







期末复习用,主要用来梳理思路,不涉及具体操作界面的实现。
一、实验内容:
(一)为Tiny语言扩充的语法有
1.实现改写书写格式的新if语句;☑️
2.增加for循环;☑️
3.扩充算术表达式的运算符号:+= 加法赋值运算符号(类似于C语言的+=)、求余%、乘方^☑️
4.扩充比较运算符号:=(等于),>(大于)、<=(小于等于)、>=(大于等于)、<>(不等于)等运算符号☑️
5.增加正则表达式,其支持的运算符号有: 或(|) 、连接(&)、闭包(#)、括号( ) 、可选运算符号(?)和基本正则表达式。☑️
6.增加位运算表达式,其支持的位运算符号有 and(与)、or(或)、 not(非),如果对位运算不熟悉,可以参考C/C++的位运算。☑️
(二)对应的语法规则分别为:
1. 把TINY语言原有的if语句书写格式
if_stmt-->if exp then stmt-sequence end | | if exp then stmt-sequence else stmt-sequence end
改写为:
if_stmt-->if(exp) stmt-sequence else stmt-sequence | if(exp) stmt-sequence
2.for语句的语法规则:
(1) for-stmt-->for identifier:=simple-exp to simple-exp do stmt-sequence enddo 步长递增1
(2) for-stmt-->for identifier:=simple-exp downto simple-exp do stmt-sequence enddo 步长递减1
3. += 加法赋值运算符号、求余%、乘方^等运算符号的文法规则请自行组织。
4.=(等于),>(大于)、<=(小于等于)、>=(大于等于)、<>(不等于)等运算符号的文法规则请自行组织。
5.为tiny语言增加一种新的表达式——正则表达式,其支持的运算符号有: 或(|) 、连接(&)、闭包(#)、括号( ) 、可选运算符号(?)和基本正则表达式,对应的文法规则请自行组织。
6.为tiny语言增加一种新的语句,ID:=正则表达式
7.为tiny语言增加一种新的表达式——位运算表达式,其支持的运算符号有 and(与) 、or (或)、非(not)。
8.为tiny语言增加一种新的语句,ID:=位运算表达式
9.为了实现以上的扩充或改写功能,还需要注意对原tiny语言的文法规则做一些相应的改造处理。
Tiny语言原来的文法规则,可参考:云盘中参考书P97及P136的文法规则。
二、实验思路
看起来很ex对不对?是的,你没看错,它就是很ex。
三、知识点梳理
大局!
这部分我也不会,所以复习时知识点会覆盖的比较全面。
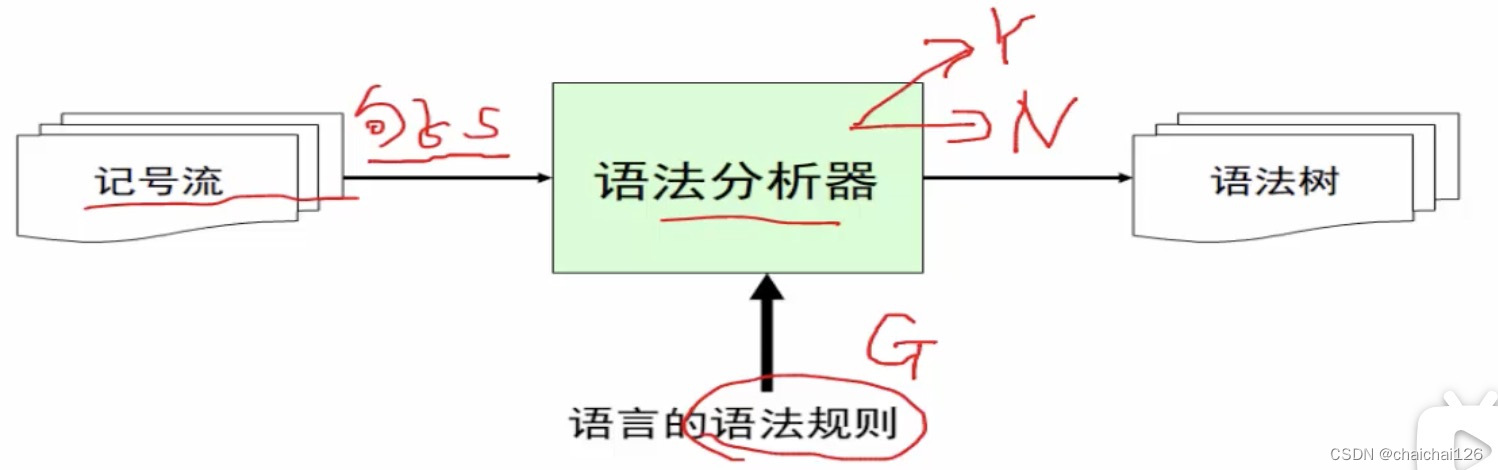
结束了词法分析器,我们就即将进入语法分析器的构造了。
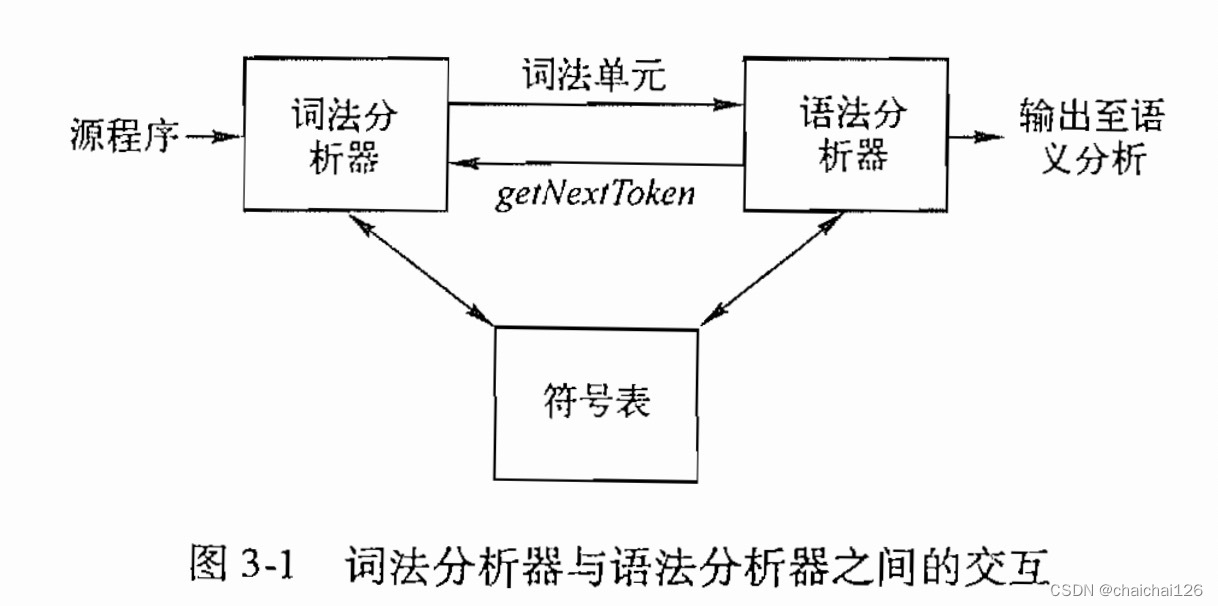
还记得图3-1吗?它是从词法分析器到语法分析器的构造,词法分析器用来给语法分析器自己分析好了的词法单元,语法分析器向词法分析器发送获得下一个Token的命令。
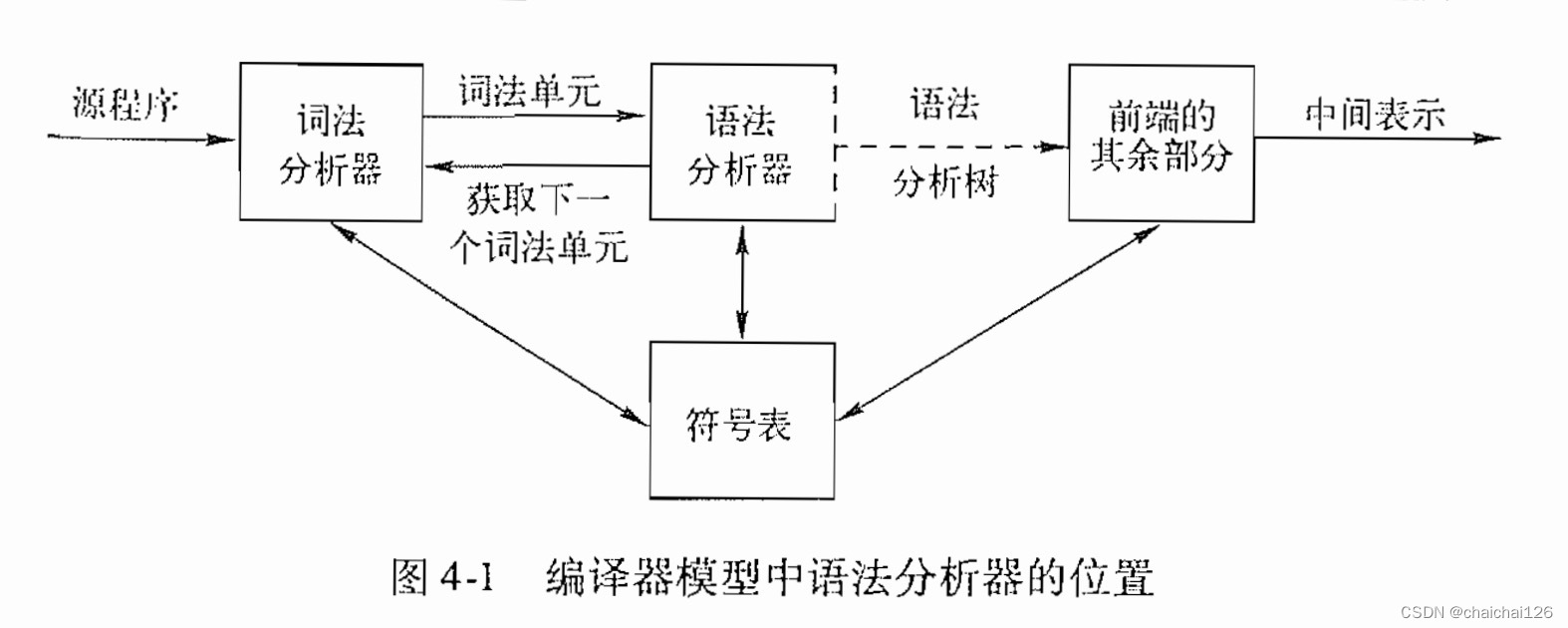
图4-1是编译器模型中语法分析器的位置,编译器中常用的方法可以分为自底向上和自顶向下的,自顶向上,就是从叶子节点开始向上构造语法树,自顶向下,就是从根节点开始,向下构造语法树。
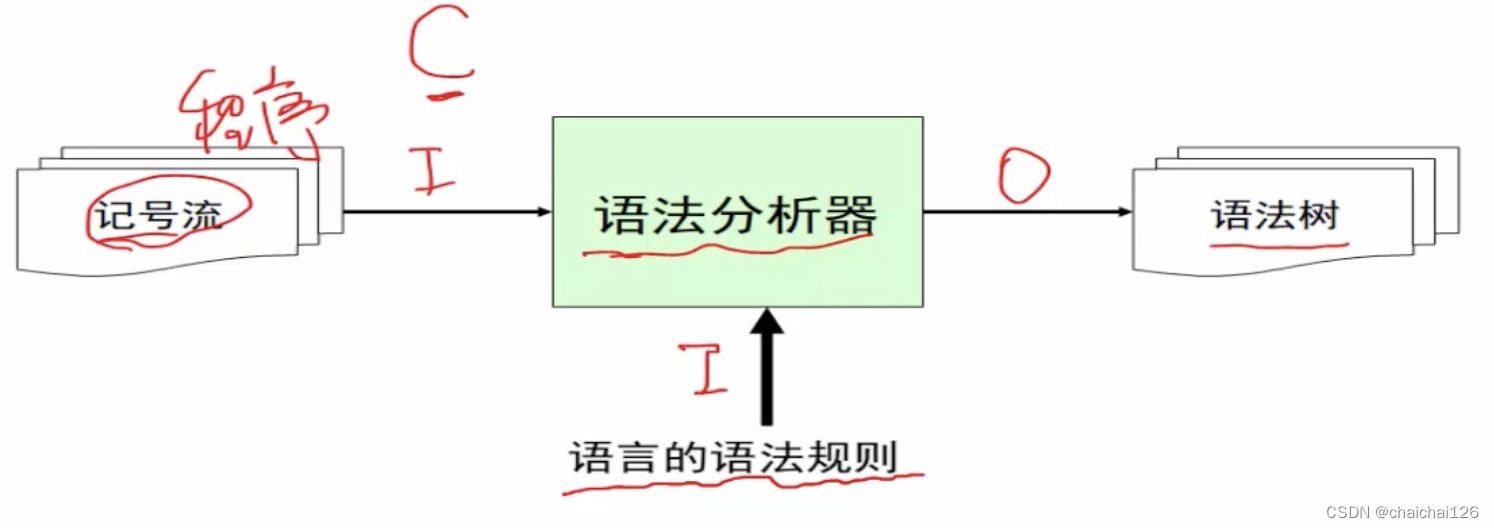
词法分析器用来给语法分析器自己分析好了的词法单元,我们称其为记号流。
语法分析器的输入就是记号流,另一个隐含的输入是语言的语法规则,输出为语法树。
经过词法分析实验后,我们可以得到记号流,但语言的语法规则应该如何实现?或者说,如何在计算机里被表示呢?这就要说到上下文无关文法。
上下文无关文法
在之前的词法分析器里学到的正则式,它可以表示词法
上下文无关文法,它可以表示语法
我们可以把上下文无关文法看作一个四元组:G = (T, N, P, S)
T:终结符集合 N:非终结符集合 P:一组产生式规则 S:唯一的开始符号
注意:规则的形式都类似X -> a的形式
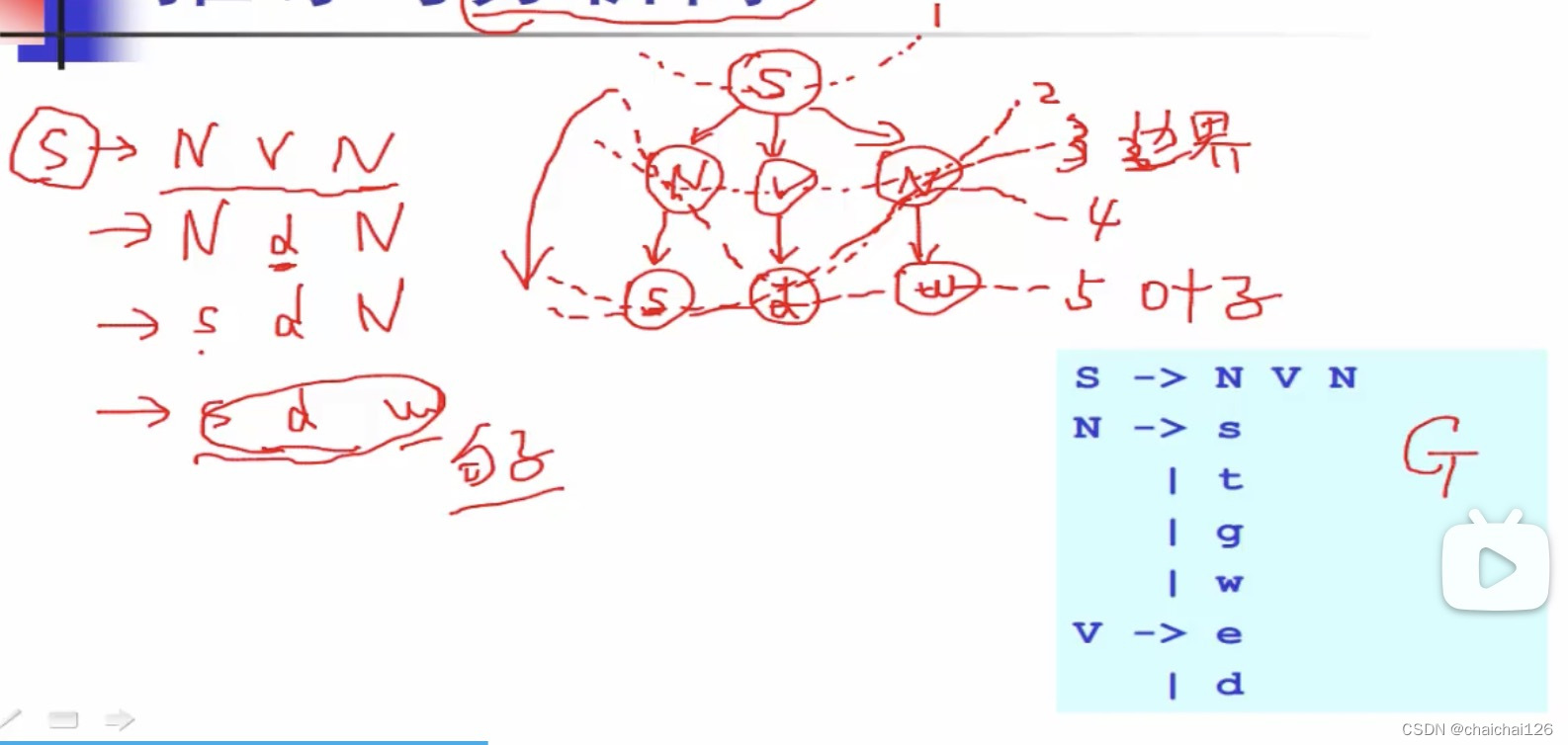
【实例】:

红框框起来的部分就是上下文无关文法G,‘|’表示或
这个文法的意思是把正常的句子抽象出来,是一个名词+动词+名词的组合(S -> NVN)
其中,可选名词有4种(N -> ...);可选动词有2种(V -> .....)
在词法分析最小DFA实验里,我们学到了终结和非终结的概念,在语法分析里也差不多,我们可以简单地把左式认为是非终结符(比如说例子中的S、N、V),它一般用大写字母表示,把右式中左式没有出现过的符号认为是终结符,它一般用小写字母表示。非终结符集合和终结符集合不重叠。
同学们可能经常看到一句话:“直到不出现非终结符为止,最终的串称为句子。”
什么意思?

举个例子:
蓝框内为给定的文法G。

有意思的问题:文法G可以推出多少个不同的句子?
答案是4*2*4 = 32
语言,就是一切句子的集合,比如说文法G推出的32种句子,就组成了一种语言。
最左推导和最右推导
刚才引入了推导的概念,现在着重整理一下在语法分析中重要的两个推导。
最左推导,顾名思义,就是每次选择最左侧的符号进行替换。
举个例子:
还是拿刚才上下文无关文法部分的文法G举例,当我没有规定推导的顺序时,每一步推导可以随便选定符号,比如说这个例子,我第一次选定了‘V’进行推导,第二次选定了‘N’进行推导。

但如果是最左推导,我每次只能选定最左边的符号进行推导:
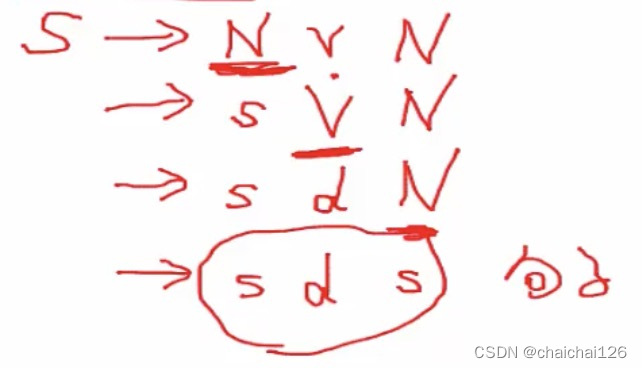
最右推导,顾名思义,就是每次选择最右侧的符号进行替换。
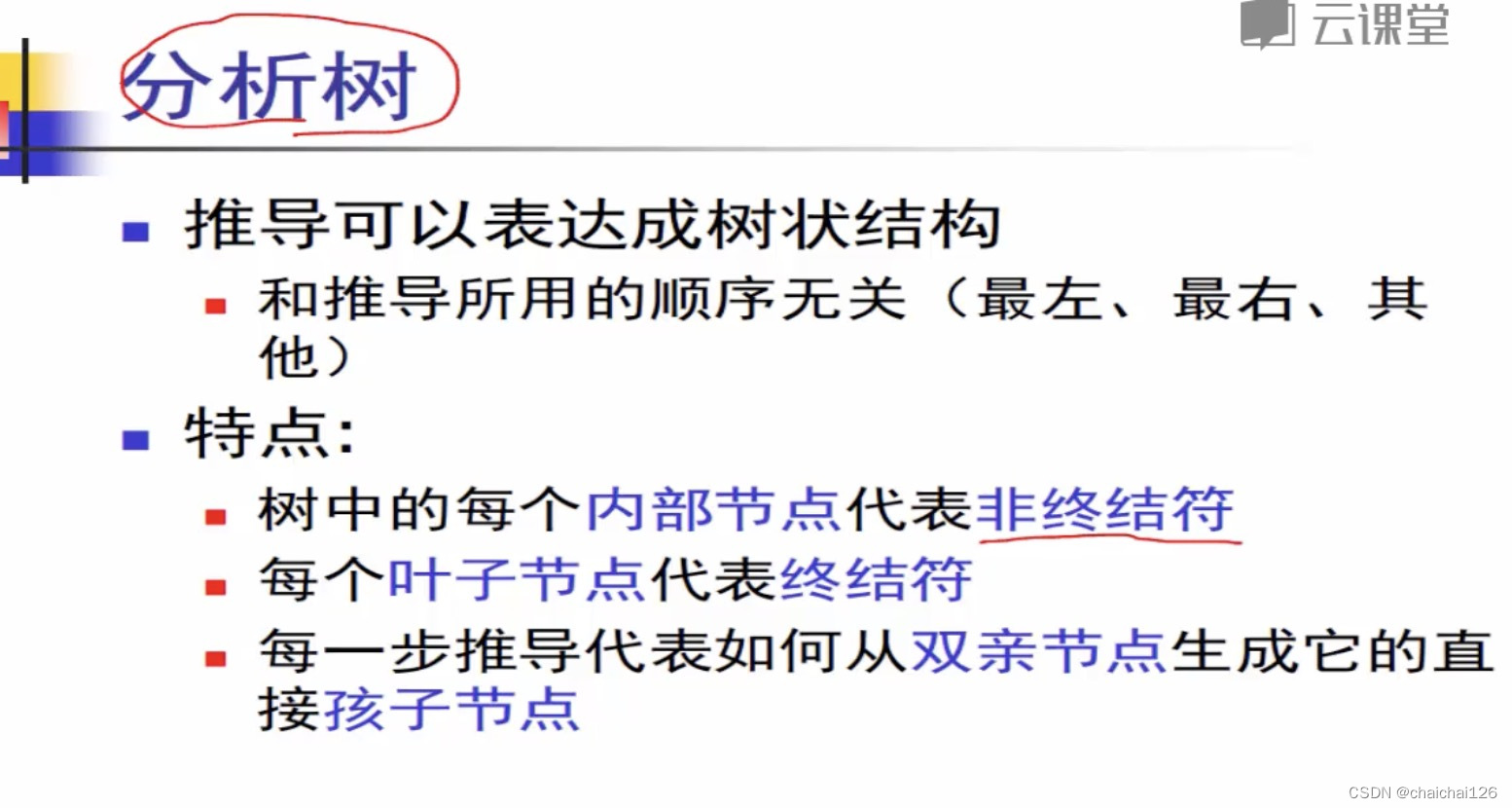
推导与分析树
引入上下文无关文法和推导的概念后,我们就可以表示语言的语法规则了。
回过头来看这张图,我们可以说,语法分析器的作用就是:回答文法G是否存在对句子s的推导。(我们可以把记号流看作是一个句子s)
我们可以将推导表现为树状结构
图片比较潦草,所以文字描述一下:
首先,我们将开始符号S作为根节点,开始推导,将S划分为1号边界
S -> NVM,将其写入树中,将SVM划分为2号边界
NVM -> sVM,将s写入树中,将sVM划分为3号边界
sVM -> sdM,将d写入树中,将sdM划分为4号边界
sdM -> sdw,将w写入树中,将sdw划分为5号边界
我们发现,5号边界组成了最后的句子,也可以说是叶子节点组成了最后的句子。
所以我们可以把分析树构造过程视为从根节点不断扩展,最终叶子节点构成最后的句子。
有趣的问题:对分析树进行什么顺序的遍历,可以得到最终的句子?
答案:后序遍历
将分析树的特点总结如下:
顺便提一嘴规约,规约就是推导的逆过程,目前实验还用不到,所以就不赘述了。
实验中要构建语法分析树,所以我们先讨论它需要有怎样的数据结构:
我们需要确定:(1)每个节点在语法分析树中的位置。(2)各个节点中的相互关系。
写出语法分析树的存储结构:

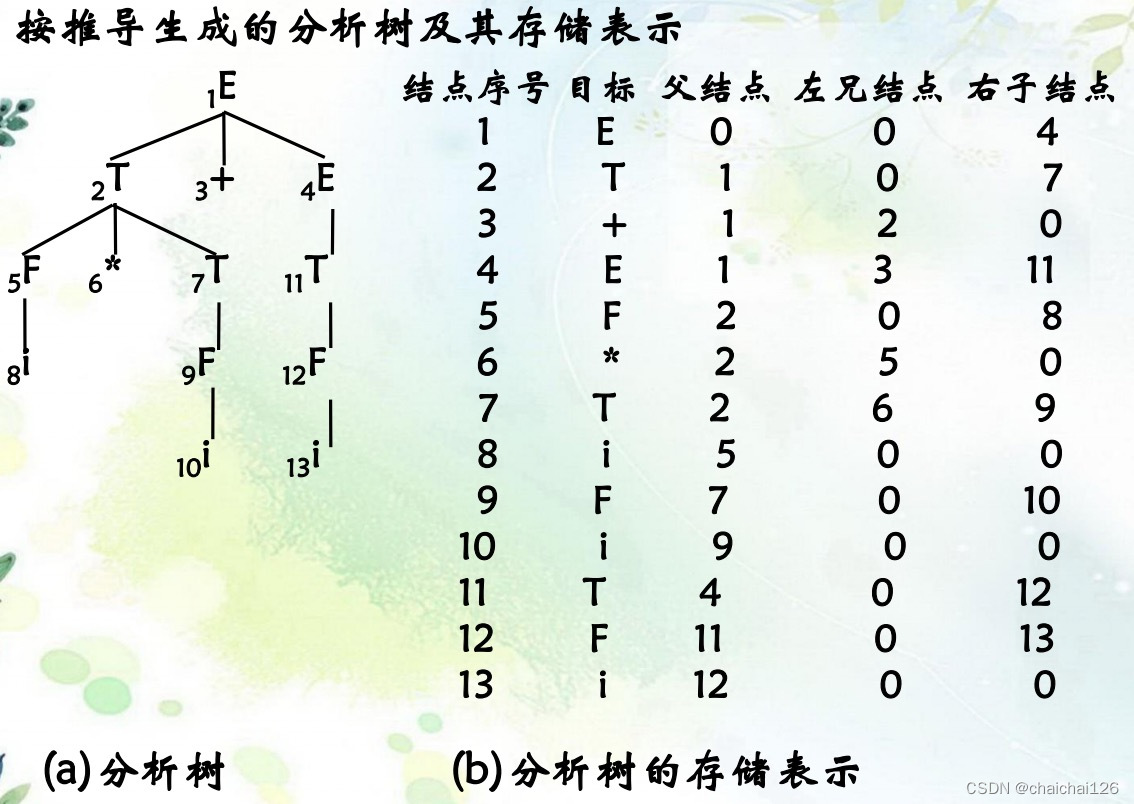
看起来构造过程有些复杂,我们来仔细分析一下,其实分析树就是模拟了我们手动的整个推导过程,还是拿这棵树举例。
从开始符开始,将它建立为根节点,寻找根节点可能与当前句子匹配的推导,作为开始符的子节点,现在我们得到了:
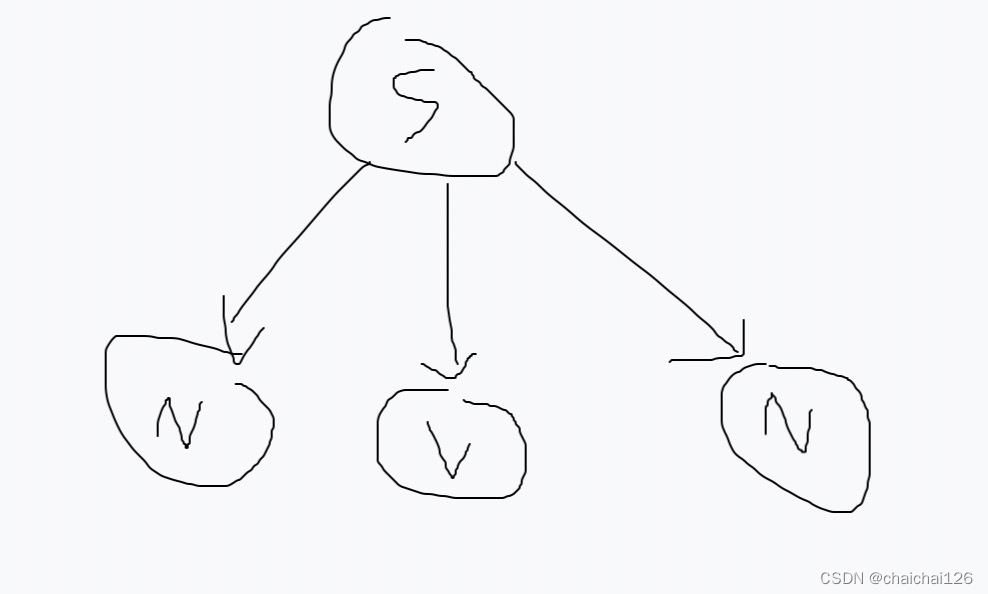
然后还没结束,从左到右检查开始符的子节点,发现仍然存在非终结符,从最左(最先发现)的非终结符开始处理:找到该非终结符对应的推导,选择可以匹配当前句子的推导。
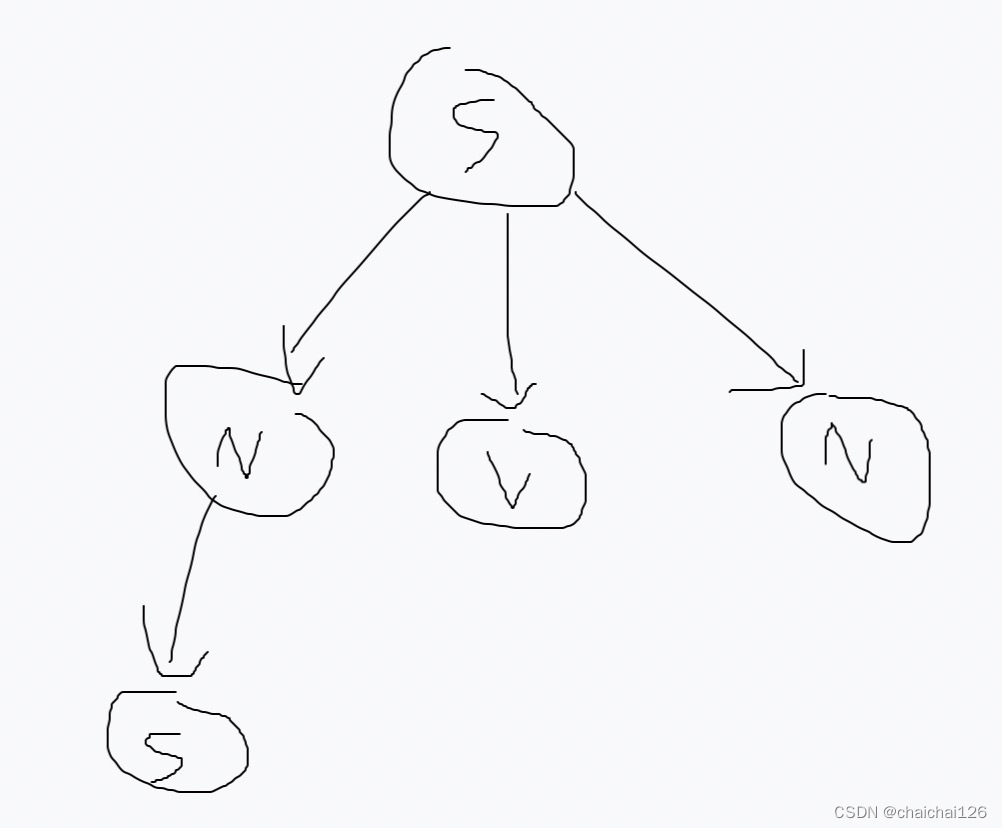
从左到右检查N的子节点,发现不存在非终结符,往上走,从左到右看N所在层是否存在非终结符,发现仍然存在非终结符,从最左(最先发现)的非终结符开始处理:找到该非终结符对应的推导,选择可以匹配当前句子的推导。
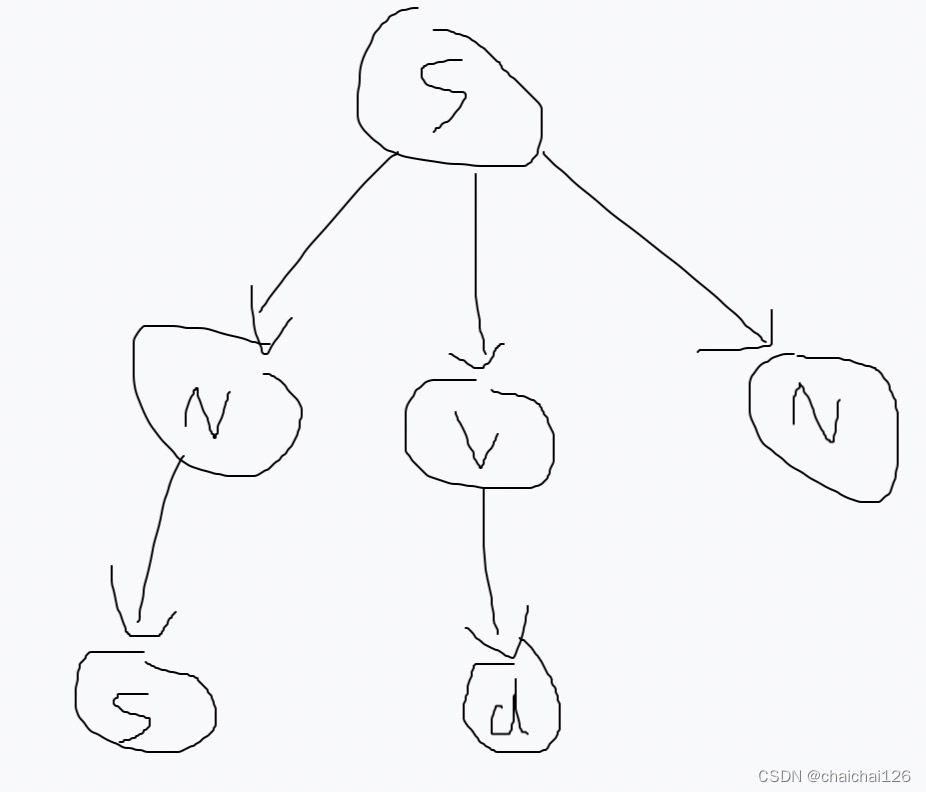
从左到右检查V的子节点,发现不存在非终结符,往上走,从左到右看V所在层是否存在非终结符,发现仍然存在非终结符,从最左(最先发现)的非终结符开始处理:找到该非终结符对应的推导,选择可以匹配当前句子的推导。
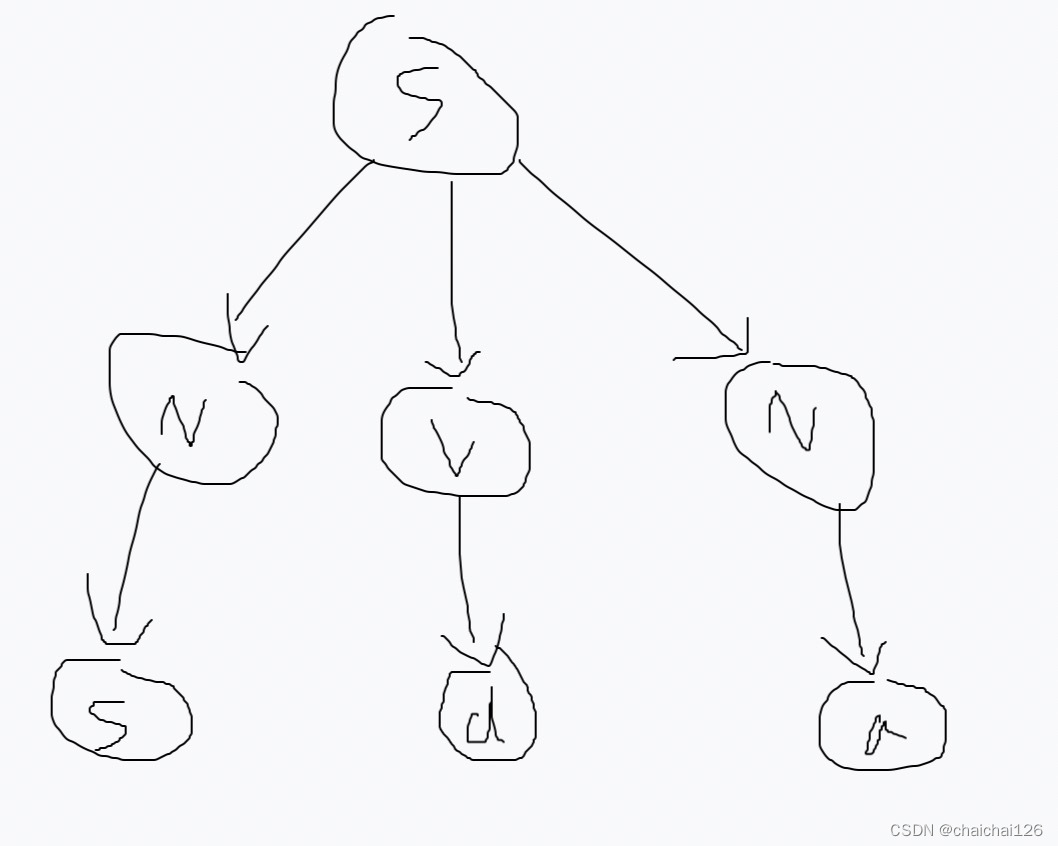
从左到右检查N的子节点,发现不存在非终结符,往上走,从左到右看V所在层是否存在非终结符,发现不存在非终结符,往上走,一直走到根节点,构造结束。
代码如下:
分析树的优点是可以反映推导过程,比较全面。
缺点是过于复杂,耗费空间,所以为了节省空间,引出语法树的概念。
附加部分:
我们也可以通过构造词法分析树的方式获得正则表达式的运算顺序。
语法树
为了节省空间,我们压缩分析树,只存储其中有用的信息,构造语法树。
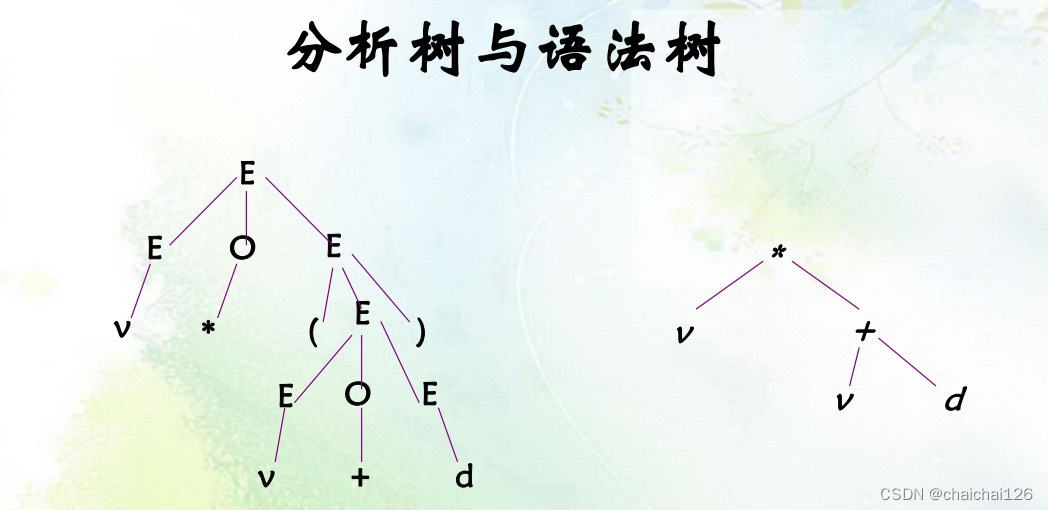
假如我们需要推导的句子是v*v+d,最终由推导得到了左边的分析树。
我们发现,最终有用的信息是v*v+d,所以我们将左边的分析树简化为右边的语法树。
在PPT里我们看到这句话,可能有些难以理解,此处解释“无法还原记号序列”的原因。

记号序列 = 记号产生的顺序
我们可以看到,分析树的每个叶子节点都代表源代码的一个记号,其余内部节点都表示其对应的语法规则,所以我们可以通过倒推分析树从而还原推导顺序,即记号产生的顺序。
而语法树所有节点都是源代码的记号,无其推导所对应的语法规则,所以我们无法还原记号的序列。
算术表达式对应语法树C语言描述:
我们知道,算术表达式中对后续分析有用的信息就是标识符(a,b),运算符(+\-\*\/),常数值(1,2),所以在语法分析树中,我们需要保留上述信息。
typedef enum{Plus, Minus, Times, Division} OpKind;//运算符类型
typedef enum{OpKind, ConstKind, VarKind} ExpKind;//式子类型:运算符/常数/标识符
typedef struct streenode{
ExpKind kind;//式子类型:运算符/常数/标识符
OpKind op;//若为运算符,运算符类型
struct *lchild, *rchild;//左右节点
int val;//若为常数,常数的值
char varname[20];//若为标识符,标识符
}STreeNode;
typedef STreeNode *Syntax Tree;条件判断语句的语法树C语言描述:
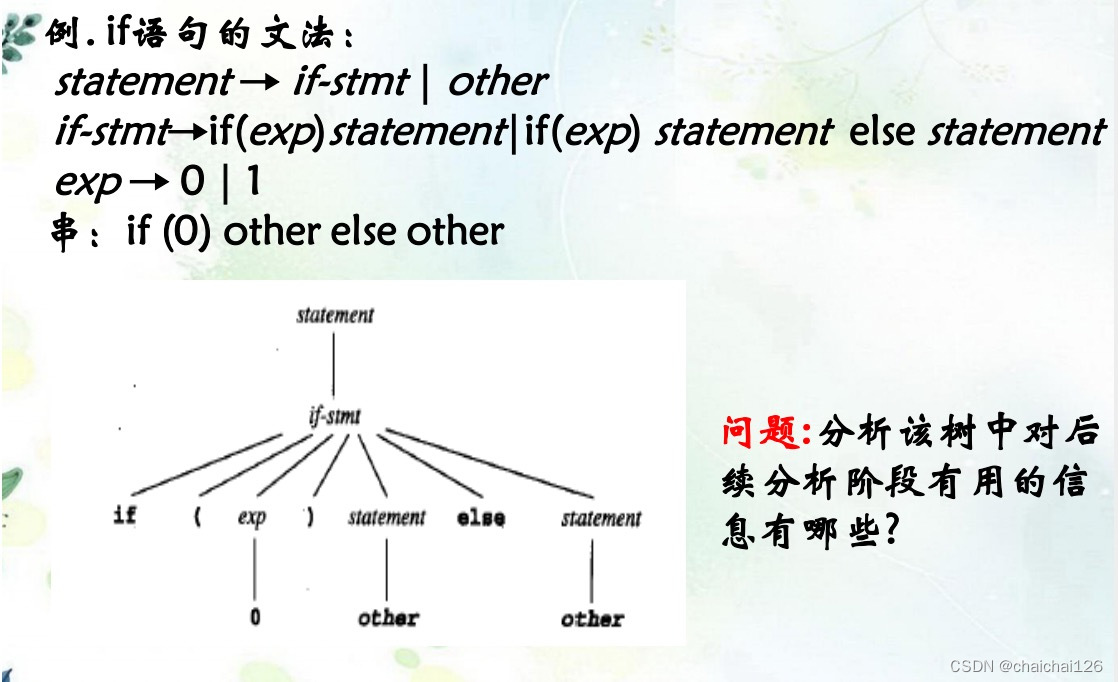
同样我们需要分析,if语句中什么对后续分析有用?
(1)测试表达式exp,即if(测试表达式exp)
(2)通过测试表达式后执行的动作statement,即if(exp) {statement}
statement简写为Stmt
(3) else部分(如果出现的话)
所以我们需要在if的语法分析树中保留上述信息:
typedef enum{ExpK, StmtK}NodeKind;
typedef enum{Zero, One}ExpKind;
typedef enum{IfK, OtherK}StmtKind;
typedef struct streenode{
NodeKind kind;
ExpKind ekind;
StmtKind skind;
struct streenode *test, *thenpart, *elsepart;
}STreeNode;
typedef STreeNode *Syntax Tree; 作为练习,研究一下repeat,assign语句的语法树C语言描述:
repeat:
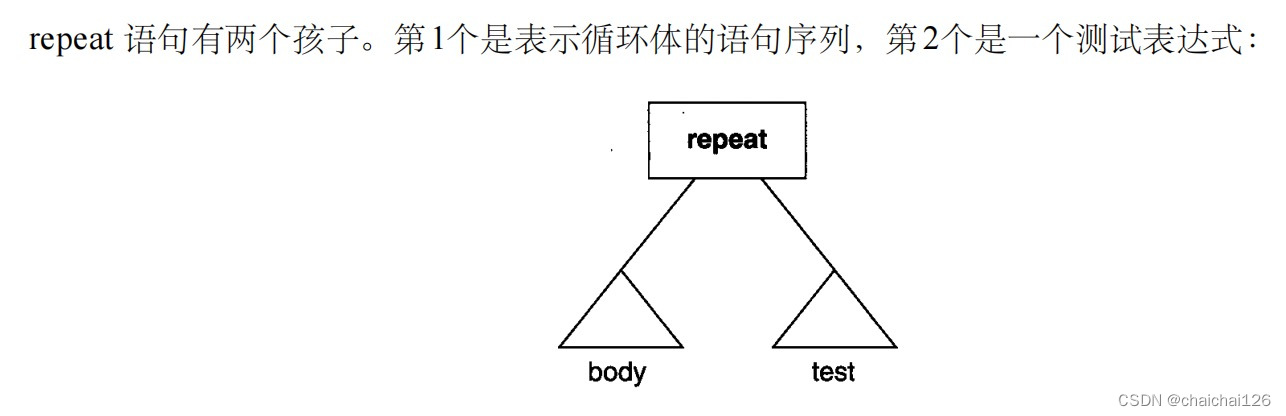
同样分析,repeat语句里什么信息是有用的,我们就在语法树里保留这些信息:
(1)测试表达式exp
(2)body里的执行动作statement
typedef enum{ExpK, StmtK}NodeKind;
typedef enum{Zero, One}ExpKind;
typedef enum{RepeatK, OtherK}StmtKind;
typedef struct streenode{
NodeKind kind;
ExpKind Ekind;
StmtKind sKind;
struct streenode *test, *body;
}STreeNode;
typedef STreeNode* Syntax_Tree;assign:
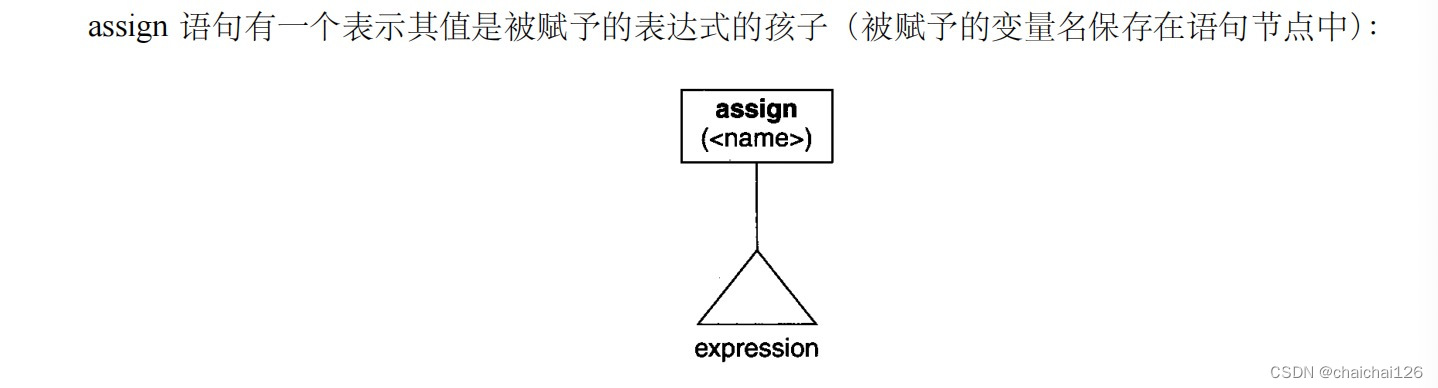
有时候这些书写得有种生怕被读懂的美。
说人话,就是我们在赋值时,比如a = 12*5 ,我们把变量a存在父节点,将赋予它的表达式12*5存在子节点。
同样分析,assign语句里什么信息是有用的,我们就在语法树里保留这些信息:
(1)赋予变量的表达式exp
(2)变量名
typedef enum{ExpK, NameK}NodeKind;
typedef enum{Plus, Minus, Times, Division}OpKind;
typedef enum{OpKind, ConstKind}ExpKind;
typedef struct streenode{
Nodekind kind;
ExpKind ekind;//如果是表达式,存储表达式类型
OpKind okind;//如果是符号,存符号类型
int val;//如果是常量,存常量
char Name[20];//如果是名字,存名字
struct streenode* exp;
}STreeNode;文法分类与书写方法
文法分类
之前说到,我们可以把上下文无关文法看作一个四元组:G = (T, N, P, S)
其实我们可以把所有类型的文法看作一个四元组G = (T, N, P, S),T,N,P,S含义不变。
但我们可以通过对产生式施加不同的限制,把文法及其对应的语言分为四种类型:0型、1型、2型、3型。
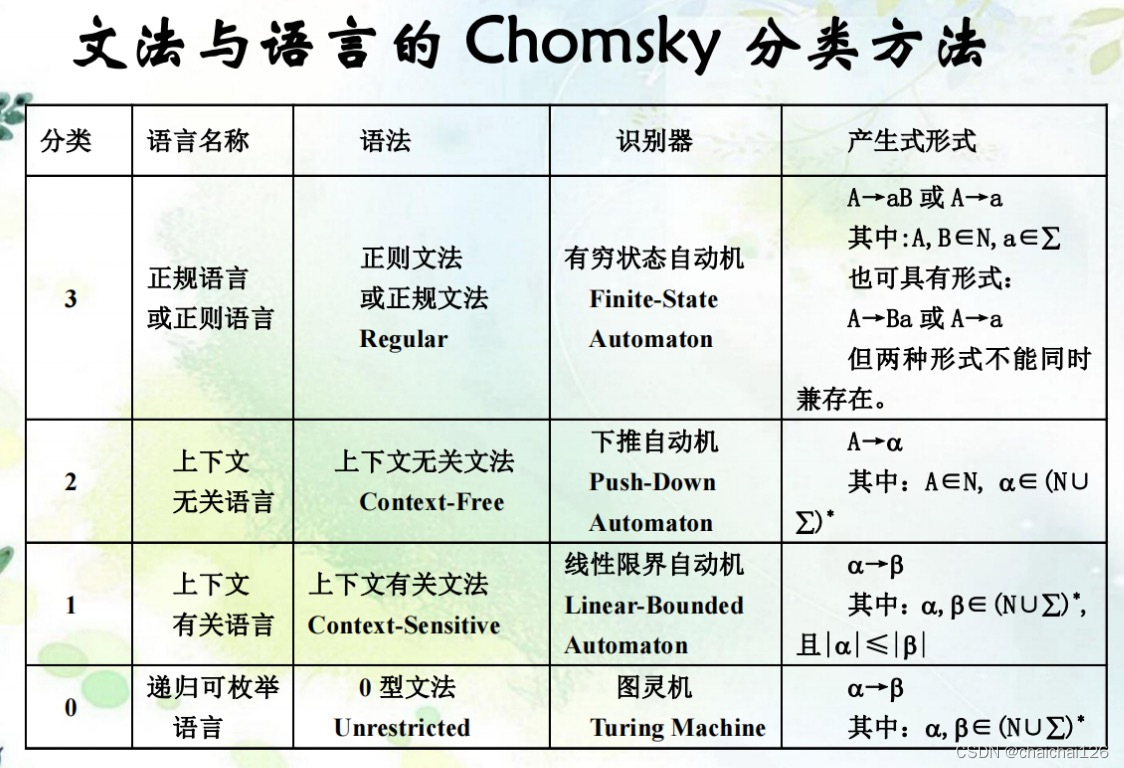
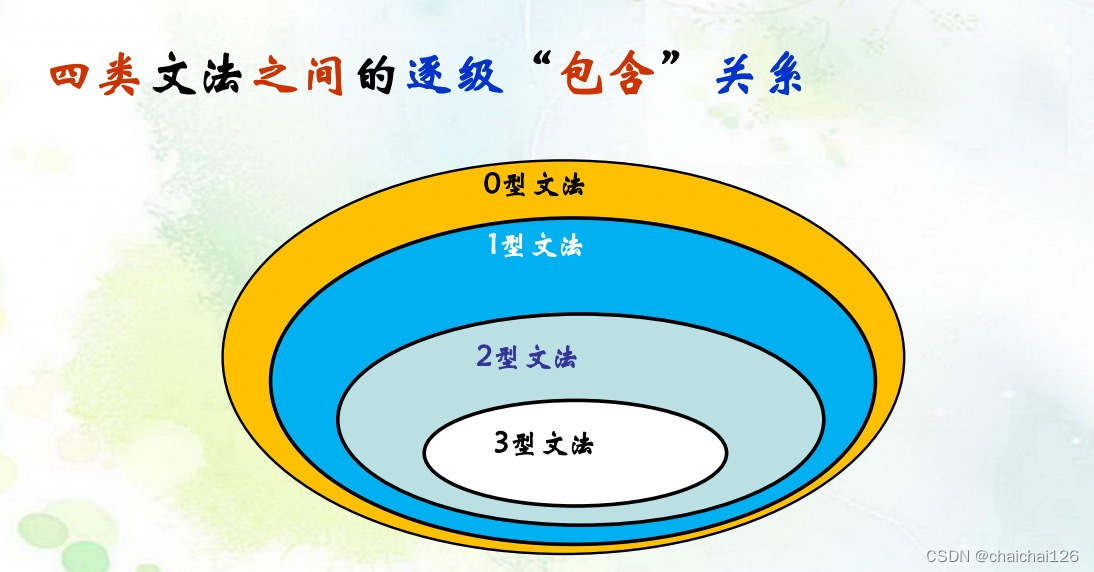
书写方法:

首先,文法有四要素,G = {T, N, P, S}
我们将开始符设定为S,T = {a, b, c}, N = {S, S1, S2, S3 }
由于i,j,k >= 1
构造文法G如下:
1. S -> A B C
2. A -> aA | ε
3. B -> bB | ε
4. C -> cC | ε

首先,文法有四要素,G = {T, N, P, S}
我们将开始符设定为S,T = {a, b}, N = {M}
由于i >= 0
文法G如下:
S -> aN
N -> bN | ε
重点来了,不会推也得背下来

我们可以很容易地写出下列文法:
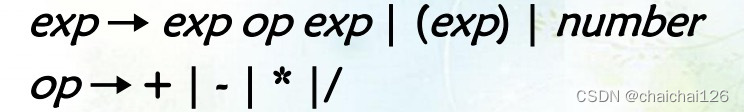
但我们注意到,算术表达式运算符是有优先级的,但在刚才写出的文法中,我们没有表现出运算符的优先级,所以需要改写文法。

最后将文法改写如下:

由刚才的改写,我们可以归纳出一条重要的结论:语法树中谁深谁优先。
除了写出文法规则,我们还需要分析文法中规则是否有效的问题,我们需要删除文法中无效的规则,即有害规则和多余规则。

二义性文法
给定文法G,若存在句子S,它可以画出两棵不同的分析树,则G是二义性文法。
再举一个例子:
以下给出文法G,回答是否存在对句子3+4*5的推导
我们按照文法规则,写出了两个不同的最左推导和其对应的分析树
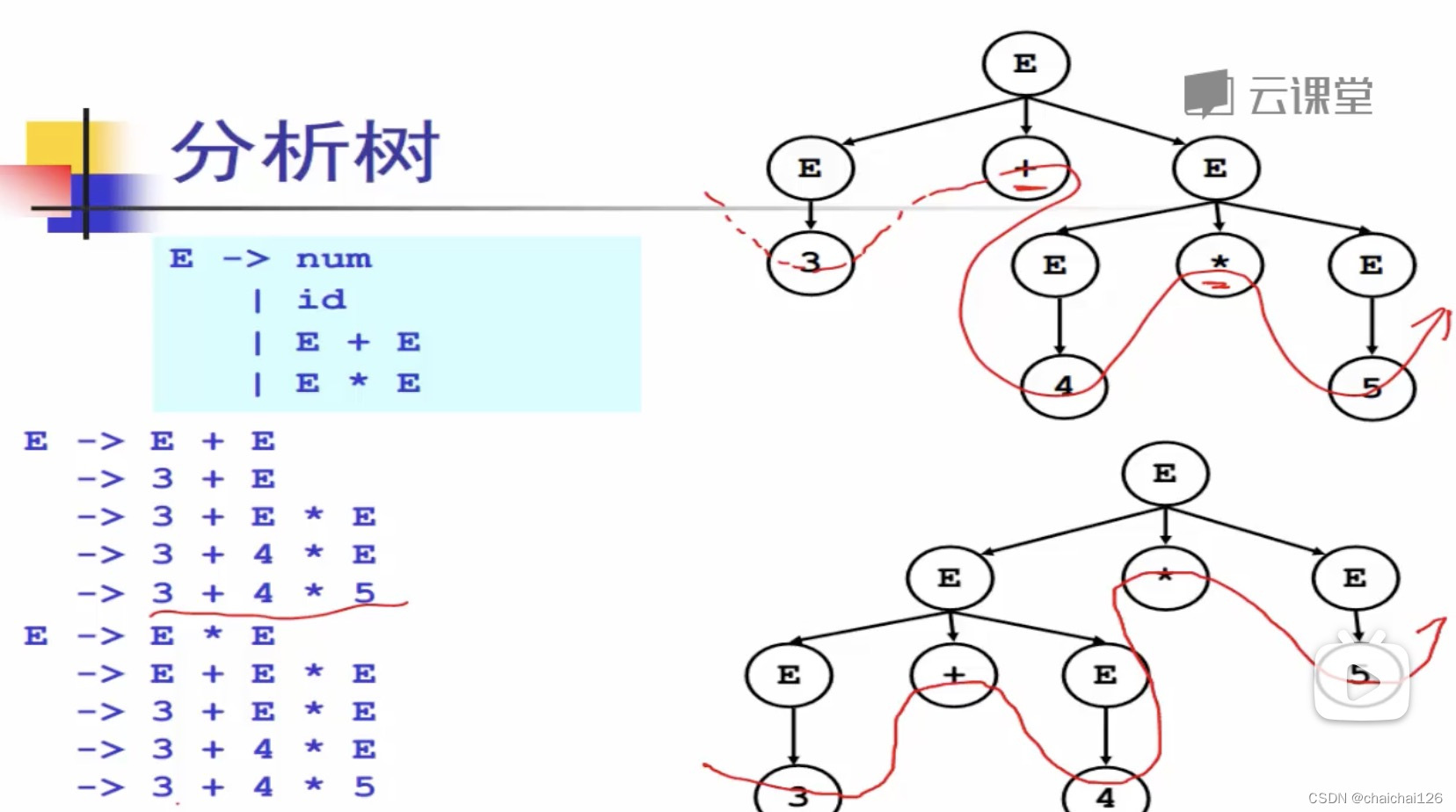
我们规定,以后序遍历(左右根)的方式,取得最终的句子(分析树的含义)
所以第一棵分析树的计算顺序是3+4*5
第二棵分析树的计算顺序是(3+4)*5
此刻我们的文法就出现了歧义,也就是有二义性。
为什么要消除二义性?
因为二义性会导致同一个程序有不同含义,从而导致程序运行结果不唯一。
所以就要进行二义性文法的重写,使其无歧义:
重写没有套路,具体问题具体分析。
将刚才的文法重写如下:

仔细观察刚才的文法,它生成分析树满足了加法的左结合性,所以消除了二义性。
再举一个在具体程序实现中,消除二义性的例子:else的悬挂问题

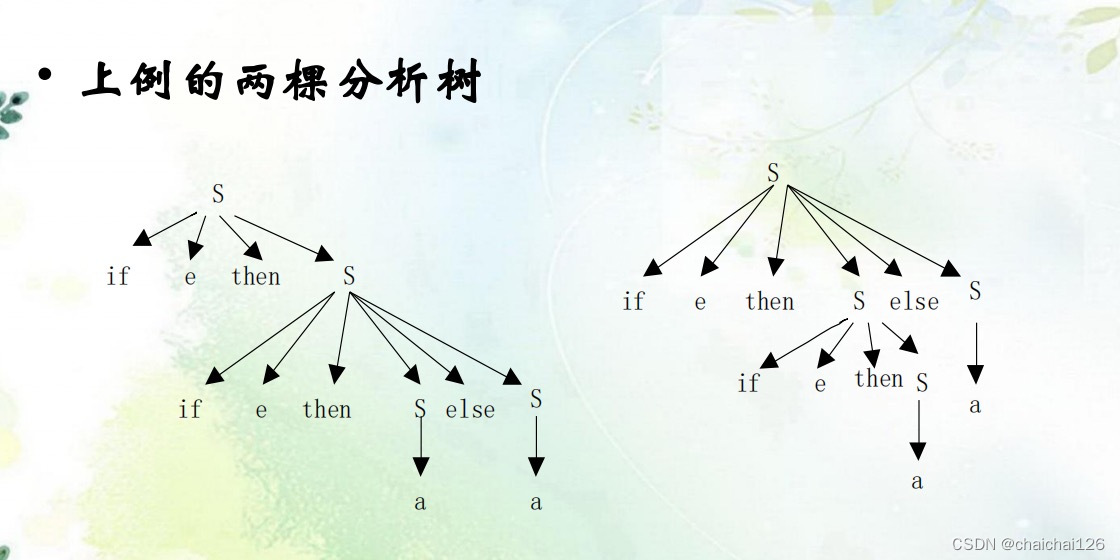
分析引起歧义的原因,是因为我们不知道应该在哪里悬挂else。
解决方法1:设置一个限制规则,在分析程序中实现。
即,else要与最近的上一个未被匹配的if匹配。
解决方法2:改造文法:

解决方法3:重新设计书写语法:
方案1:else一定出现。
引起歧义的原因是else悬挂问题,即我不知道什么时候else应该出现,那我在每一个if后面必须挂一个else,问题就解决了。

方案2:使用一个if匹配的关键字来作为语句的结束。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3142
3142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









