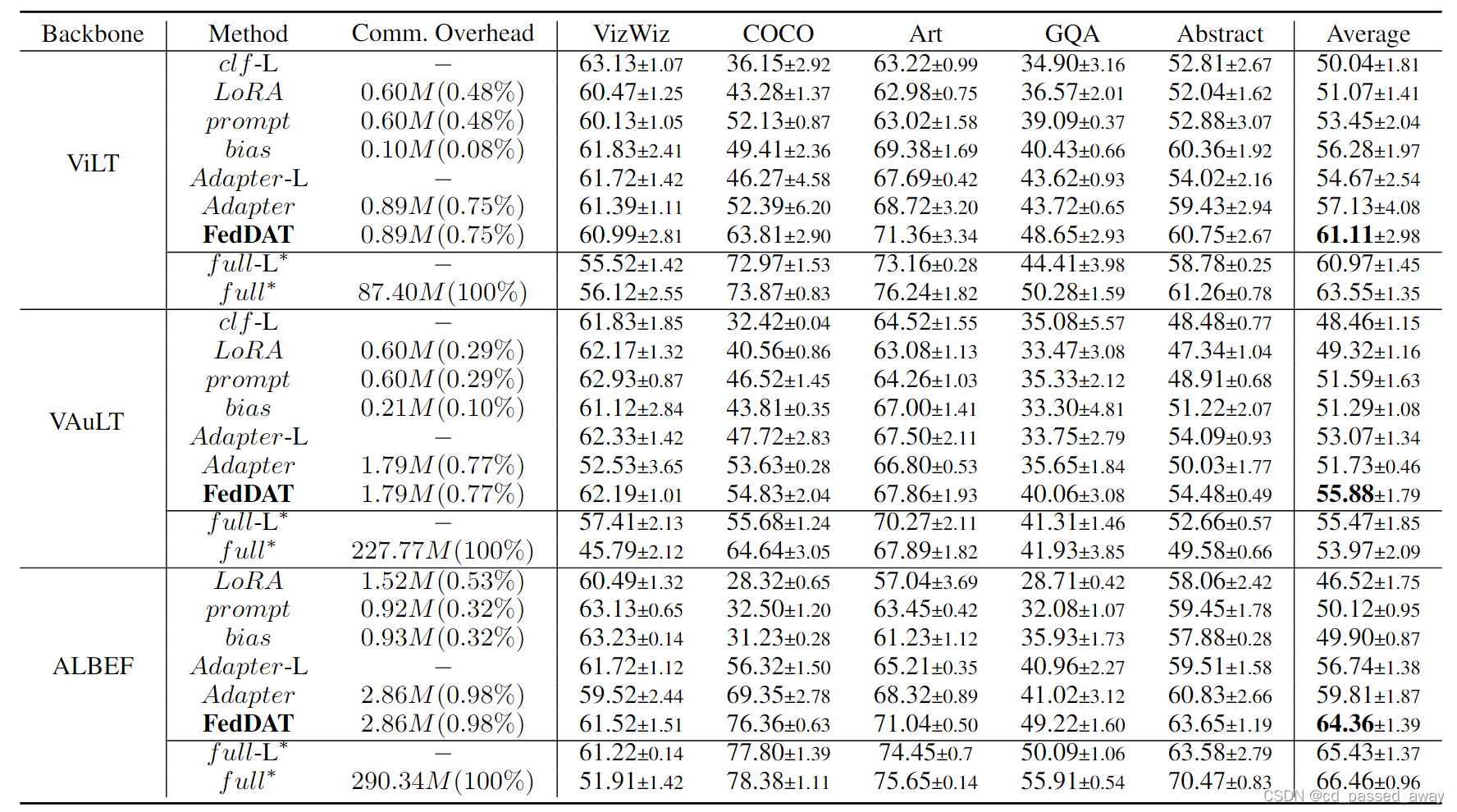
VQA问题上的实验
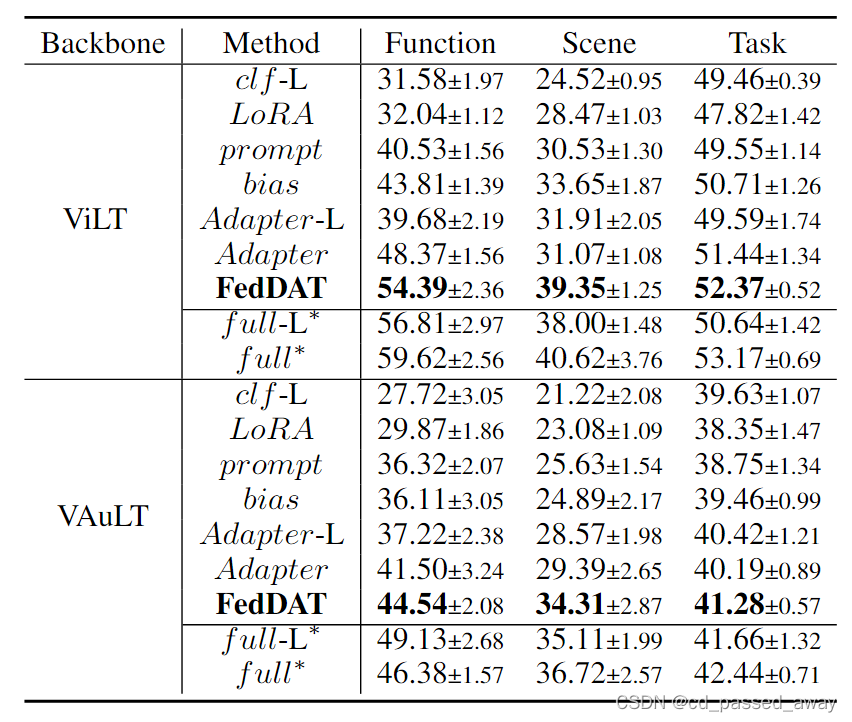
5个不同函数,6个不同视觉环境,和四个不同任务(VQA 、视觉推理自然语言 (NLVR) 、视觉蕴涵 (VE) 和视觉常识推理 (VCR))的实验结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









