







LEARNING ON LARGE-SCALE TEXT-ATTRIBUTED GRAPHS VIA VARIATIONAL INFERENCE
ICLR23
推荐指数:#paper/⭐⭐#
作者的写作手法感觉就是有点把模型往数学化的方式去写,内容其实就相当于一个LM与GCN互相提供伪标签监督。利用KL散度来优化有点意思
动机
关键挑战
- 传统方法同时训练LLMs和GNNs时,计算复杂度高,难以扩展到大规模图数据。
方法创新:GLEM框架
-
交替训练机制:
- E步:固定GNN参数,GNN预测的伪标签与观察到的标签一起用于LM训练,使其学习与图拓扑一致的文本表示。
- M步:固定LLM参数,LM提供文本嵌入和伪标签给GNN,提升结构建模能力。
-
模块解耦:避免同时训练两个大模型,显著降低计算开销。
-
互增强机制:LLM和GNN通过交替更新互相提供监督信号(伪标签),逐步提升整体性能。
模型细节
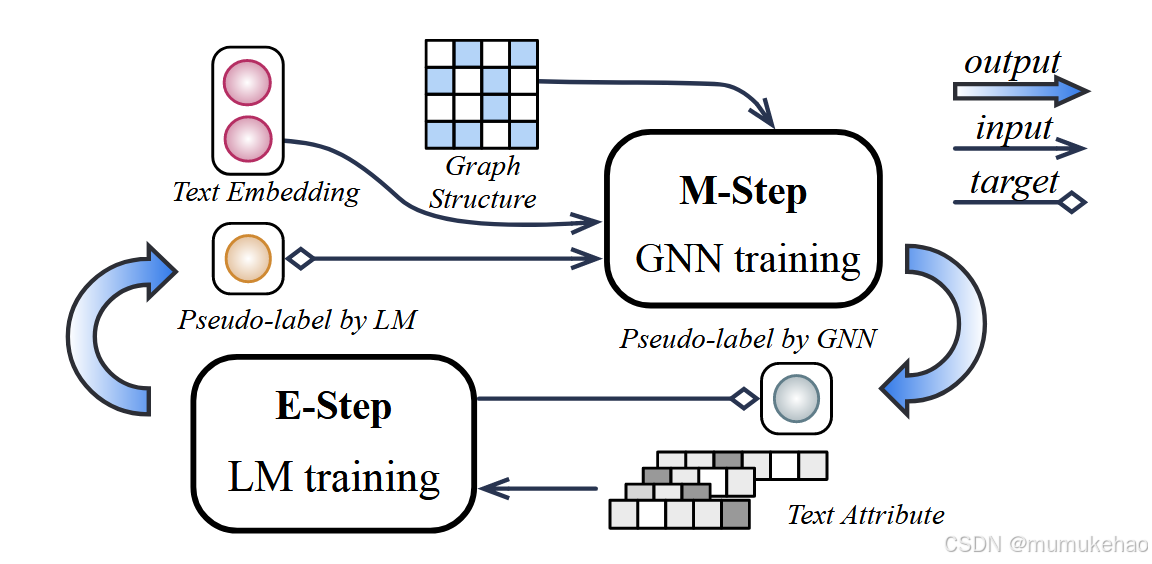
伪似然变分框架
这是一个基于伪似然变分框架的方法,该方法用于模型设计,提供了一种原则性和灵活性的公式化方式。具体来说,这个方法的目标是最大化观测到的节点标签的对数似然函数,即 p ( y L ∣ s V , A ) p(y_L | s_V, A) p(yL∣sV,A),其中 y L y_L yL 是已标记节点的标签集合, s V s_V sV 是所有节点的文本特征, A A A 是图的邻接矩阵。
直接优化这个函数通常是困难的,因为存在未观测到的节点标签 y U y_U yU。为了解决这个问题,该框架不直接优化对数似然函数,而是优化一个称为证据下界(Evidence Lower Bound,ELBO)的量。ELBO 的表达式如下:
l o g p ( y L ∣ s V , A ) ≥ E q ( y U ∣ s U ) [ log p ( y L , y U ∣ s V , A ) − log q ( y U ∣ s U ) ] \\log p(y_L | s_V, A) \geq \mathbb{E}_{q(y_U | s_U)}[\log p(y_L, y_U | s_V, A) - \log q(y_U | s_U)] logp(yL∣sV,A)≥Eq(yU∣sU)[logp(yL,yU∣sV,A)−logq(yU∣sU)]
这里, q ( y U ∣ s U ) q(y_U | s_U) q(yU∣sU)是一个变分分布,上述不等式对任何 q q q都成立。ELBO 可以通过交替优化分布 q q q(即 E-step)和分布 p p p(即 M-step)来优化。
- E-step(期望步) :优化变分分布 q q q,目的是最小化 q q q 和后验分布 p ( y U ∣ s V , A , y L ) p(y_U | s_V, A, y_L) p(yU∣sV,A,yL) 之间的 Kullback-Leibler (KL) 散度,从而收紧上述下界。
- M-step(最大化步) :优化目标分布 ( p ),以最大化伪似然函数:
E q ( y U ∣ s U ) [ log p ( y L , y U ∣ s V , A ) ] ≈ E q ( y U ∣ s U ) [ ∑ n ∈ V log p ( y n ∣ s V , A , y V ∖ n ) ] \mathbb{E}_{q(y_U | s_U)}[\log p(y_{L}, y_{U} | s_{V}, A)] \approx \mathbb{E}_{q(y_U | s_U)}\left[\sum_{n \in V}\log p(y_{n} | s_{V}, A, y_{V \setminus n})\right] Eq(yU∣sU)[logp(yL,yU∣sV,A)]≈Eq(yU∣sU)[∑n∈Vlogp(yn∣sV,A,yV∖n)]
这个过程通过交替执行 E-step 和 M-step 来实现,直到收敛。这种方法允许模型在不需要直接处理未观测标签的情况下,有效地学习节点表示。简而言之,这种方法通过优化一个下界来间接优化对数似然函数,这个下界可以通过交替优化两个分布来逐步提高,从而使得模型能够更好地处理未观测数据,并提高学习效果。
具体的两个模型的介绍
在这部分内容中,文章详细阐述了GLEM方法中使用的两种分布—— q q q 和 p p p的参数化过程,以及它们如何用于节点标签分布的建模和优化。
分布 q q q的参数化
分布
q
q
q的目标是利用文本信息
s
U
s_U
sU 来定义节点标签分布,这相当于一个语言模型(LM)。在 GLEM 中,采用均场形式(mean-field form),假设不同节点的标签是独立的,每个节点的标签只依赖于它自己的文本信息。这导致了以下形式的分解:
q
θ
(
y
U
∣
s
U
)
=
∏
n
∈
U
q
θ
(
y
n
∣
s
n
)
.
q_{\theta}(y_{U}|s_{U}) = \prod_{n \in U}q_{\theta}(y_{n}|s_{n}).
qθ(yU∣sU)=∏n∈Uqθ(yn∣sn).这里,
θ
\theta
θ是模型参数**
U
U
U是未标记节点的集合。在这里,每个项
q
θ
(
y
n
∣
s
n
)
q_{\theta}(y_{n}|s_{n})
qθ(yn∣sn)可以通过基于 Transformer 的语言模型
q
θ
q_{\theta}
qθ来建模,该模型通过注意力机制有效地模拟细粒度的标记交互。**
分布 p p p的参数化
分布 p p p定义了一个条件分布 p ϕ ( y n ∣ s V , A , y V \ n ) p_{\phi}(y_{n}|s_{V}, A, y_{V\backslash n}) pϕ(yn∣sV,A,yV\n),旨在利用节点特征 s V s_{V} sV、图结构 A A A和其他节点标签 y V \ n y_{V\backslash n} yV\n来表征每个节点的标签分布。因此, p ϕ ( y n ∣ s V , A , y V \ n ) p_{\phi}(y_{n}|s_{V}, A, y_{V\backslash n}) pϕ(yn∣sV,A,yV\n)被建模为一个由 ϕ \phi ϕ参数化的 G N N p ϕ GNN p_{\phi} GNNpϕ,以有效地模拟节点间的结构交互。
由于节点文本 s V s_V sV是离散变量,不能直接被 GNN 使用,因此在实践中,我们首先使用 L M q θ LM q_{\theta} LMqθ 对节点文本进行编码,然后使用获得的嵌入作为 G N N p ϕ GNN p_{}\phi GNNpϕ的节点文本的替代。
E-STEP: LM OPTIMIZATION
- 目标:在E-step中,固定GNN,更新LM以最大化证据下界。这样做的目的是将不同节点之间的全局语义相关性提取到LM中。最大化关于 LM 的证据下限等同于最小化后验分布和变分分布之间的 KL 散度
- 优化方法:直接优化KL散度是困难的,因为KL散度依赖于难以处理的变分分布的熵。为了克服这个挑战,作者采用了wake-sleep算法来最小化反向KL散度,从而得到一个更易于处理的目标函数。
- 目标函数:目标函数是关于LM
q
θ
q_\theta
qθ的,目的是最大化这个函数。这个函数的形式是:(KL的前面,第一项相当于GNN,第二项相当于LM)
− K L ( p ϕ ( y U ∣ s V , A , y L ) ∣ ∣ q θ ( y U ∣ s U ) ) = ∑ n ∈ U E p ϕ ( y n ∣ s V , A , y L ) [ log q θ ( y n ∣ s n ) ] + const -KL(p_\phi(y_U|s_V, A, y_L)||q_\theta(y_U|s_U)) = \sum_{n \in U} \mathbb{E}_{p_\phi(y_n|s_V, A, y_L)}[\log q_\theta(y_n|s_n)] + \text{const} −KL(pϕ(yU∣sV,A,yL)∣∣qθ(yU∣sU))=∑n∈UEpϕ(yn∣sV,A,yL)[logqθ(yn∣sn)]+const
这个目标函数更容易处理,因为我们不再需要考虑 q θ ( y U ∣ s U ) q_\theta(y_U|s_U) qθ(yU∣sU)的熵。 - 分布计算:唯一的困难在于计算分布 p ϕ ( y n ∣ s V , A , y L ) p_\phi(y_n|s_V, A, y_L) pϕ(yn∣sV,A,yL)。在原始GNN中,我们基于周围节点标签 y V \ n y_{V\backslash n} yV\n来预测节点 ( n ) 的标签分布。然而,在 p ϕ ( y n ∣ s V , A , y L ) p_\phi(y_n|s_V, A, y_L) pϕ(yn∣sV,A,yL)中,我们只基于观察到的节点标签 y L y_L yL,其他节点的标签是未指定的,因此我们不能直接用GNN计算这个分布。
- 解决方案:为了解决这个问题,作者提出用LM预测的伪标签来标注图中所有未标记的节点,从而可以近似分布:
p ϕ ( y n ∣ s V , A , y L ) ≈ p ϕ ( y n ∣ s V , A , y L , y ^ U \ n ) p_\phi(y_n|s_V, A, y_L) \approx p_\phi(y_n|s_V, A, y_L, \hat{y}_{U\backslash n}) pϕ(yn∣sV,A,yL)≈pϕ(yn∣sV,A,yL,y^U\n)
其中 y ^ U \ n \hat{y}_{U\backslash n} y^U\n是未标记节点的伪标签集合。 - 最终目标函数:结合上述目标函数和标记节点,得到训练LM的最终目标函数:
O ( q ) = α ∑ n ∈ U E p ( y n ∣ s V , A , y L , y ^ U \ n ) [ log q ( y n ∣ s n ) ] + ( 1 − α ) ∑ n ∈ L log q ( y n ∣ s n ) \mathcal{O}(q) = \alpha \sum_{n \in U} \mathbb{E}_{p(y_n|s_V, A, y_L, \hat{y}_{U\backslash n})}[\log q(y_n|s_n)] + (1-\alpha) \sum_{n \in L} \log q(y_n|s_n) O(q)=α∑n∈UEp(yn∣sV,A,yL,y^U\n)[logq(yn∣sn)]+(1−α)∑n∈Llogq(yn∣sn)
其中 α \alpha α是一个超参数。直观上,第二项是一个监督目标,使用给定的标记节点进行训练。同时,第一项可以看作是一个知识蒸馏过程,通过强制LM基于邻域文本信息预测标签分布来训练LM
M-STEP: GNN OPTIMIZATION
目标:在GNN阶段,目标是固定语言模型 q θ q_\theta qθ并优化图神经网络 p ϕ p_\phi pϕ以最大化伪似然(pseudo-likelihood)。
-
方法:
- 使用语言模型为所有节点生成节点表示 h V h_V hV,并将这些表示作为文本特征输入到图神经网络中进行消息传递。
- 利用语言模型 q θ q_\theta qθ为每个未标记节点 n ∈ U n \in U n∈U预测一个伪标签 y ^ n \hat{y}_n y^n并将所有伪标签 { y ^ n } n ∈ U \{\hat{y}_n\}_{n \in U} {y^n}n∈U组合成 y ^ U \hat{y}_U y^U。
-
伪似然重写:结合节点表示和LM q θ q_\theta qθ的伪标签,伪似然可以重写为:
O ( ϕ ) = β ∑ n ∈ U log p ϕ ( y ^ n ∣ s V , A , y L , y ^ U ∖ n ) + ( 1 − β ) ∑ n ∈ L log p ϕ ( y n ∣ s V , A , y L ∖ n , y ^ U ) \mathcal{O}(\phi) = \beta \sum_{n \in U}\log p_{\phi}(\hat{y}_{n} | s_{V}, A, y_{L} , \hat{y}_{U \setminus n}) + (1 - \beta) \sum_{n \in L}\log p_{\phi}(y_{n} | s_{V} , A, y_{L \setminus n}, \hat{y}_{U}) O(ϕ)=β∑n∈Ulogpϕ(y^n∣sV,A,yL,y^U∖n)+(1−β)∑n∈Llogpϕ(yn∣sV,A,yL∖n,y^U)
其中, β \beta β是一个超参数,用于平衡两个项的权重。第一项:可以看作是一个知识蒸馏过程,通过所有伪标签将LM捕获的知识注入到GNN中。第二项:是一个监督损失,使用观察到的节点标签进行模型训练。
一旦训练完成,E-step中的LM(记为GLEM-LM)和M-step中的GNN(记为GLEM-GNN)都可以用来进行节点标签预测。
实验
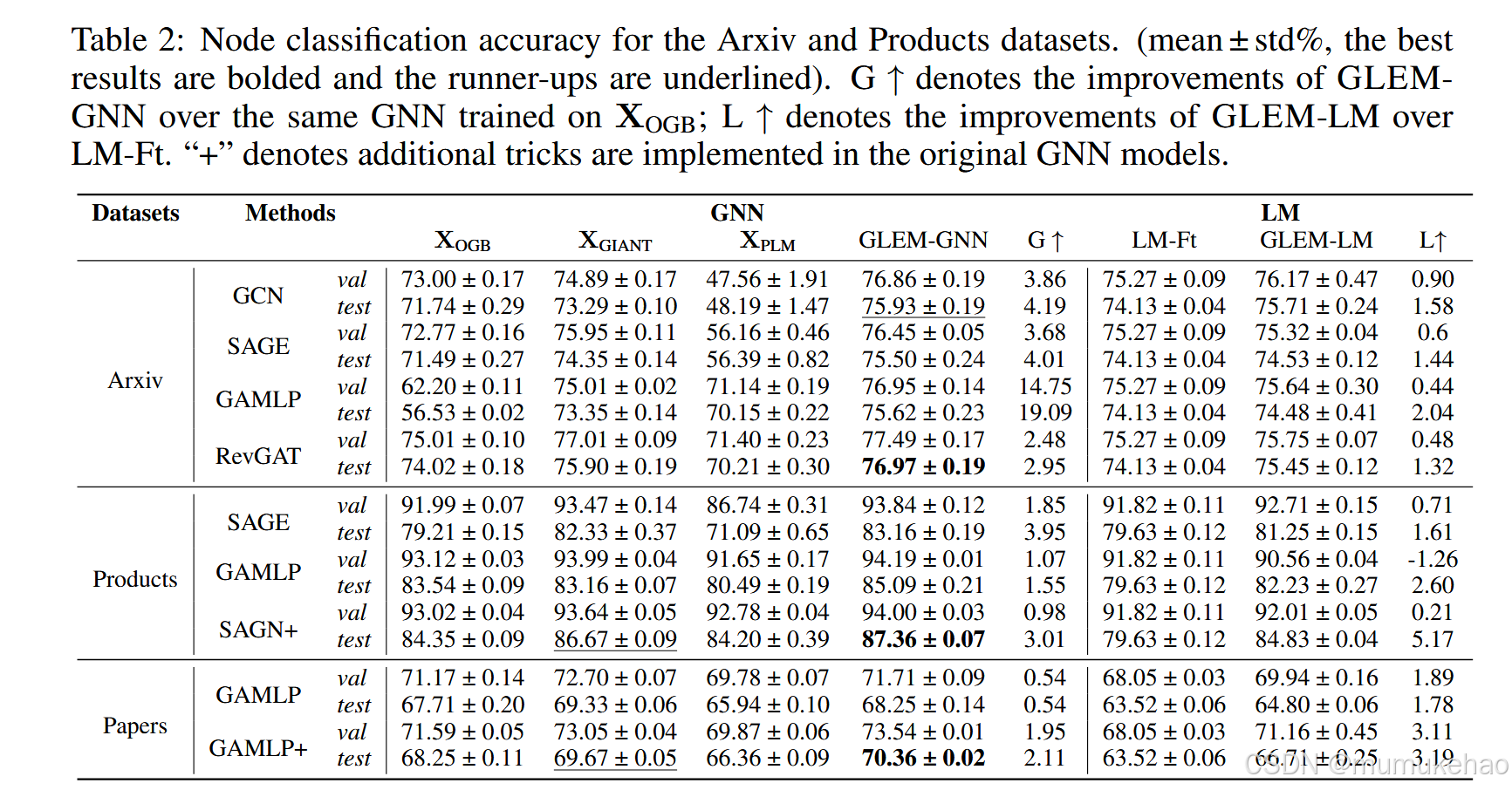
-
结果:
- GLEM-GNN:在所有三个数据集上取得了新的最佳性能,证明了其在节点分类任务中的有效性。
- GLEM-LM:通过结合图结构信息,显著提升了语言模型的性能。
- 可扩展性:GLEM 能够适应大型语言模型(如 DeBERTa-large),并且在效率和性能之间取得了良好的平衡。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









