







文章目录
一、赛题说明
1.1题目说明
赛题链接:“未来杯” 城市-房产租金预测
比赛要求参赛选手根据给定的数据集,建立模型,预测房屋租金。
数据集中的数据类别包括租赁房源、小区、二手房、配套、新房、土地、人口、客户、真实租金等。
这是典型的回归预测。
1.2 预测指标
回归结果评价标准采用R-Square
R2(R-Square)的公式为:
残差平方和:
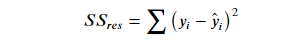
总平均值:
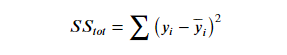
其中
y
ˉ
\bar{y}
yˉ 表示 𝑦 的平均值, 得到
R
2
R^{2}
R2 表达式为:
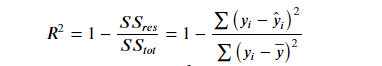
R 2 R^{2} R2 用于度量因变量的变异中可由自变量解释部分所占的比例,取值范围是 0~1, R 2 R^{2} R2越接近1,表明回归平方和占总平方和的比例越大,回归线与各观测点越接近,用x的变化来解释y值变化的部分就越多,回归的拟合程度就越好。所以 R 2 R^{2} R2 也称为拟合优度(Goodness of Fit)的统计量。
y_{i}表示真实值, y ^ i \hat{y}_{i} y^i表示预测值, y i ˉ \bar{y_{i}} yiˉ表示样本均值。得分越高拟合效果越好。
1.3 数据概况
1.租赁基本信息:
- ID——房屋编号
- area——房屋面积
- rentType——出租方式:整租/合租/未知
- houseType——房型
- houseFloor——房间所在楼层:高/中/低
- totalFloor——房间所在的总楼层数
- houseToward——房间朝向
- houseDecoration——房屋装修
- tradeTime——成交日期
- tradeMoney——成交租金
2.小区信息:
- CommunityName——小区名称
- city——城市
- region——地区
- plate——区域板块
- buildYear——小区建筑年代
- saleSecHouseNum——该板块当月二手房挂牌房源数
3.配套设施:
- subwayStationNum——该板块地铁站数量
- busStationNum——该板块公交站数量
- interSchoolNum——该板块国际学校的数量
- schoolNum——该板块公立学校的数量
- privateSchoolNum——该板块私立学校数量
- hospitalNum——该板块综合医院数量
- DrugStoreNum——该板块药房数量
- gymNum——该板块健身中心数量
- bankNum——该板块银行数量
- shopNum——该板块商店数量
- parkNum——该板块公园数量
- mallNum——该板块购物中心数量
- superMarketNum——该板块超市数量
4.其他信息:
- totalTradeMoney——该板块当月二手房成交总金额
- totalTradeArea——该板块二手房成交总面积
- tradeMeanPrice——该板块二手房成交均价
- tradeSecNum——该板块当月二手房成交套数
- totalNewTradeMoney——该板块当月新房成交总金额
- totalNewTradeArea——该板块当月新房成交的总面积
- totalNewMeanPrice——该板块当月新房成交均价
- tradeNewNum——该板块当月新房成交套数
- remainNewNum——该板块当月新房未成交套数
- supplyNewNum——该板块当月新房供应套数
- supplyLandNum——该板块当月土地供应幅数
- supplyLandArea——该板块当月土地供应面积
- tradeLandNum——该板块当月土地成交幅数
- tradeLandArea——该板块当月土地成交面积
- landTotalPrice——该板块当月土地成交总价
- landMeanPrice——该板块当月楼板价(元/m^{2})
- totalWorkers——当前板块现有的办公人数
- newWorkers——该板块当月流入人口数(现招聘的人员)
- residentPopulation——该板块常住人口
- pv——该板块当月租客浏览网页次数
- uv——该板块当月租客浏览网页总人数
- lookNum——线下看房次数
二、数据分析
2.1 总体浏览数据
#coding:utf-8
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')
# GBDT
from sklearn.ensemble import GradientBoostingRegressor
# XGBoost
import xgboost as xgb
# LightGBM
import lightgbm as lgb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#载入数据
data_train = pd.read_csv('F:\\实验\\比赛\\房价预测\\数据集\\train_data.csv')
data_train['Type'] = 'Train'
data_test = pd.read_csv('F:\\实验\\比赛\\房价预测\\数据集\\test_a.csv')
data_test['Type'] = 'Test'
data_all = pd.concat([data_train, data_test], ignore_index=True)
# 总体情况
print(data_train.info())
print(data_train.describe())
data_train.head()
结果(截取部分):



简要分析:
- 该份训练集包含 41440行×52列数据;
- 目标变量是 真实房租价格- tradeMoney;
- 大多数数据都是int或float型;有部分字段是object型,即文本型中文或英文的,如rentType字段,这些字段在之后需要做处理。
2.2 分类特征和连续型特征
# 根据特征含义和特征一览,大致可以判断出数值型和类别型特征如下
categorical_feas = ['rentType', 'houseType', 'houseFloor', 'region', 'plate', 'houseToward', 'houseDecoration',
'communityName','city','buildYear']
numerical_feas=['ID','area','totalFloor','saleSecHouseNum','subwayStationNum',
'busStationNum','interSchoolNum','schoolNum','privateSchoolNum','hospitalNum',
'drugStoreNum','gymNum','bankNum','shopNum','parkNum','mallNum','superMarketNum',
'totalTradeMoney','totalTradeArea','tradeMeanPrice','tradeSecNum','totalNewTradeMoney',
'totalNewTradeArea','tradeNewMeanPrice','tradeNewNum','remainNewNum','supplyNewNum',
'supplyLandNum','supplyLandArea','tradeLandNum','tradeLandArea','landTotalPrice',
'landMeanPrice','totalWorkers','newWorkers','residentPopulation','pv','uv','lookNum']
2.3 缺失值分析
def missing_values(df):
alldata_na = pd.DataFrame(df.isnull().sum(), columns={'missingNum'})
alldata_na['existNum'] = len(df) - alldata_na['missingNum']
alldata_na['sum'] = len(df)
alldata_na['missingRatio'] = alldata_na['missingNum']/len(df)*100
alldata_na['dtype'] = df.dtypes
#ascending:默认True升序排列;False降序排列
alldata_na = alldata_na[alldata_na['missingNum']>0].reset_index().sort_values(by=['missingNum','index'],ascending=[False,True])
alldata_na.set_index('index',inplace=True)
return alldata_na
missing_values(data_train)
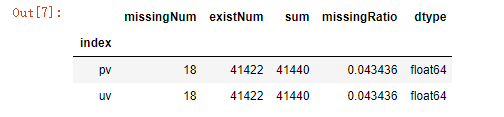
简要分析:
- 这里采用编写函数的方式来直接获取结果(这种方式会在之后反复用到,建议大家尽早养成函数式编写的习惯);
- 其实在总体情况一览中,info()函数也能看出来。
- 结果是,仅有pv、uv存在缺失值,后面再探究会发现缺失的都是属于同一个plate,可能是官方直接删除了该plate的pv、uv。
2.4 单调特征列分析
#是否有单调特征列(单调的特征列很大可能是时间)
def incresing(vals):
cnt = 0
len_ = len(vals)
for i in range(len_-1):
if vals[i+1] > vals[i]:
cnt += 1
return cnt
fea_cols = [col for col in data_train.columns]
for col in fea_cols:
cnt = incresing(data_train[col].values)
if cnt / data_train.shape[0] >= 0.55:
print('单调特征:',col)
print('单调特征值个数:', cnt)
print('单调特征值比例:', cnt / data_train.shape[0])
单调特征: tradeTime
单调特征值个数: 24085
单调特征值比例: 0.5812017374517374
简要分析:
- 先编写判断单调的函数 incresing, 然后再应用到每列上;
- 单调特征是 tradeTime,为时间列。
- 多说句额外的,时间列在特征工程的时候,不同的情况下能有很多的变种形式,比如按年月日分箱,或者按不同的维度在时间上聚合分组,等等。
2.5 特征nunique分布
# 特征nunique分布
for feature in categorical_feas:
print(feature + "的特征分布如下:")
print(data_train[feature].value_counts())
if feature != 'communityName': # communityName值太多,暂且不看图表
plt.hist(data_all[feature], bins=3)
plt.show()
结果(部分截图):

print(data_train['communityName'].value_counts())
print(data_test['communityName'].value_counts())
结果:
XQ01834 358
XQ01274 192
XQ02273 188
XQ03110 185
XQ02337 173
...
XQ01302 1
XQ02870 1
XQ01972 1
XQ02671 1
XQ01787 1
Name: communityName, Length: 4236, dtype: int64
XQ03306 1
XQ00629 1
XQ01830 1
XQ00534 1
XQ02021 1
..
XQ03596 1
XQ03784 1
XQ00332 1
XQ01140 1
XQ00239 1
Name: communityName, Length: 2469, dtype: int64
简要分析:
- 用自带函数value_counts() 来得到每个分类变量的种类分布; 并且简单画出柱状图。
- rentType:4种,且绝大多数是无用的未知方式;
- houseType:104种,绝大多数在3室及以下;
- houseFloor:3种,分布较为均匀;
- region: 15种;
- plate: 66种;
- houseToward: 10种;
- houseDecoration: 4种,一大半是其他;
- buildYear: 80种;
- communityName:4236种,且分布较为稀疏;
- 此步骤是为之后数据处理和特征工程做准备,先理解每个字段的含义以及分布,之后需要根据实际含义对分类变量做不同的处理。
2.6 统计特征值频次大于100的特征
# 统计特征值出现频次大于100的特征
for feature in categorical_feas:
df_value_counts = pd.DataFrame(data_train[feature].value_counts())
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = [feature, 'counts'] # change column names
print(df_value_counts[df_value_counts['counts'] >= 100])
结果(部分截图):

简要分析:
- 此步骤和特征nunique分布结合步骤结合起来看,有一些小于100的是可以直接统一归类为其他的
2.7 Label分布
# Labe 分布
fig,axes = plt.subplots(2,3,figsize=(20,5))
fig.set_size_inches(20,12)
sns.distplot(data_train['tradeMoney'],ax=axes[0][0])
sns.distplot(data_train[(data_train['tradeMoney']<=20000)]['tradeMoney'],ax=axes[0][1])
sns.distplot(data_train[(data_train['tradeMoney']>20000)&(data_train['tradeMoney']<=50000)]['tradeMoney'],ax=axes[0][2])
sns.distplot(data_train[(data_train['tradeMoney']>50000)&(data_train['tradeMoney']<=100000)]['tradeMoney'],ax=axes[1][0])
sns.distplot(data_train[(data_train['tradeMoney']>100000)]['tradeMoney'],ax=axes[1][1])
结果截图:

print("money<=10000",len(data_train[(data_train['tradeMoney']<=10000)]['tradeMoney']))
print("10000<money<=20000",len(data_train[(data_train['tradeMoney']>10000)&(data_train['tradeMoney']<=20000)]['tradeMoney']))
print("20000<money<=50000",len(data_train[(data_train['tradeMoney']>20000)&(data_train['tradeMoney']<=50000)]['tradeMoney']))
print("50000<money<=100000",len(data_train[(data_train['tradeMoney']>50000)&(data_train['tradeMoney']<=100000)]['tradeMoney']))
print("100000<money",len(data_train[(data_train['tradeMoney']>100000)]['tradeMoney']))
结果:
money<=10000 38964
10000<money<=20000 1985
20000<money<=50000 433
50000<money<=100000 39
100000<money 19
简要分析:
- 将目标变量tradeMoney分组,并查看每组间的分布; 可以看出绝大多数都是集中在10000元以内的,并且从图中可以看到该分布是右偏的。
- 这里只是一种实现方式,完全可以将tradeMoney和其他字段一起结合起来查看,比如楼层高低,地区板块。















 7126
7126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









