







前言
最近在工作中遇到了需要将QQ群成员导出的问题,查找了网上之前的教程,通过官网直接导出群成员,发现这个已经失效了。
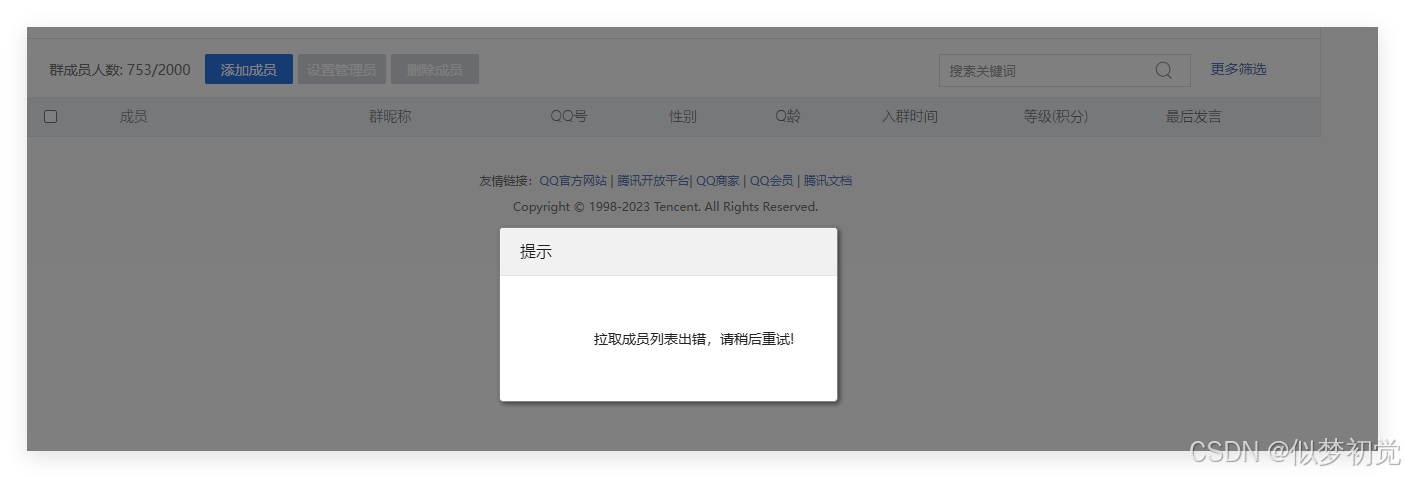
目前只能导出本人是管理员的群,但如果是非管理员,应该如何导出呢?
小编又不停的找网上其他教程,最终终于发现一个非常不错的用于开发QQ机器人的开源项目,可以将QQ各种功能操作生成API接口,其中就有获取QQ群成员,好了,开始我们的操作。
首先,需要在电脑上安装LLOneBot,下载地址:https://github.com/super1207/install_llob/releases
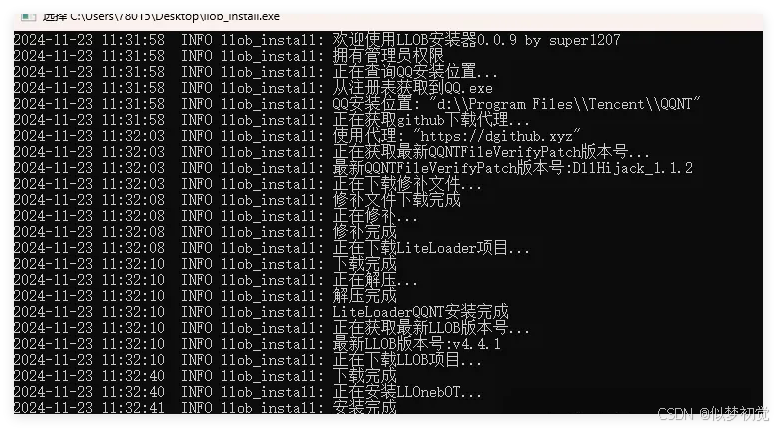
直接下载llob_install.exe,双击打开软件(需要先关闭QQ进程),显示如下图界面,表示安装完成,可以关闭窗口了。
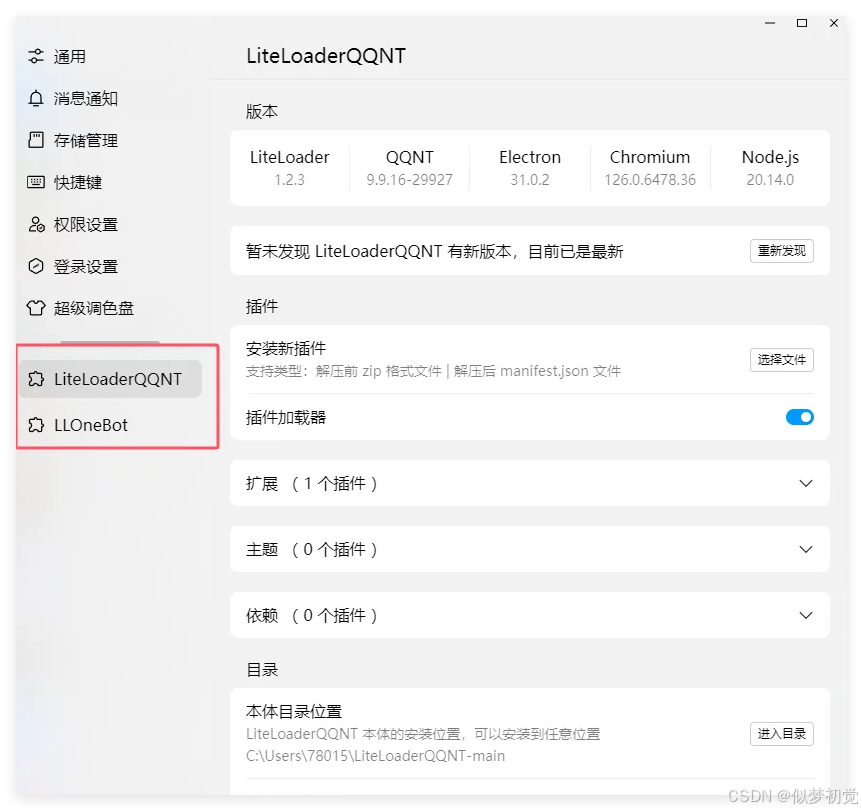
这时,我们打开QQ软件,点击设置,就可以看到多出来两个选项,这表示安装成功了。
最后我们再测试一下,浏览器访问:http://localhost:3000
如果显示“LLOneBot server 已启动”,表示API服务已经启动成功,现在开始调用接口。
小编使用fastapi来调用的这个接口,代码如下:
import io
import re
from fastapi.responses import StreamingResponse
import pandas as pd
import requests
from fastapi import FastAPI, Query
app = FastAPI()
API_URL = "http://localhost:3000"
def get_group_members(params: dict):
path = "/get_group_member_list"
try:
# 发送GET请求
response = requests.get(API_URL + path, params=params)
# 检查请求是否成功(状态码200表示成功)
if response.status_code == 200:
# 解析JSON响应
return response.json()
else:
return "Error: Request failed"
except requests.exceptions.RequestException as e:
# 请求异常处理
return f"Error: {e}"
def clean_string(value):
if isinstance(value, str):
# 移除非法字符
return re.sub(r'[\x00-\x1F\x7F]', '', value)
return value
@app.get("/export_group_members")
def export_group_members_to_excel(group_id: int):
params = {"group_id": group_id}
res = get_group_members(params)
if isinstance(res, dict) and "data" in res:
filtered_data = [
{
"user_id": {member['user_id']",
"nickname": clean_string(member["nickname"]),
"role": member["role"],
"qq_level": member["qq_level"]
}
for member in res["data"]
]
# 创建一个 DataFrame
df = pd.DataFrame(filtered_data)
# 将 DataFrame 保存到一个 BytesIO 对象中
output = io.BytesIO()
df.to_excel(output, index=False, engine='openpyxl')
output.seek(0)
return StreamingResponse(output, media_type="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
headers={"Content-Disposition": f"attachment; filename={group_id}.xlsx"})
else:
return {"code": 500, "message": "Failed to retrieve data"}启动fastapi项目,访问:http://127.0.0.1:8000//export_group_members?group_id=群号 就可以将所有群成员保存到excel文件中了,是不是很简单?
好了,今天的教程分享到此结束,关注我,了解更多前沿教程~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









