







数据库
MySQL及SQLYog
MySQL5.7安装
根据标记序号依次点击进行安装操作
-
Step1:
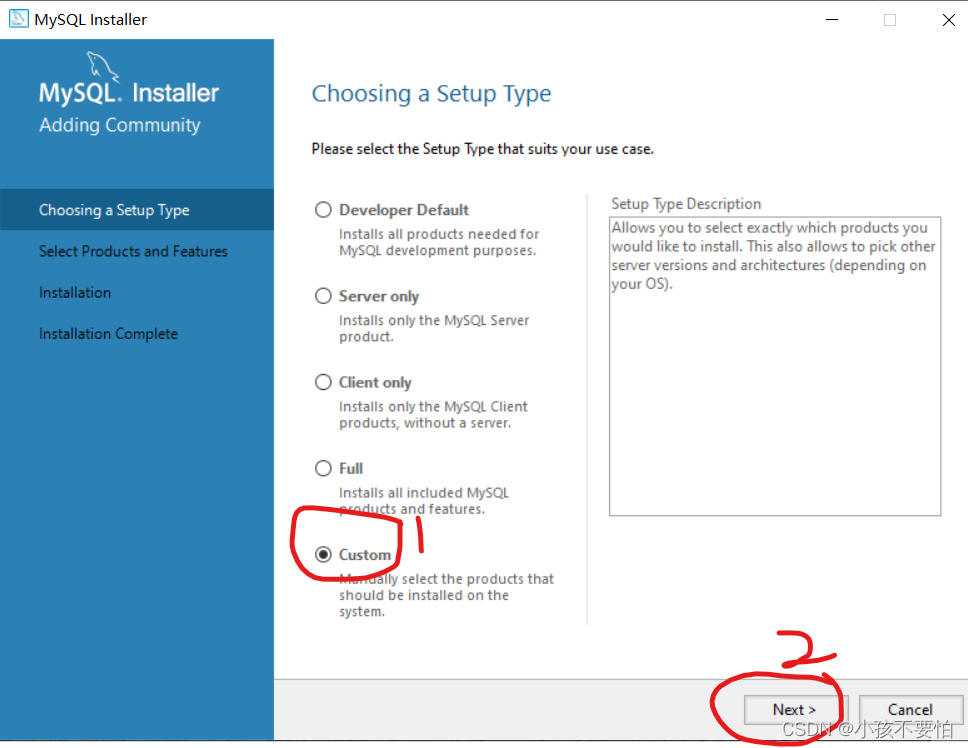
-
Step2:
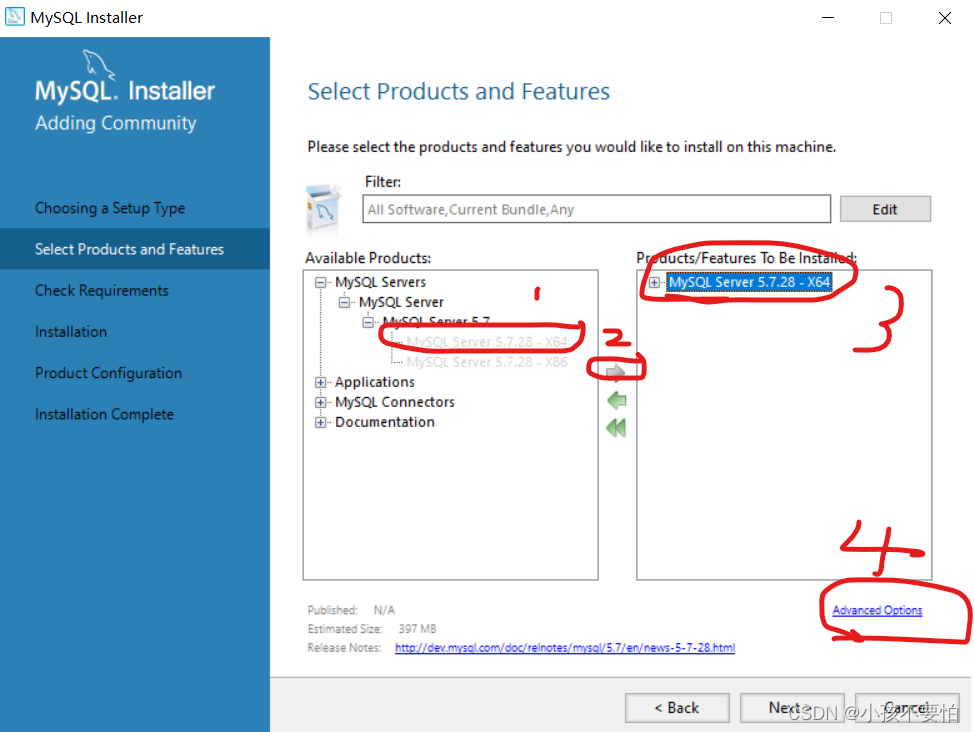
-
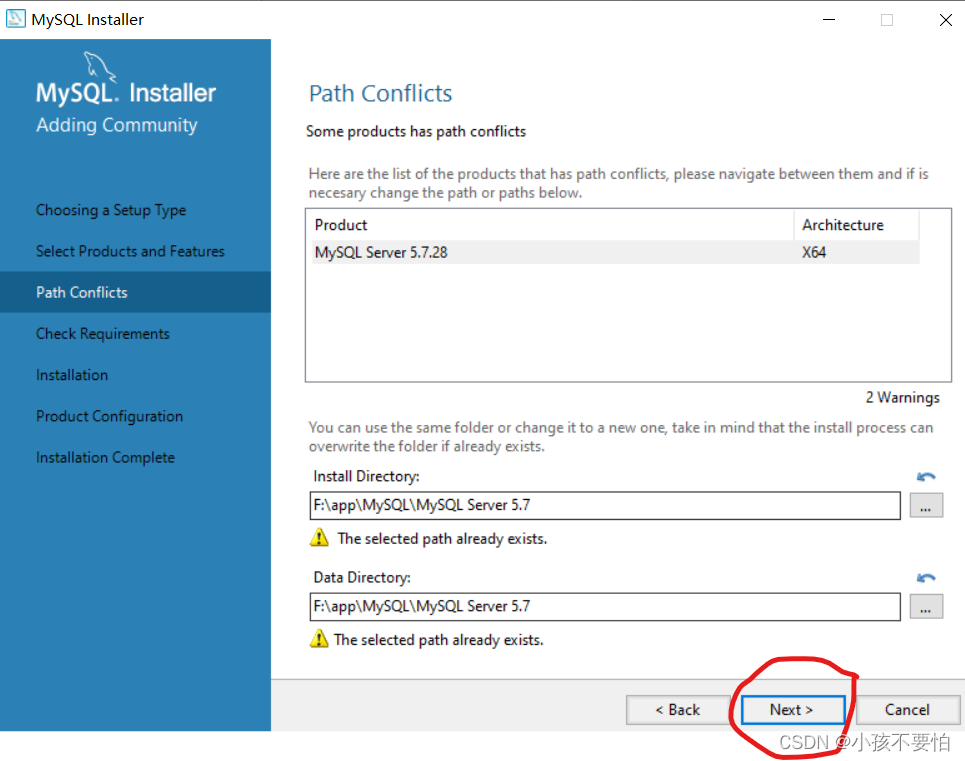
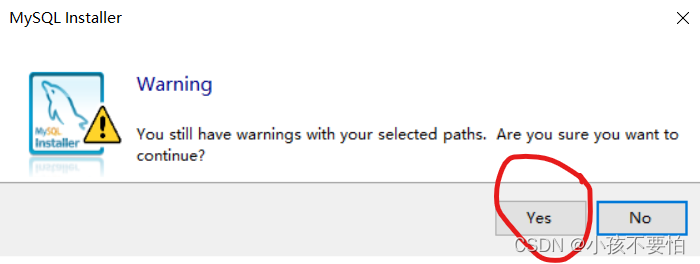
Step3:更改MySQL安装路径和数据库安装路径,然后点击OK;随后会跳出一个如图二的警告,仍点击OK即可。
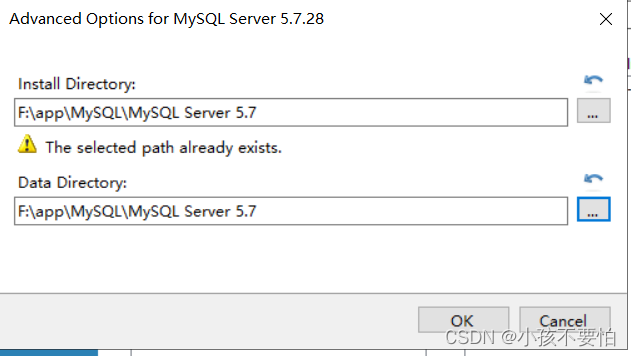
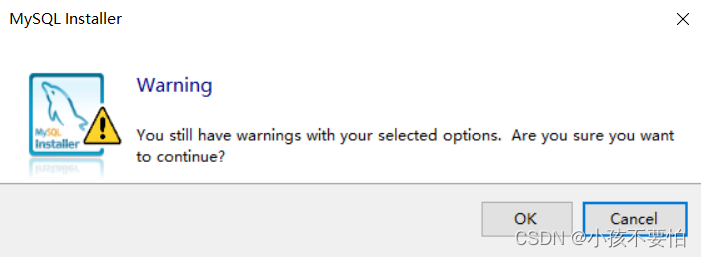
-
Step4:
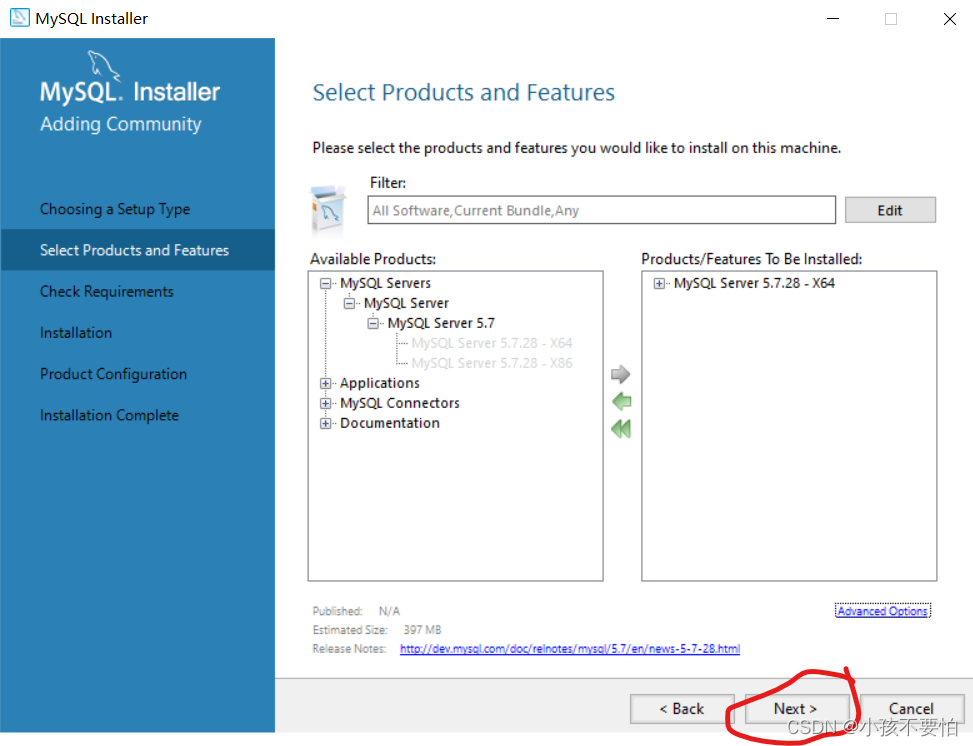
-
Step5:
-
Step6:点击Execute后会弹出一个让你安装需要支撑的环境窗口即Visul C++2013,直接点击install即可。
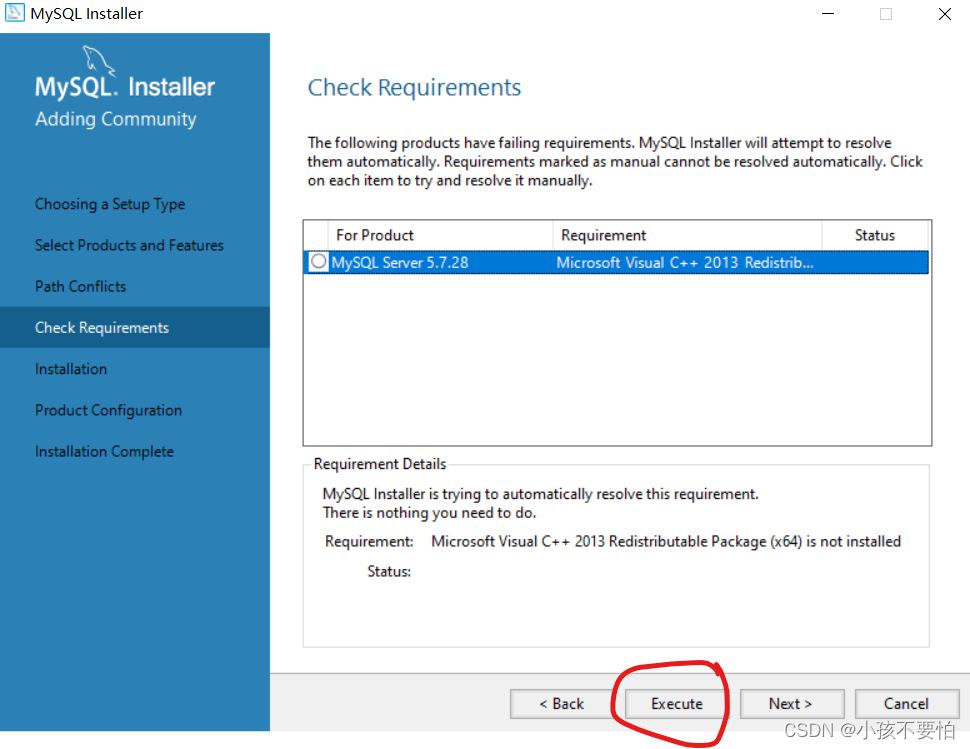
-
Step7:
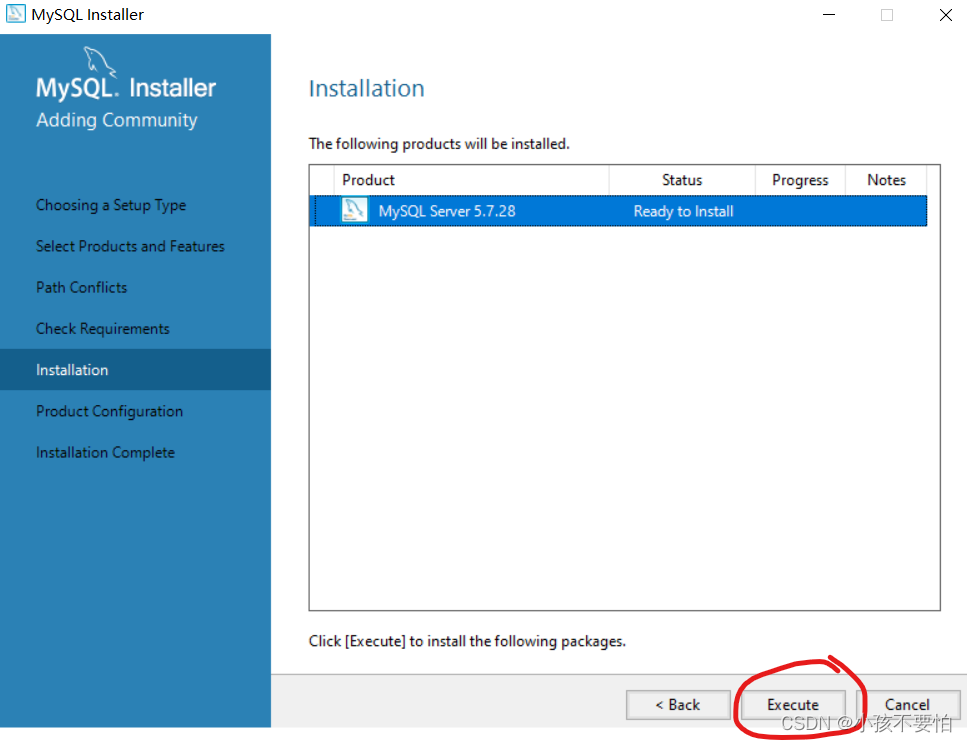
-
Step8:安装完成后一直点击next,直到如下图所示为止。将圈住的地方改为MINIMAL,然后点击next
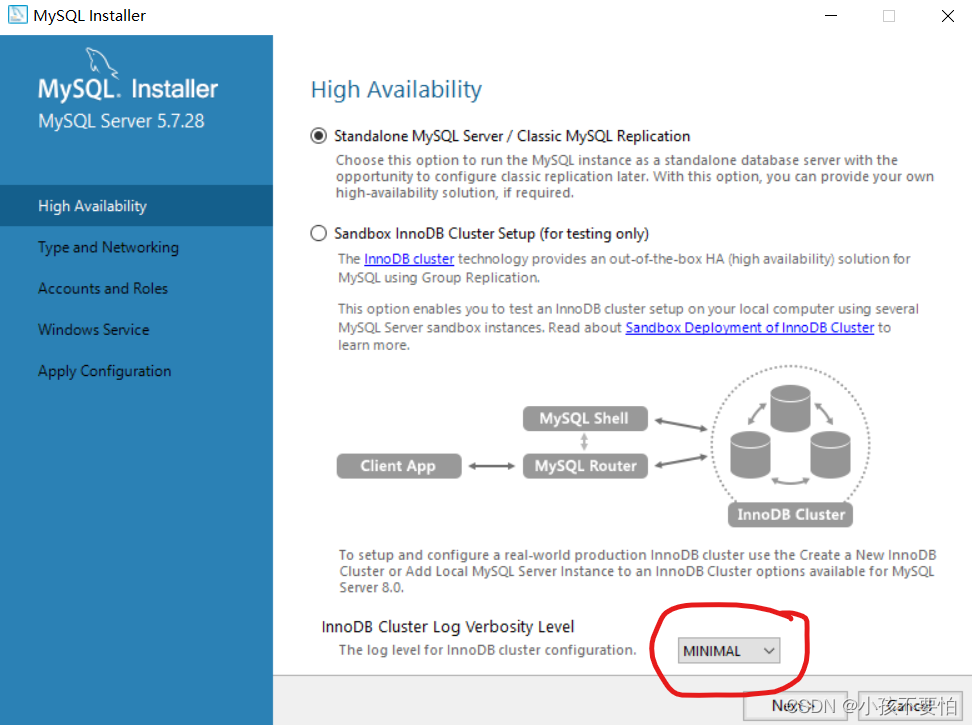
-
Step9:
-
Step10:设置密码,然后一直next
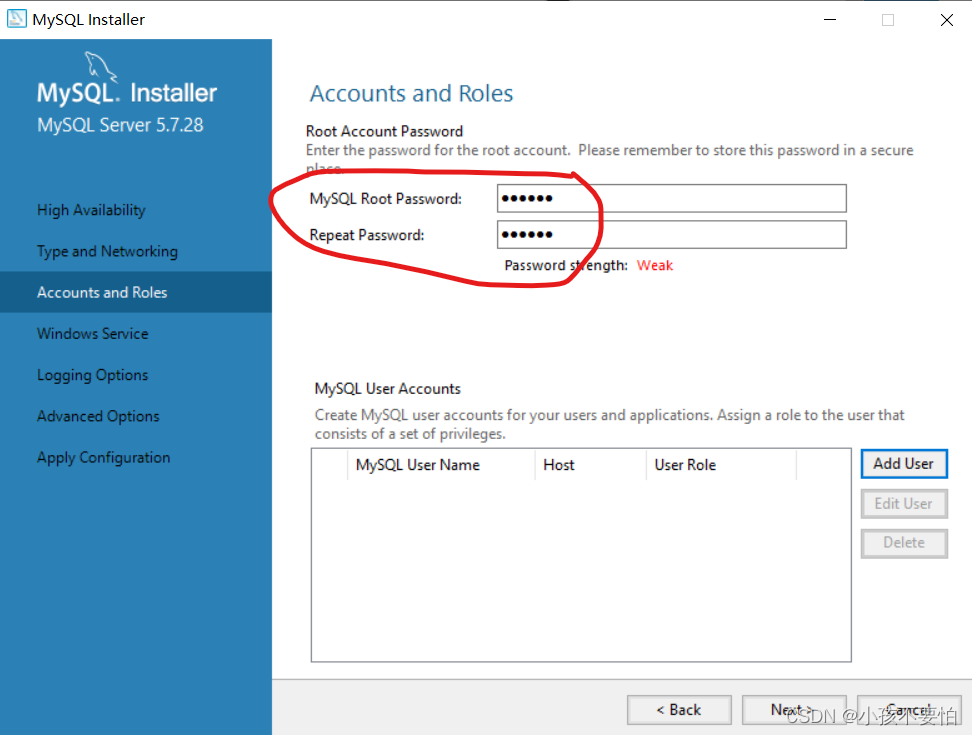
-
Step11:点击Execute等待安装成功后点击Finish—>next—>Finsh

-
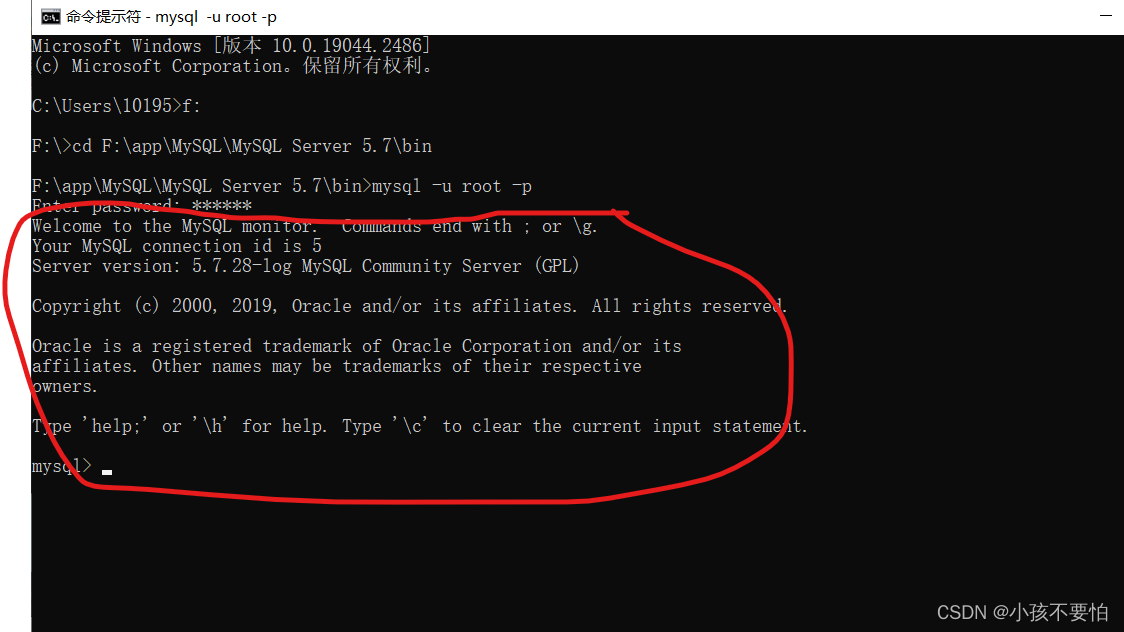
Step12:测试是否安装成功cmd打开命令提示符—>cd 进到MySQL的bin目录下,即F:\app\MySQL\MySQL Server 5.7\bin,然后输入
mysql -u root -p回车并输入密码。若出现图示圈住内容代表成功进入MySQL即可使用MySQL。为了能够不切盘更简便的使用MySQL,则需配置环境变量
-
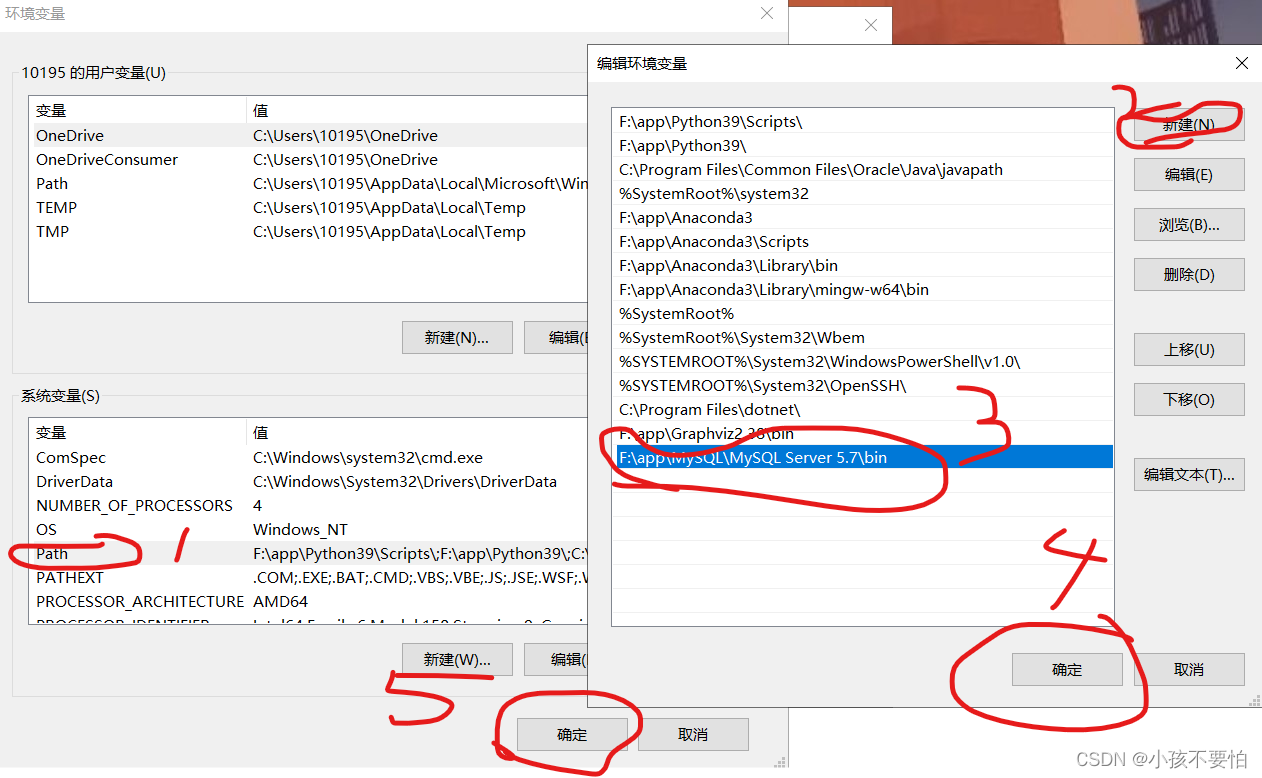
Step13:配置环境变量,注意是MySQL的bin目录路径加入到Path中。
-
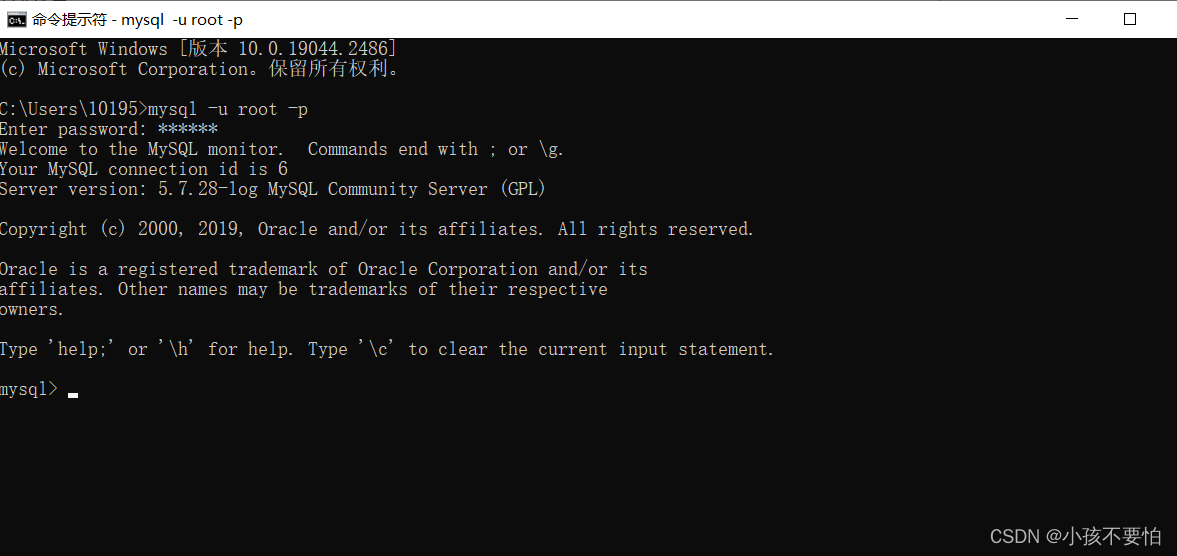
Step14:cmd测试是否成功,此时不需要切盘就可进入mysql
MySQL卸载
-
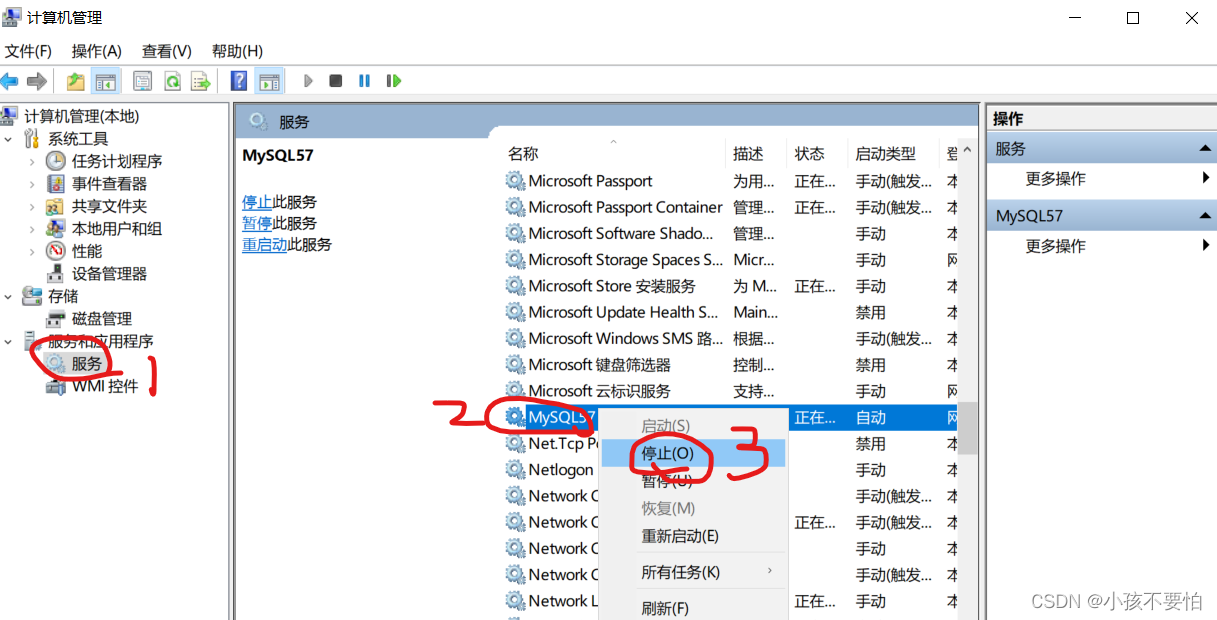
Step1:结束MySQL后台进程:右键点击电脑—>管理—>服务和应用程序—>然后找到MySQL服务名右键—>停止
-
Step2:卸载MySQL:控制面板—>卸载程序,按顺序将圈住的两个都卸载。
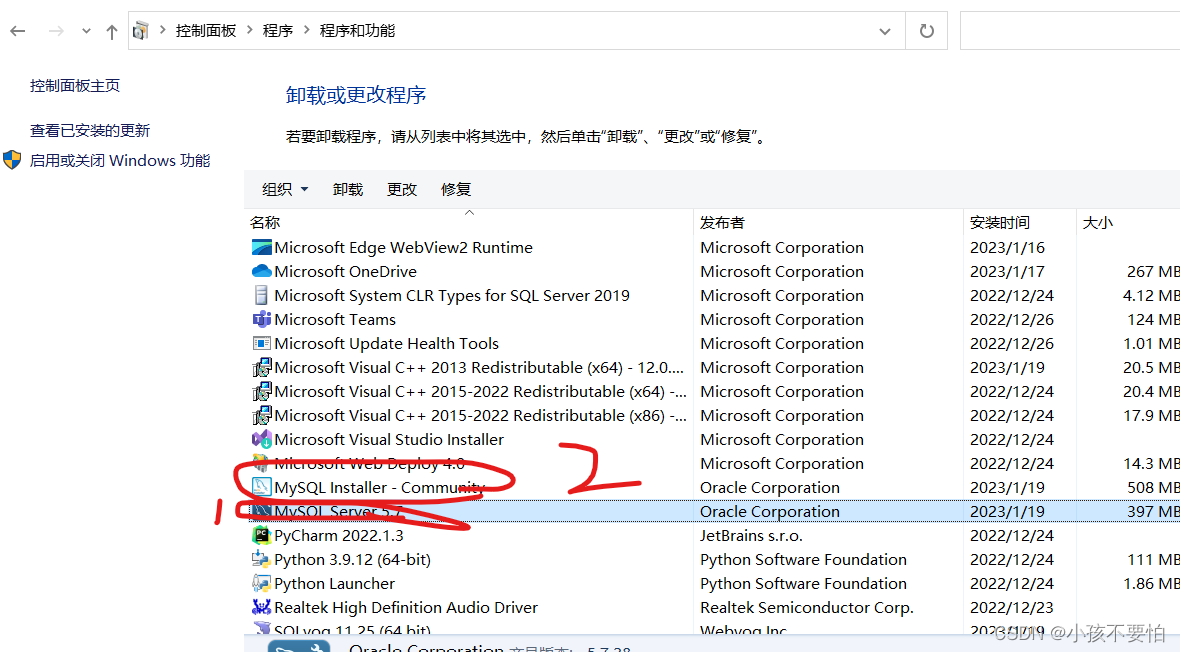
-
Step3:去对应盘中删除MySQL文件夹中的所有文件
- 注意:目录里有数据库和配置文件,确定不需要在删;若不删除,则在再次安装时选其他目录安装
-
Step4:删除服务名:以管理员身份运行cmd—>输入
sc delete MySQL57回车。MySQL57为MySQL对应版本的服务名,不知道可根据Step1的步骤进行查看。 -
Step5:清理注册表(详见百度)
-
经过以上系统即可彻底卸载,若仍有问题,则重装系统,别无他法。
SQLYog安装
Step1:一路next知道如图所示停下,更改安装路径,然后点击安装–>下一步。完成后不要打开SQLYog,继续Step2操作。
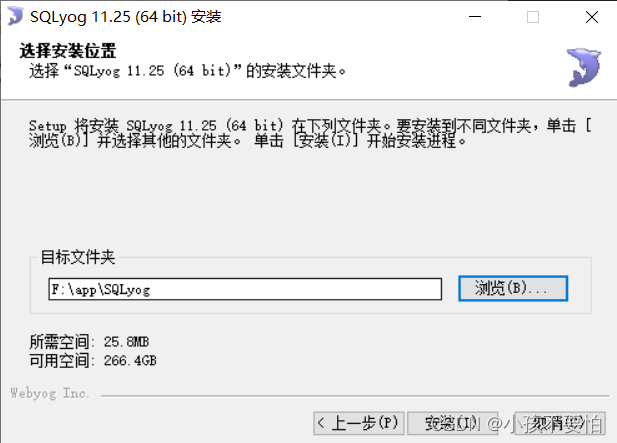
-
Step2:双击SQLyog-11.2.5-0.x64.reg点击是–>确定即可
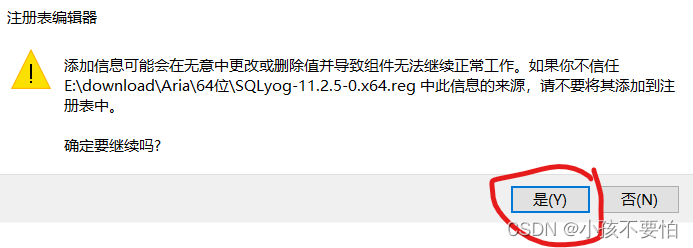
-
Step3:打开SQLyog—>新建—>输入名称(英文)—>确定,然后会出现下图。然后输入密码点击连接即可。
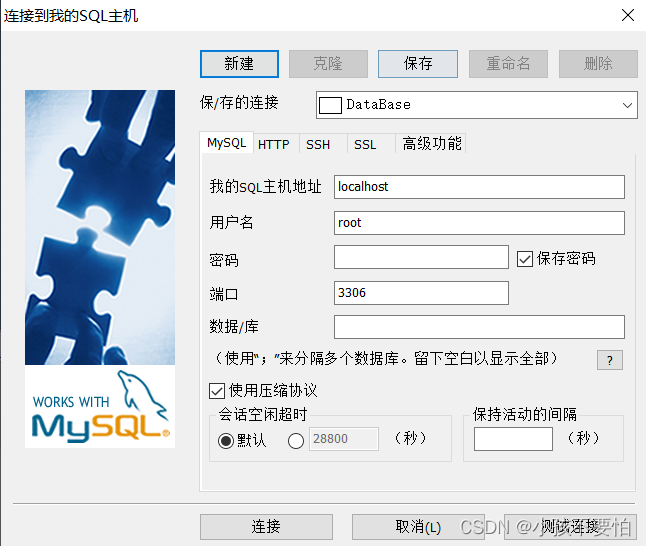
注意:**"我的SQL主机地址"为Mysql服务器主机地址,localhost代表本机MySQL服务器,若你想连接其他公司的数据库,你需要将"我的SQL主机地址"改为公司的MySQL服务器主机地址;"用户名"为登录MySQL的用户名;“密码"和"端口”**分别为MySQL的密码和端口号。
数据库的概念
数据库(DB,database):存储数据的“仓库”,它保存了一系列有组织的数据。
数据库管理系统(DBMS,Database Management System):数据库是通过DBMS创建和操作的容器。如:MySQL、Oracle、sqlServer等就是DBMS。DBMS相当于一个管家,来管理DB。
结构化查询语言(SQL,Structure Query Language):专门用来与数据库通信的语言
DB
- 作用
存储数据
实现数据持久化
使用完整的管理系统统一管理,易于查询
SQL
SQL优点
-
SQL不是某个特定数据库供应商专有的语言,几乎所有的DBMS都支持SQL
-
简单易学
-
可以进行非常复杂和和高级的数据库操作
SQL语句类型
- DML(Data Manipulation Language):数据操纵语言
- DDL(Data Definition Language):数据定义语言
- DCL(Data Control Language):数据控制语言
DML
- 作用:用于查询与修改数据记录,包括如下SQL语句:
- INSERT:添加数据到数据库中
- UPDATE:修改数据库中的数据
- DELETE:删除数据库中的数据
- SELECT(为SQL语言的基础,特重要):选择查询数据
==注意:==DQL就是指DML中的SELECT
DDL
- 作用:用于定义数据库的结构,比如创建、修改或删除数据库对象,包括如下SQL语句:
- CREATE TABLE:创建数据库表
- ALTER TABLE:更改表结构、添加、删除、修改列长度
- DROP TABLE:删除表
- CREATE INDEX:在表上建立索引
- DROP INDEX:删除索引
DCL
- 作用用来控制数据库的访问,包括如下SQL语句:
- GRANT:授予访问权限
- REVOKE:撤销访问权限
- COMMIT:提交事务处理
- ROLLBACK:事务处理回退
- SAVEPOINT:设置保存点
- LOCK:对数据库的特定部分进行锁定
SQL语言
- 注意事项
- SQL语言大小写不敏感
- SQL语言可以写在一行或多行
- 关键字不能被缩写或分行
- 各子句之间一般要分行写
- 使用缩进提高语句的可读性
导入数据
-
Step1:
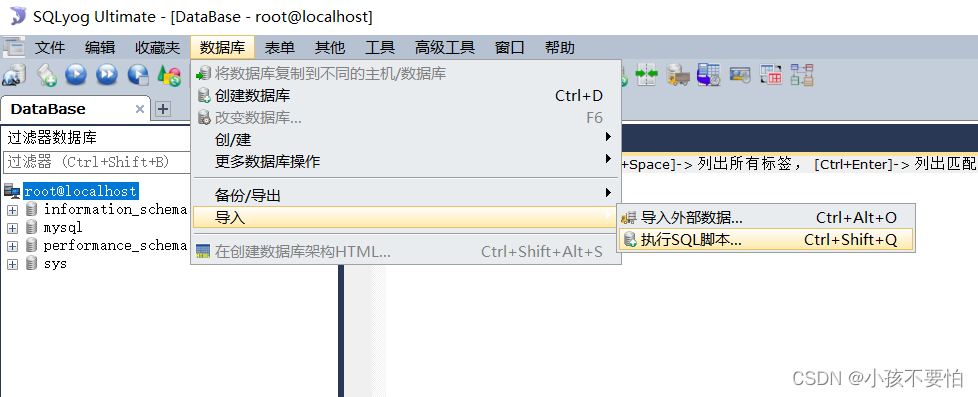
-
Step2:选择你所导入的sql文件的位置,然后点击执行
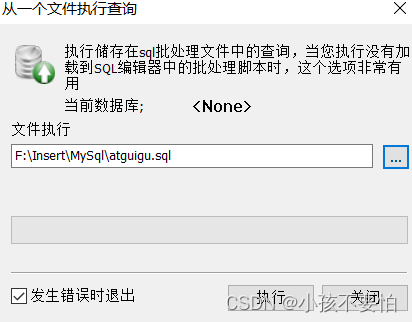
-
Step3:当出现导入成功后点击完成即可。
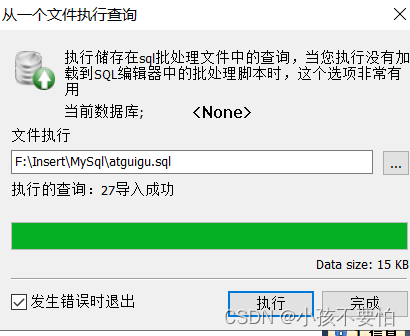
-
Step4:然后右键点击MySQL服务器—>刷新,则会出现你导入的sql文件,即myemployees
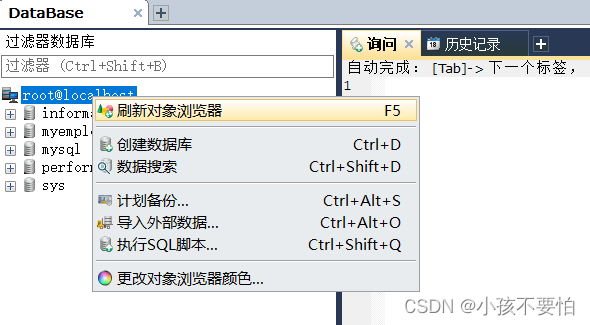
运算符
| 操作符 | 含义 |
|---|---|
| = | 等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| <> | 不等于(也可以是!=,但不推荐) |
| AND | 且(也可以是&&,但不推荐) |
| OR | 或(也可以是||,但不推荐) |
| BETWEEN a AND b | a到b之间(a,b顺序不能变),详见2.1 |
| IN(a,b) | 详见例2.2 |
| \ | 转义字符,详见三-4-3 |
| ESCAPE | 指定转义字符,详见三-4-3 |
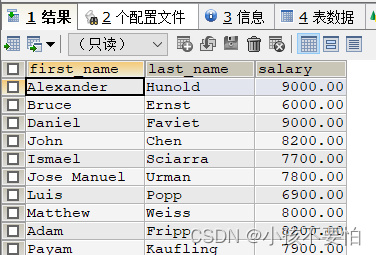
例2-1:查询薪水在6000到10000之间的员工
#方式一
SELECT first_name,last_name,salary
FROM employees
WHERE salary >= 6000 AND salary <=10000;
#方式二
SELECT first_name,last_name,salary
FROM employees
WHERE salary BETWEEN 6000 AND 10000;
#注意:方式二中BETWEEN 6000 AND 10000相当于大于等于6000并且小于等于10000
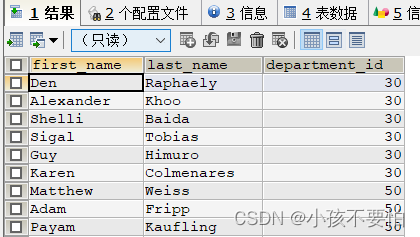
例2-2:查询30或50号部门中的所有员工
#方式一
SELECT first_name,last_name,department_id
FROM employees
WHERE department_id = 30 OR department_id = 50;
#方式二
SELECT first_name,last_name,department_id
FROM employees
WHERE department_id IN(30,50);
基本查询
-
注释
/*多行注释*/-- 单行注释#单行注释
-
查看所有库
-
SHOW DATABASES; -
选库
USE + 库名;,如:USE myemployees;
-
查看选中的库中的所有的表
-
SHOW TABLES; -
查看表中内容
(1)查看表中部分字段
SELECT 字段名1,字段名2,...... FROM 表名;,字段名就是表中的列索引名
SELECT last_name,salary FROM employees; #等同于(可分行写) SELECT last_name,salary FROM employees;(2)查询表中所有字段
SELECT * FROM 表名;*表示所有的字段。
-
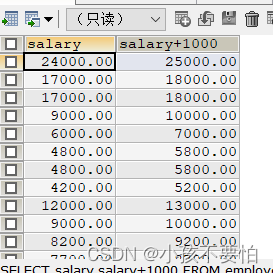
查询所有员工薪水加1000后的薪水(不会改变原表中的数据)
-
SELECT salary,salary+1000 FROM employees; #等同于 SELECT salary,salary+1000 FROM employees;
-
-
任何类型的数据和Null做运算,结果均为Null,如下:
SELECT salary,salary+NULL FROM employees; #等同于 SELECT salary,salary+NULL FROM employees;

-
输出语句
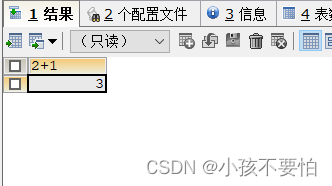
- DUAL:伪表(即虚拟表),可以省略不写
SELECT 2+1;
#等同于
SELECT 2+1
FROM DUAL
更改字段名
SELECT 字段名1 别名,字段名2 AS 别名,...
FROM 表名;
注意:有无AS都可。且执行时先执行FROM后的代码
SELECT employee_id,employee_id+10 new_id,salary,salary+1000 new_salary1
FROM employees;
#等同于
SELECT employee_id,employee_id+10 AS new_id,salary,salary+1000 AS new_salary1
FROM employees;
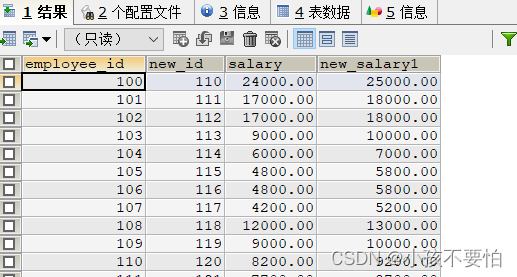
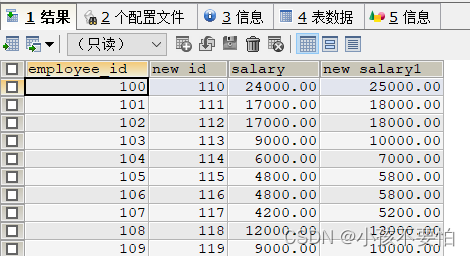
- 更改别名时,若别名中有空格,则需要用单引号或双引号将其包裹,如下:
SELECT employee_id,employee_id+10 "new id",salary,salary+1000 "new salary1"
FROM employees;
过滤
SELECT 字段名1,字段名2,......
FROM 表名
WHERE 过滤条件;
例3-1:查询薪资大于6000的员工
SELECT first_name,last_name,salary
FROM employees
WHERE salary > 6000;
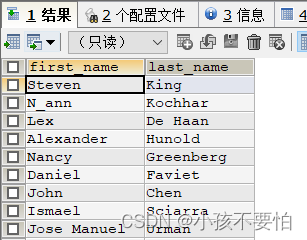
例3-2:查询部门为30和50的员工有哪些
#方式一
SELECT first_name,last_name,department_id
FROM employees
WHERE department_id = 30 OR department_id = 50;
#方式二
SELECT first_name,last_name,department_id
FROM employees
WHERE department_id IN(30,50);
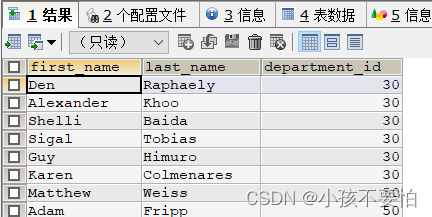
例3-3:查询除80号部门的所有员工
#SQL中<>为不等于(推荐),也可以写!=
SELECT first_name,last_name,department_id
FROM employees
WHERE department_id <> 80;
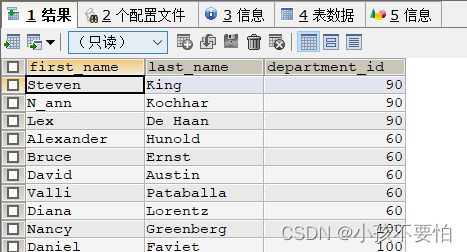
例3-4:查询薪水在6000到10000之间的员工
SELECT first_name,last_name,salary
FROM employees
WHERE salary >= 6000 AND salary <=10000;
#也可以用
SELECT first_name,last_name,salary
FROM employees
WHERE salary BETWEEN 6000 AND 10000;
#若改为不在6000到10000则加个NOT即可,详见例6
例3-5:查询奖金率为null的员工,查询奖金率不为null的员工
注意:
(1)判断值是NULL,用IS判断,不能用=判断
(2)判断值不是NULL,用IS NOT判断,不能用<>判断
#查询奖金率为null的员工
SELECT first_name,last_name
FROM employees
WHERE commission_pct IS NULL;
#查询奖金率不为null的员工
SELECT first_name,last_name
FROM employees
WHERE commission_pct IS NOT NULL;
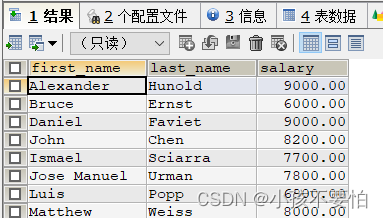
例3-6:查询员工的薪水不在6000到10000之间的员工
SELECT first_name, salary
FROM employees
WHERE NOT salary >= 6000 AND salary <= 10000;
#等同于
SELECT first_name,last_name,salary
FROM employees
WHERE salary NOT BETWEEN 6000 AND 10000;
模糊查询
- LIKE------模糊查询
- 用到的一些符号
- %------表示任意个数的任意字符,详见例4-1
- _------表示任意一个字符,详见例4-2
- \ ------转义字符,表示将具有特殊含义的符号转化为普通符号,不具特殊含义,详见4-3
例4-1:查询姓名中包含f的员工
SELECT first_name
FROM employees
WHERE first_name LIKE '%f%';
#f左边的%代表f前可有任意个数的任意字符
#f右边的%代表f后可有任意个数的任意字符
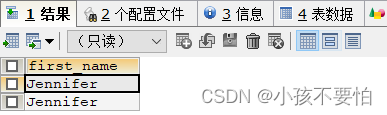
例4-2:查询姓名中的第二个字符为d的员工
SELECT first_name
FROM employees
#_代表任意一个字符
WHERE first_name LIKE '_d%';
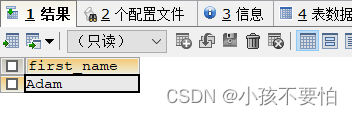
例4-3:查询姓名中第二个字符为_的员工
#方式一:使用转义字符\
SELECT first_name
FROM employees
#\_表示内容为_
WHERE first_name LIKE '_\_%';
#方式二:利用ESCAPE指定转义字符
SELECT first_name
FROM employees
#将$作为转义字符,此时$_表示内容为_
WHERE first_name LIKE '_$_%' ESCAPE '$';
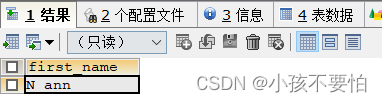
例4-4:查询姓名中既包含a又包含e的员工
#方式一
SELECT first_name
FROM employees
WHERE first_name LIKE '%a%e%' OR '%e%a%';
#方式二
SELECT first_name
FROM employees
WHERE first_name LIKE '%a%' AND first_name LIKE '%e%';
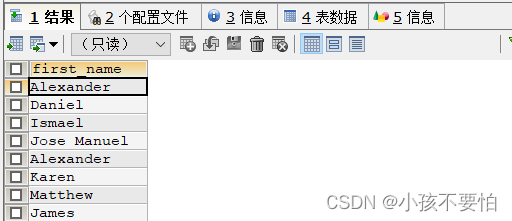
排序
- 升序—ASC------缺省默认为升序
- 降序—DESC
SELECT first_name,last_name,salary
FROM employees
ORDER BY salary DESC;
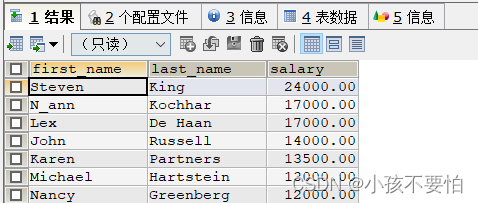
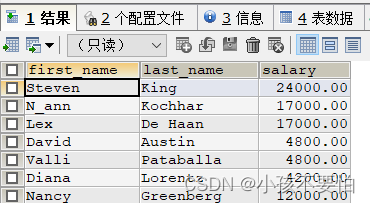
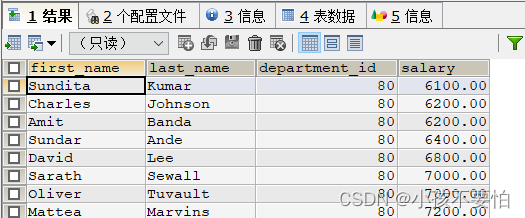
例5-2:查询80号部门员工的姓名和薪水,且薪水按照升序排序
SELECT first_name,last_name,department_id,salary
FROM employees
WHERE department_id = 80
ORDER BY salary;
例5-3:将所有员工的薪水+1000,并对加薪后的薪水进行降序排序
SELECT first_name,last_name,salary,salary+1000 AS "new salary"
FROM employees
#注意:排序时用双引号如果报错的话就用飘号即esc下面的那个键,推荐飘号
ORDER BY `new salary` DESC;

例5-4:查询所有员工的姓名、薪水、部门号,并对部门号进行降序排序,若部门号相同再按照薪水进行升序排序
SELECT first_name,last_name,department_id,salary
FROM employees
ORDER BY department_id DESC,salary ASC;
多表查询
- sql99:
SELECT 字段名1,字段名2,......
FROM 表名1 JOIN 表名2
ON 连接条件
JOIN 表名3
ON 连接条件
...
WHERE 过滤条件
ORDER BY 字段名1 ASC/DESC, 字段名2 ASC/DESC,...
格式解释:
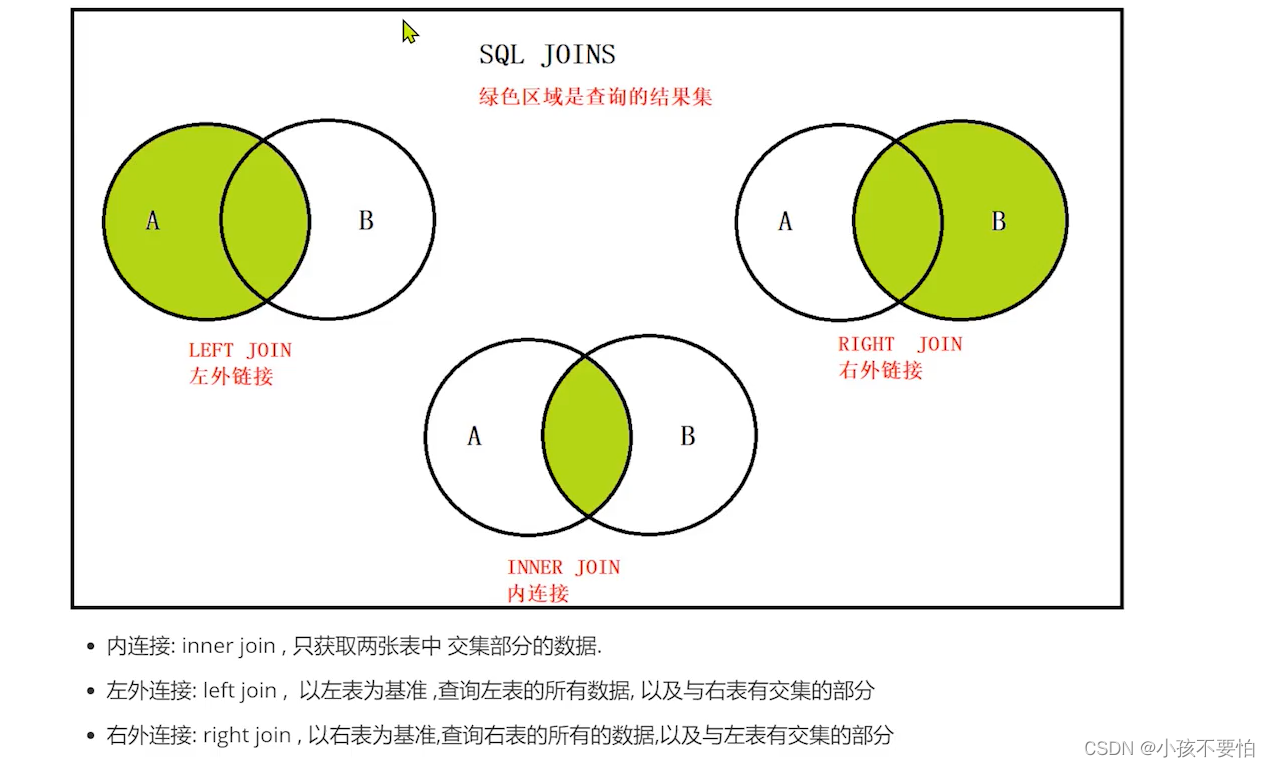
JOIN操作包括:
1.(INNER) JOIN:内连接
2.LEFT (OUTER) JOIN:左外连接
3.RIGHT (OUTER) JOIN:右外连接
4.FULL (OUTER) JOIN:满外连接
ON 连接条件:即ON关键字用于指定连接条件
-
定义:查询的多个字段不在同一个表中时用到多表查询将不同的表连接到一起
-
语法规则:采用sql99语法
-
特点:
- 在多表查询中若查询的字段是唯一的则可以在字段名之前不加表名;若查询的字段不是唯一的,则该字段名之前需要加表名。
- 建议不管字段是否是唯一的,都加上表名。目的是为了避免数据库对多个表的字段进行多次寻找,加上之后数据库对字段只需要在对应表中寻找一次即可。详见6-2
-
注意:
join操作
(INNER) JOIN:内连接
- 定义:
通过指定的条件去匹配两张表中的数据,若匹配的上就显示;匹配不上就不显示。相当于取两者交集
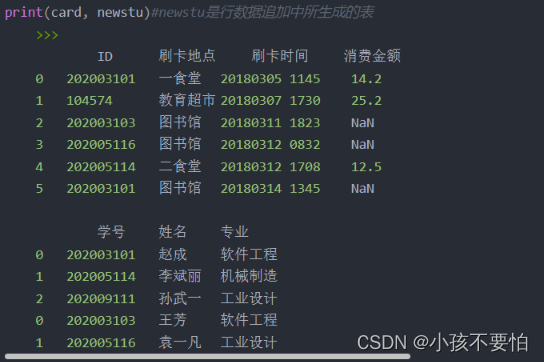
例子详解
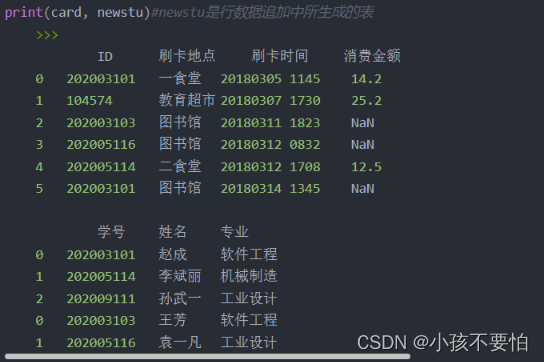
有两张表card和newstu,如图一所示,内连接后如图二所示
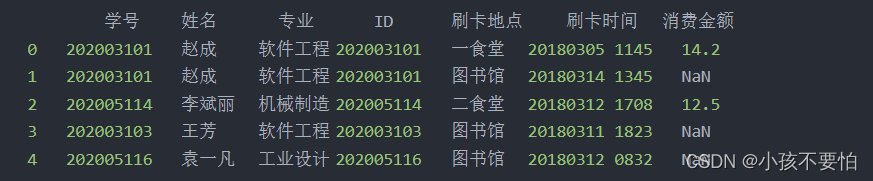
LEFT (OUTER) JOIN:左外连接
- 定义:
以左表为基准,将右表中的数据匹配到左表中。若能匹配上就显示;若匹配不上则左表中的数据正常显示,而右表数据显示为null。(即除了匹配的内容还包括左表中不匹配的内容)
例子详解
有两张表card和newstu,如图一所示
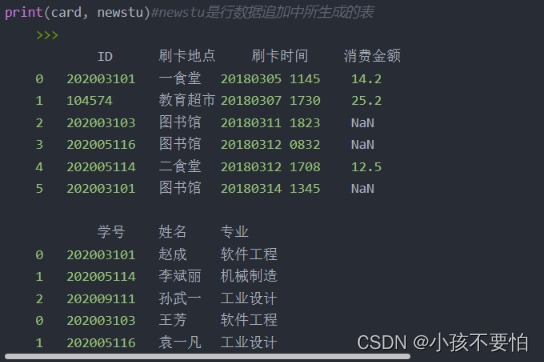
方式一:card为左表,newstu为右表,左外连接后如图所示
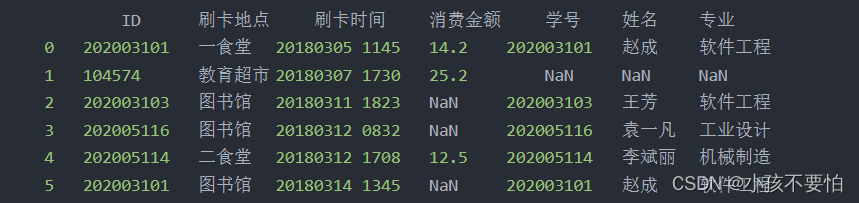
方式二:newstu为左表,card为右表,左外连接后如图所示
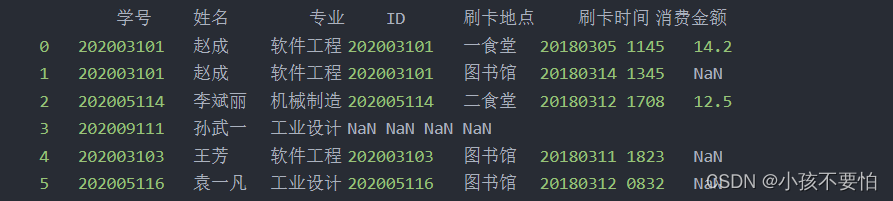
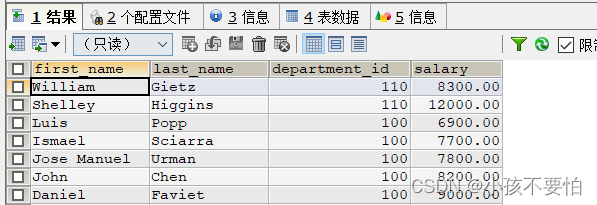
例题1:查询所有员工姓名及员工对应的部门的名称
SELECT e.`first_name`, d.`department_name`
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
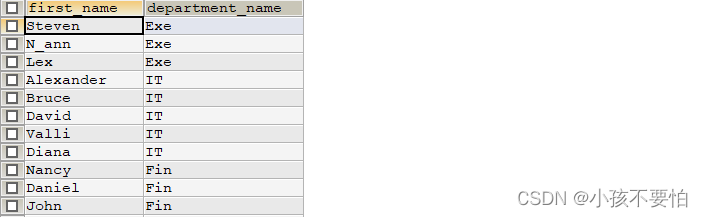
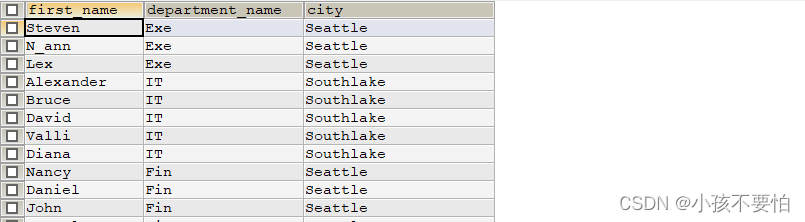
例题2:查询员工的姓名及对应的部门名称以及部门所在城市的名称
SELECT e.`first_name`, d.`department_name`, l.`city`
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
LEFT JOIN locations l
ON d.`location_id` = l.`location_id`;
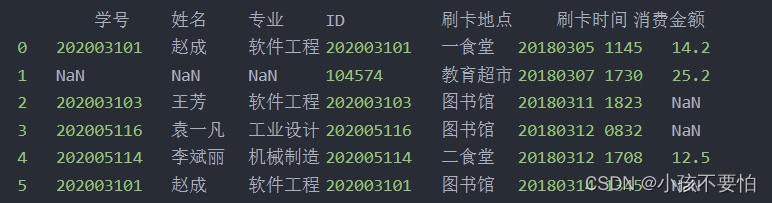
RIGHT (OUTER) JOIN:右外连接
- 定义:
以右表为基准,将左表中的数据匹配到右表中。若能匹配上就显示;若匹配不上则右表中的数据正常显示,而左表数据显示为null。(即除了匹配的内容还包括右表中不匹配的内容)
有两张表card和newstu,如图一所示
方式一:newstu为左表,card为右表,右外连接后如图所示
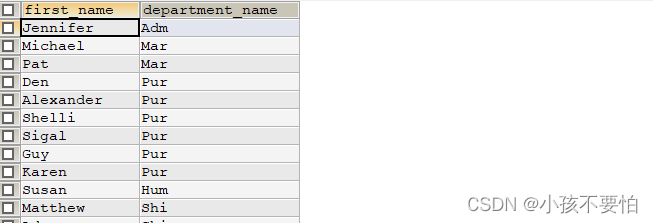
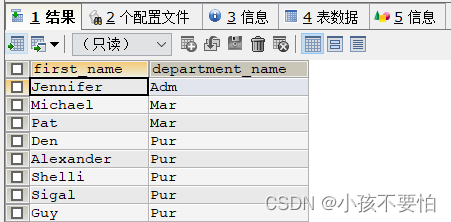
例题:查询所有的部门名称及部门中员工的姓名
SELECT e.`first_name`, d.`department_name`
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
FULL (OUTER) JOIN:满外连接
**定义:**除了匹配的内容还有左表和右表中不匹配的内容
注意: MySQL不支持满外连接代码,所以在执行操作时换种思路来实现满外连接
#UNOIN ALL代表不去除重复的行
左外连接
UNOIN ALL
右外连接
#UNOIN代表去除重复的行
左外连接
UNOIN
右外连接
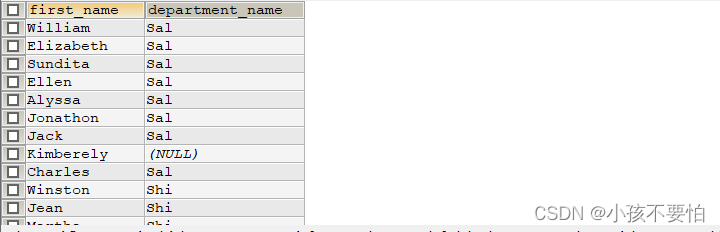
例子:查询所有员工和所有部门名称
SELECT e.`first_name`, d.`department_name`
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
UNION
SELECT e.`first_name`, d.`department_name`
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
6连接方式不同分类
- 方式一:自连接 vs 非自连接
- 方式二:等值连接 vs 非等值连接
- 方式三:内连接 vs外连接
自连接 vs 非自连接
- 自连接:连接的两张表是同一张表(即将一张表看成两张表)
指在一个表中连接该表本身,从而产生一种类似于嵌套查询的效果。自连接通常用于处理层次结构或树状结构的数据,例如员工的管理层次、组织结构等。
举例说明
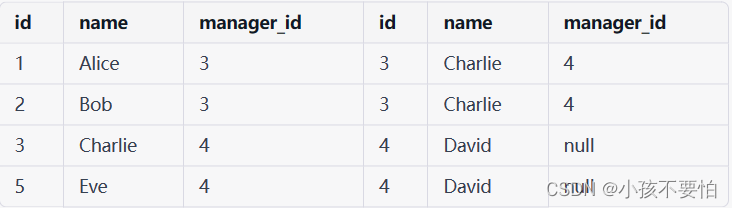
假设我们有一个名为 employees 的表,它包含了公司员工的信息,其中包括每个员工的ID、姓名和经理ID:
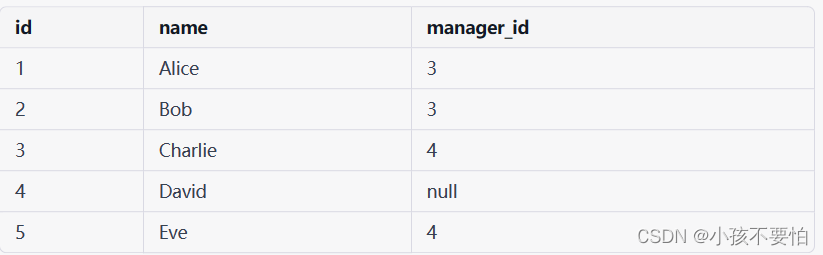
在这个例子中,每个员工都有一个经理,除了公司的最高管理层之外。如果我们想要查找每个员工及其经理的姓名,我们可以使用自连接来完成。如下
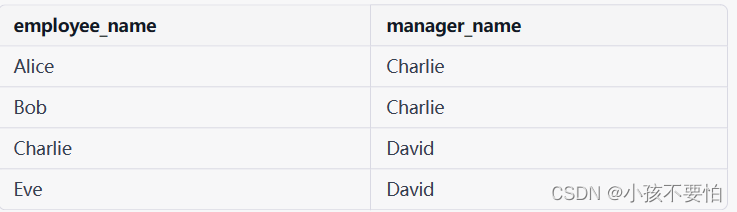
SELECT e.name AS employee_name, m.name AS manager_name
FROM employees e JOIN employees m
ON e.manager_id = m.id;
在上述查询中,我们使用了两个表别名 e 和 m,分别表示员工和经理。通过 JOIN 子句将表连接起来,我们将 e.manager_id 列与 m.id 列进行比较,以查找每个员工的经理。执行上述查询,将会返回以下结果:
注意:
SELECT *
FROM employees e JOIN employees m
ON e.manager_id = m.id;
#该代码块的结果如下:
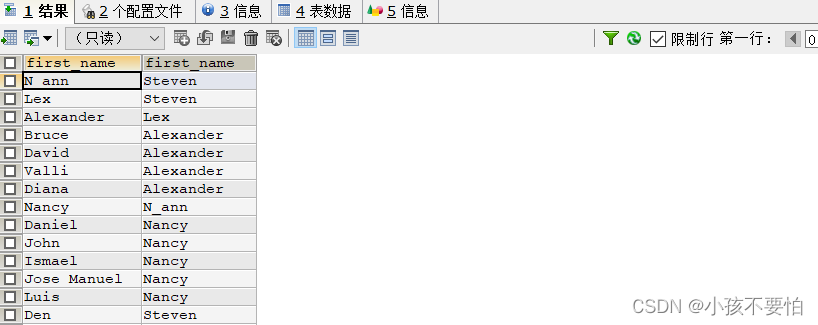
例6-2-1-1:查询员工姓名以及该员工所对应的管理者
#sql99
SELECT e.first_name, m.first_name
FROM employees e JOIN employees m
ON e.employee_id = m.manager_id;
- ==非自连接:==连接的两张表不是同一张表
例6-2-1-2:查询员工的姓名和部门名称
/*sql192*/
SELECT first_name,department_name
FROM employees,departments
WHERE employees.department_id = departments.department_id
/*sql99*/
SELECT e.first_name,d.department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id
例6-2-1-3:查询员工的姓名、部门号和部门名称
注意:因为字段department_id在employees和departments两个表中都存在,所以在你查询部门号时,需要让数据库知道你的部门号用的是哪个表中的部门号,所以第一行代码中写department_id时需要加上表名,为employees.department_id
/*sql192*/
#方式一
SELECT first_name,employees.department_id,department_name
FROM employees,departments
WHERE employees.department_id = departments.department_id
#方式二:都加上表名(推荐)
SELECT employees.first_name,employees.department_id,departments.department_name
FROM employees,departments
WHERE employees.department_id = departments.department_id
#方式三:给表名定义别名以增加都加上表名时的代码输入效率
SELECT e.first_name,e.department_id,d.department_name
FROM employees e,departments d
WHERE e.department_id = d.department_id
/*sql99:*/
SELECT e.first_name,e.department_id,d.department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id
等值连接 vs 非等值连接
- 等值连接
定义:连接条件用的是等号
则在6.1.1中所举的例子均为等值连接
-
非等值连接
-
定义:
多表查询语句中的连接条件不是使用等号的连接
薪水等级表如下
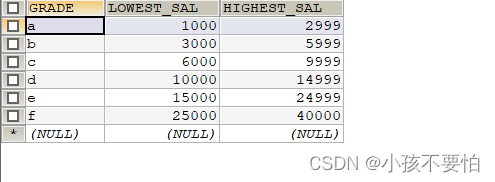
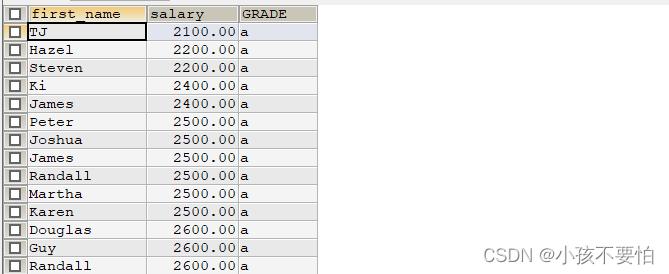
例6-2-2-1:查询员工的薪水以及薪水的等级,并按薪水升序排列
SELECT e.first_name, e.`salary`,g.GRADE
FROM employees e JOIN job_grades g
ON e.`salary` BETWEEN g.`LOWEST_SAL` AND g.`HIGHEST_SAL`
ORDER BY e.salary;
问题
- 将数据放在数组和集合中,与放在文件中的区别?
1.存储方式、位置和时间
数组和集合是存储在RAM(随机存取存储器)中,也就是程序运行时的内存中,且适合存储小规模数据,数据会随着程序的结束而被释放;
而文件是磁盘上的数据结构,其数据是永久存在硬盘上的,适合存储大规模数据,不会随程序的结束而消失
注意:硬盘是一种机械式磁盘
2.访问速度
因为内存的读取速度比磁盘快很多,所以数组和集合的访问速度要比文件快得多
















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











