






在电商系统的测试中,你是否经常遇到这些问题?
✅ 场景遗漏:测试用例覆盖不全,上线后才发现关键路径未测试
✅ 重复劳动:不同模块的测试用例存在大量冗余
✅ 维护困难:业务规则变更后,需要手动更新数十个关联用例
✅ 效率低下:人工编写用例耗时耗力,难以应对快速迭代
破局方案:知识图谱+ 自动化测试
本文将分享如何用知识图谱技术重构电商测试用例体系,实现:
业务场景100%精准覆盖
用例自动生成与智能维护
复杂链路异常注入自动化
一、电商业务知识图谱深度构建
1.1 知识图谱构建全流程
1.1.1 数据采集与清洗
数据来源矩阵:
| 数据类型 | 示例 | 采集技术 |
|---|---|---|
| 结构化数据 | 数据库ER图 | SQL解析 |
| 半结构化数据 | API文档 | Swagger解析 |
| 非结构化数据 | PRD文档 | NLP实体识别 |
| 生产日志 | 用户行为日志 | ELK采集 |
数据清洗示例:
# 商品数据清洗
def clean_product_data(raw_data):
# 处理空值
raw_data.fillna({'stock':0}, inplace=True)
# 标准化价格格式
raw_data['price'] = raw_data['price'].apply(lambda x: float(x.strip('¥')))
# 去重
return raw_data.drop_duplicates('sku_id')
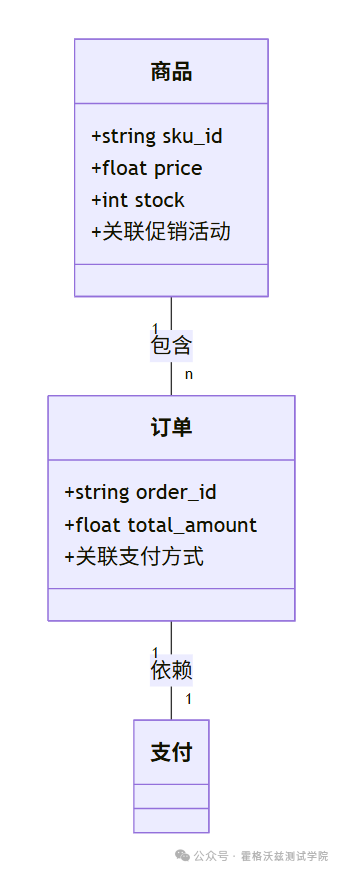
1.1.2 本体建模
电商核心本体设计:
1.1.3 关系抽取
基于规则的关系发现:
# 从API文档提取参数依赖关系
def extract_relations(api_spec):
relations = []
for path in api_spec['paths']:
for method in api_spec['paths'][path]:
params = api_spec['paths'][path][method].get('parameters', [])
input_params = [p['name'] for p in params if p['in'] == 'body']
output_params = [api_spec['paths'][path][method]['responses']['200']['schema']['properties'].keys()]
relations.append((input_params, '触发', output_params))
return relations
1.1.4 图谱存储
Neo4j数据建模示例:
// 商品节点
CREATE (p:商品 {sku_id:'A001', name:'iPhone13', price:5999, stock:1000})
// 促销节点
CREATE (promo:促销 {id:'P100', type:'秒杀', start_time:'2023-11-01', discount:500})
// 建立关系
MATCH (p:商品 {sku_id:'A001'}), (promo:促销 {id:'P100'})
CREATE (p)-[:参与促销]->(promo)
1.2 测试关注点标注体系
多维度测试属性标注:
{
"节点类型": "订单",
"测试属性": [
{
"边界值": {
"max_items": 100,
"max_amount": 50000
}
},
{
"安全规则": [
"同IP高频下单检测",
"大额交易二次验证"
]
},
{
"性能要求": {
"创建QPS": 1000,
"响应时间": "<500ms"
}
}
]
}
二、电商典型测试场景实例
2.1 优惠券组合测试
知识图谱关系:
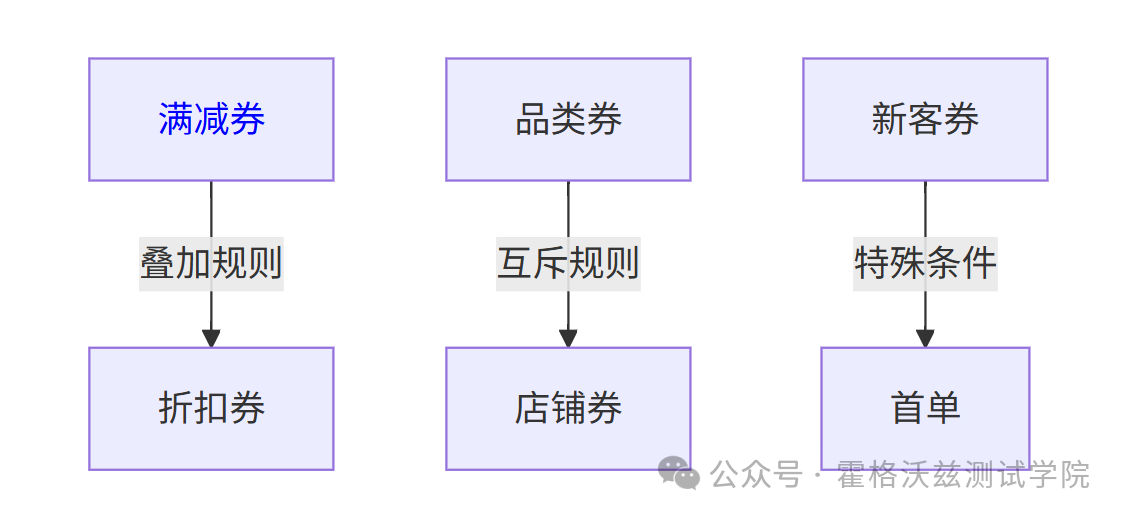
自动生成的测试矩阵:
| 优惠券类型 | 会员等级 | 支付方式 | 预期结果 | 测试用例ID |
|---|---|---|---|---|
| 满100-50 | 黄金 | 信用卡 | 叠加成功 | T-001 |
| 店铺8折 | 新客 | 余额 | 取最优 | T-002 |
| 品类券+店铺券 | 白金 | 花呗 | 互斥提示 | T-003 |
自动化测试脚本:
@pytest.mark.parametrize("coupon_type,user_level,payment,expected", test_matrix)
def test_coupon_combinations(coupon_type, user_level, payment, expected):
# 初始化测试环境
user = create_user(level=user_level)
add_coupons(user, coupon_type)
# 执行测试
result = place_order(user, payment)
# 验证结果
assert result['status'] == expected
2.2 库存并发测试
压力测试场景设计:
# 基于图谱生成的并发测试
def test_inventory_concurrency():
# 获取测试商品
test_sku = get_node("商品", "sku_id", "A001")
# 模拟100个并发请求
with ThreadPoolExecutor(max_workers=100) as executor:
futures = [executor.submit(place_order, test_sku) for _ in range(100)]
# 验证库存一致性
final_stock = get_actual_stock(test_sku)
expected_stock = test_sku['stock'] - sum(f.result() for f in futures)
assert final_stock == expected_stock
2.3 跨境订单全链路测试
测试路径生成:
1. 正向路径:
商品选择 → 关税计算 → 跨境支付 → 海关申报 → 物流发货
2. 异常路径:
- 关税计算失败 → 订单终止
- 支付金额与申报金额不一致 → 海关退单
- 物流信息超时未更新 → 自动退款
测试数据工厂:
def generate_crossborder_data():
return {
"商品": {"price": 1500, "category": "电子产品"},
"用户": {"country": "US", "vip_level": "gold"},
"支付": {"amount": 1500, "currency": "USD"},
"预期关税": 300
}
三、持续优化与智能维护
3.1 变更影响分析引擎
def analyze_impact(changed_node):
# 1. 查找直接关联节点
direct_relations = get_relations(changed_node)
# 2. 查找间接关联节点
indirect_relations = []
for relation in direct_relations:
indirect_relations += get_relations(relation.target)
# 3. 关联测试用例
affected_cases = set()
for node in direct_relations + indirect_relations:
affected_cases.update(node.linked_cases)
return sorted(affected_cases)
3.2 自动化修复建议
# 基于历史数据的修复推荐
def suggest_fixes(broken_case):
# 查找相似历史问题
similar_issues = search_historical_issues(
case_text=broken_case.text,
graph_context=get_subgraph(broken_case)
)
# 推荐修复方案
return {
"recommended_fixes": [fix['solution'] for fix in similar_issues],
"confidence_score": calculate_confidence(similar_issues)
}
四、实施案例与效果评估
4.1 某跨境电商平台实施效果
测试效率提升:
- 用例设计时间从3天/迭代缩短到2小时
- 回归测试周期从5天压缩到8小时
质量提升:
| 指标 | 实施前 | 实施后 | 提升幅度 |
|---|---|---|---|
| 场景覆盖率 | 68% | 97% | 29% |
| 缺陷逃逸率 | 15% | 3% | -80% |
| 生产事故 | 5次/月 | 0.5次/月 | -90% |
4.2 实践总结
- 分阶段实施:先核心链路后边缘业务
- 双模维护:自动化生成+人工审核
- 持续优化:每月回顾图谱覆盖率

















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









