







最近在学习Hadoop,遇到不少问题还好都一一解决了,希望记录下来以后可以查看。
1.首先最基本的就是搭Hadoop环境,因为资源问题暂时只尝试单机模式和伪分布式模式。
首先在我的Win7上安装Orace VBox,然后在上面安装一个Ubuntu 14.04 Kylin, 然后再安装Hadoop 2.6.0
单机模式
1.添加hadoop用户到系统用户
安装前要做一件事——添加一个名为hadoop到系统用户,专门用来做Hadoop测试。
- ~$ sudo addgroup hadoop
- ~$ sudo adduser --ingroup hadoop hadoop
现在只是添加了一个用户hadoop,它并不具备管理员权限,因此我们需要将用户hadoop添加到管理员组:
- ~$ sudo usermod -aG admin hadoop
由于Hadoop用ssh通信,先安装ssh
- ~$ sudo apt-get install openssh-server
ssh安装完成以后,先启动服务:
- ~$ sudo /etc/init.d/ssh start
- ~$ ps -e | grep ssh
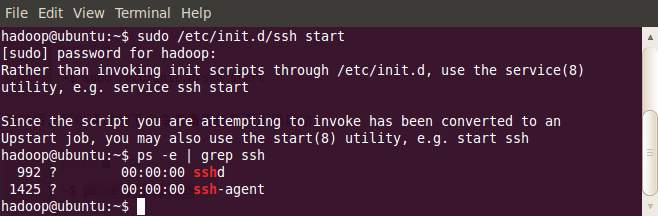
作为一个安全通信协议,使用时需要密码,因此我们要设置成免密码登录,生成私钥和公钥:
- hadoop@scgm-ProBook:~$ ssh-keygen -t rsa -P ""
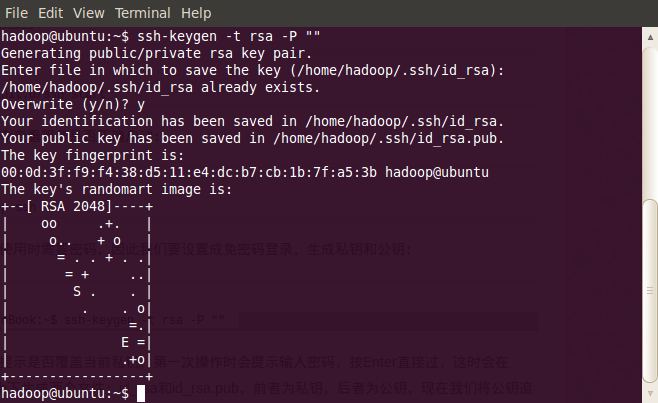
因为已有私钥,所以会提示是否覆盖当前私钥。第一次操作时会提示输入密码,按Enter直接过,这时会在~/home/{username}/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥,现在我们将公钥追加到authorized_keys中(authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容):
- ~$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- ~$ ssh localhost
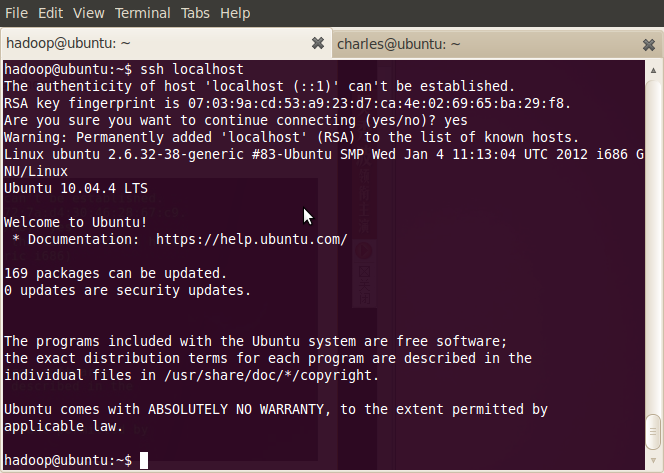
登出:
- ~$ exit
- ~$ ssh localhost
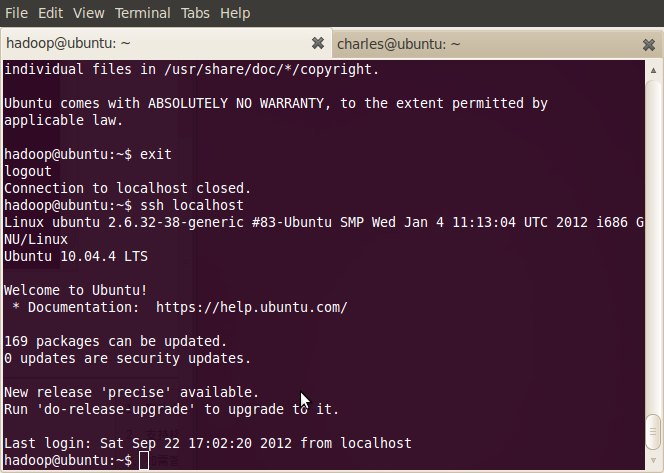

登出:
- ~$ exit
3.安装Java
- ~$ sudo apt-get install openjdk-6-jdk
- ~$ java -version
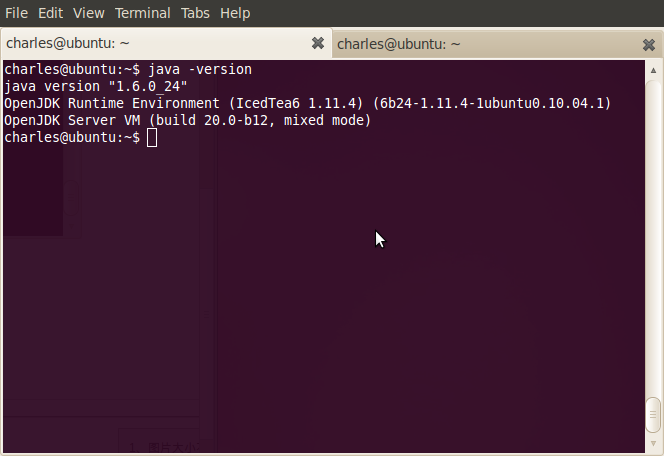
4.安装hadoop
到官网下载hadoop源文件
解压并放到你希望的目录中。我是放到/usr/local/hadoop
5.设定hadoop-env.sh(Java 安装路径)
进入hadoop目录,打开conf目录下到hadoop-env.sh,添加以下信息:
export JAVA_HOME=/usr/lib/jvm/java-6-openjdk (视你机器的java安装路径而定)
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:/usr/local/hadoop/bin
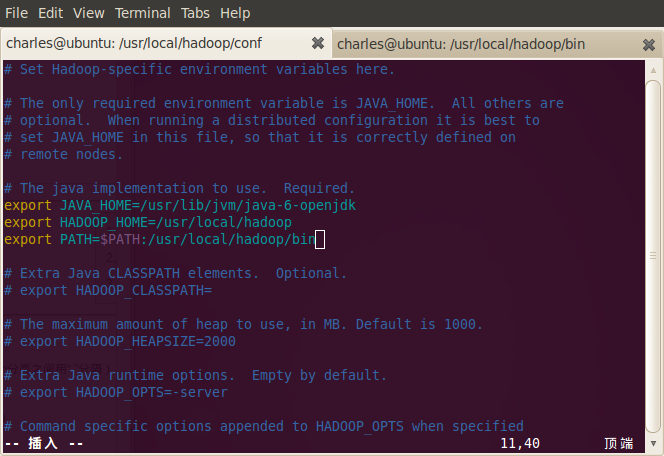
并且,让环境变量配置生效source
- ~$ source /usr/local/hadoop/conf/hadoop-env.sh
至此,hadoop的单机模式已经安装成功。
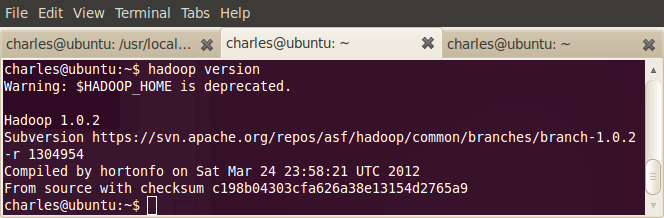
于是,运行一下hadoop自带的例子WordCount来感受以下MapReduce过程:
在hadoop目录下新建input文件夹
- ~$ mkdir input
- ~$ cp conf/* input<span style="font-family: Arial, Helvetica, sans-serif; white-space: normal; background-color: rgb(255, 255, 255); "> </span>
- ~$ bin/hadoop jar hadoop-0.20.2-examples.jar wordcount input output
运行
- ~$ cat output/*
伪分布式模式
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
The following instructions are to run a MapReduce job locally. If you want to execute a job on YARN, see YARN on Single Node.
- Format the filesystem:
$ bin/hdfs namenode -format
- Start NameNode daemon and DataNode daemon:
$ sbin/start-dfs.sh
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs).
- Browse the web interface for the NameNode; by default it is available at:
- NameNode - http://localhost:50070/
- Make the HDFS directories required to execute MapReduce jobs:
$ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/<username>
- Copy the input files into the distributed filesystem:
$ bin/hdfs dfs -put etc/hadoop input
- Run some of the examples provided:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+'
- Examine the output files:
Copy the output files from the distributed filesystem to the local filesystem and examine them:
$ bin/hdfs dfs -get output output $ cat output/*
or
View the output files on the distributed filesystem:
$ bin/hdfs dfs -cat output/*
- When you're done, stop the daemons with:
$ sbin/stop-dfs.sh

















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









