







论文发表于:AAAI 2024
推荐指数: #paper/⭐⭐⭐
代码:ZichenWen1/AHGFC: The source code for “Homophily-Related: Adaptive Hybrid Graph Filter for Multi-View Graph Clustering” (github.com)
问题引入
问题:当前聚类基于图的同配性假设,只关注了图的同配性,即:较多的关注了低频信息而忽略了高频信息
通过多视图自适应混合图过滤器,使得图的低频和高频数据更具有区分性,从而综合考量设计了图的联合相似度矩阵
模型
重构相似性矩阵
首先,我们利用自编码器将X和A映射为:
Z
x
=
f
x
(
X
;
θ
x
)
,
Z
a
=
f
a
(
A
;
θ
a
)
\mathbf{Z}_x=f_x(\mathbf{X};\theta_x),\quad\mathbf{Z}_a=f_a(\mathbf{A};\theta_a)
Zx=fx(X;θx),Za=fa(A;θa)
由于输入矩阵A可能是同配,异配,或者混合的,我们重构了图联合矩阵通过下面的方式:
Z
=
Z
a
Z
x
T
.
\mathbf{Z}=\mathbf{Z}_a\mathbf{Z}_x^T.
Z=ZaZxT.
在这里,图联合矩阵是节点特征和邻居特征共同组成的.它将更可靠的去取使用初始图.此外,受消息传播机制的驱动,多阶聚合可以平滑图信号,我们聚合矩阵Z来获得图联合矩阵:
S
=
Z
Z
T
\mathbf{S=ZZ^{T}}
S=ZZT
自此,
S
=
(
Z
a
Z
x
T
)
(
Z
a
Z
x
T
)
T
,
\mathbf{S}=(\mathbf{Z}_a\mathbf{Z}_x^T)(\mathbf{Z}_a\mathbf{Z}_x^T)^T,
S=(ZaZxT)(ZaZxT)T,
Z的相似性将得到加强,低频高频信号可以得到有效分离
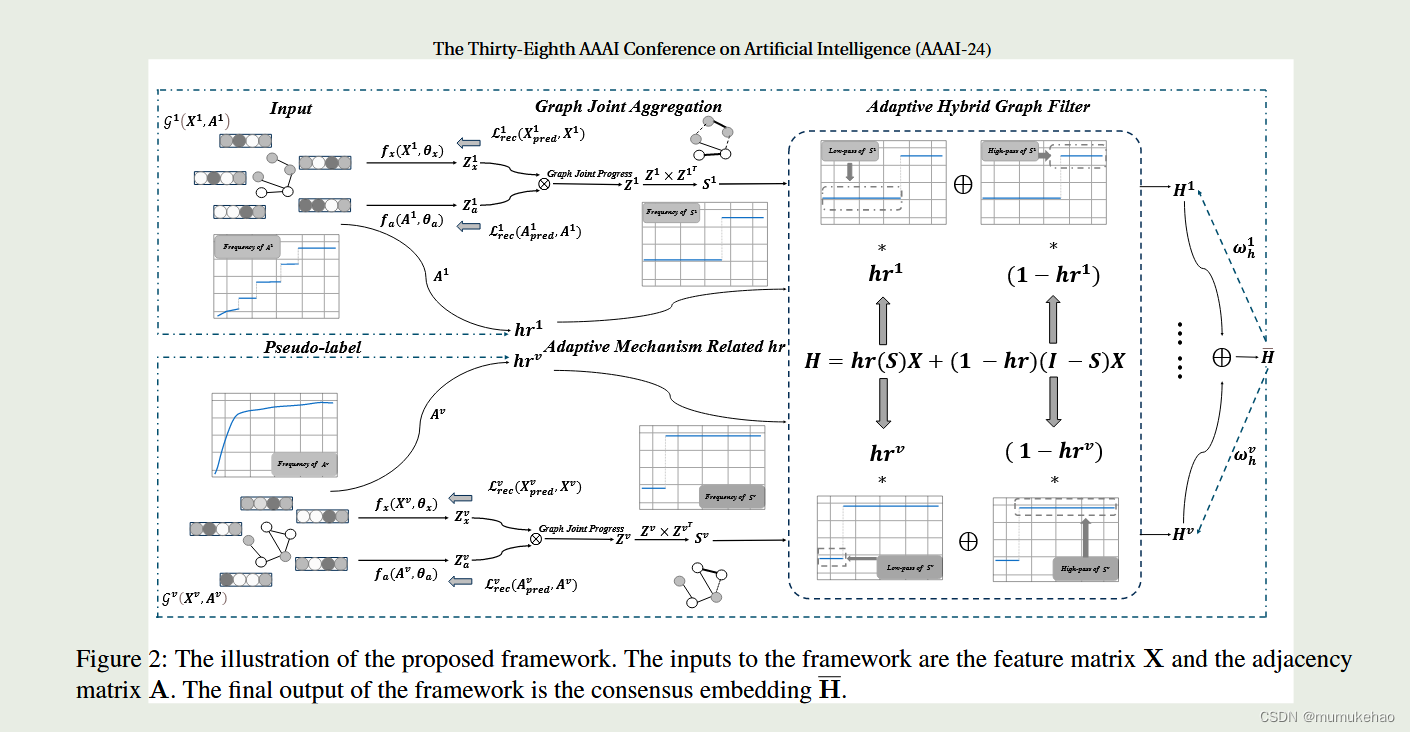
吐槽:这图好丑啊
LP,HP以及自适应hybrid 图过滤
经验上,低通和高通过滤与拉普拉斯矩阵/亲和性矩阵相关,常用的两种:
对称形式:
亲和性矩阵A(邻接矩阵?仿射矩阵?中文到底叫啥)和图拉普拉斯矩阵:
L
P
=
A
s
y
m
X
,
H
P
=
L
s
y
m
X
,
\mathbf{LP=A_{sym}X,}\quad\mathbf{HP=L_{sym}X,}
LP=AsymX,HP=LsymX,
A
s
y
m
=
D
−
1
/
2
A
D
−
1
/
2
,
L
s
y
m
=
I
−
A
s
y
m
\mathbf{A}_{sym}=\mathbf{D}^{-1/2}\mathbf{A}\mathbf{D}^{-1/2},\mathbf{L}_{sym}=\mathbf{I}-\mathbf{A}_{sym}
Asym=D−1/2AD−1/2,Lsym=I−Asym
不对称形式:
另外一种是随机游走形式:
L
P
=
A
r
w
X
,
H
P
=
L
r
w
X
,
\mathbf{LP=A_{rw}X,\quad HP=L_{rw}X,}
LP=ArwX,HP=LrwX,
A
r
w
=
D
−
1
A
,
L
r
w
=
I
−
A
r
w
.
\mathrm{A}_{rw}=\mathrm{D}^{-1}\mathrm{A},\mathrm{L}_{rw}=\mathrm{I}-\mathrm{A}_{rw}.
Arw=D−1A,Lrw=I−Arw.
根据前面介绍的图傅里叶变换,图形信号x和卷积核f的卷积运算如下:
f
∗
x
=
U
(
(
U
T
f
)
⊙
(
U
T
x
)
)
=
U
g
θ
U
T
x
,
f*x=\mathbf{U}((\mathbf{U}^Tf)\odot(\mathbf{U}^Tx))=\mathbf{U}g^\theta\mathbf{U}^Tx,
f∗x=U((UTf)⊙(UTx))=UgθUTx,
其中
⊙
\odot
⊙表示handmard 积,
g
θ
=
U
T
f
g^{\theta}=\mathbf{U}^{T}f
gθ=UTf表示在光谱领域卷积和f
如果我们用随机游走A作为卷积核,那么图信号x可以被过滤:
A
r
w
∗
x
=
U
(
g
L
θ
)
U
T
x
,
L
r
w
∗
x
=
U
(
g
H
θ
)
U
T
x
\mathbf{A}_{rw}*x=\mathbf{U}(g_L^\theta)\mathbf{U}^Tx,\quad\mathbf{L}_{rw}*x\quad=\mathbf{U}(g_H^\theta)\mathbf{U}^Tx
Arw∗x=U(gLθ)UTx,Lrw∗x=U(gHθ)UTx
g
L
θ
g^{\theta}_{L}
gLθ和
g
L
θ
g^{\theta}_{L}
gLθ表示谱领域的A和L.
g
L
θ
=
I
−
Λ
a
n
d
g
H
θ
=
Λ
g_L^\theta=\mathbf{I}-\mathbf{\Lambda}\mathrm{~and~}g_H^\theta=\mathbf{\Lambda}
gLθ=I−Λ and gHθ=Λ
因此,我们可以重写上述式子的结果:
U
(
g
L
θ
)
U
T
x
=
∑
i
(
1
−
λ
i
)
u
i
u
i
T
x
,
U
(
g
H
θ
)
U
T
x
=
∑
i
λ
i
u
i
u
i
T
x
.
\begin{aligned} &\mathbf{U}(g_L^\theta)\mathbf{U}^Tx =\sum_i(1-\lambda_i)u_iu_i^Tx, \\ &\mathbf{U}(g_H^\theta)\mathbf{U}^Tx =\sum_i\lambda_iu_iu_i^Tx. \end{aligned}
U(gLθ)UTx=i∑(1−λi)uiuiTx,U(gHθ)UTx=i∑λiuiuiTx.
高通滤波器,低通滤波器通常用于获得高频和低频信号,当
1
<
λ
<
2
1<\lambda<2
1<λ<2获得高频信号,
0
<
λ
<
1
0<\lambda<1
0<λ<1获得低频信号.
我们为了同时捕获两者,设计了自适应混合图滤波器:
H
h
y
b
r
i
d
=
h
r
⋅
(
S
r
w
)
k
X
+
(
1
−
h
r
)
⋅
(
I
−
S
r
w
)
k
X
,
\mathbf{H_{hybrid}}=hr\cdot(\mathbf{S_{rw}})^k\mathbf{X}+(1-hr)\cdot(\mathbf{I}-\mathbf{S_{rw}})^k\mathbf{X},
Hhybrid=hr⋅(Srw)kX+(1−hr)⋅(I−Srw)kX,
hr表示可学习参数来衡量同配性,用于控制混合滤波器的自适应过程
用同配比来调节
当同配信息占据主导地位时,低通滤波器发挥作用.当异配性占主要作用时,高通滤波器占主要作用.我们选择用伪标签和邻接信息来计算同配比(hr):
h
r
=
S
U
M
(
A
v
⊙
P
P
T
−
I
)
S
U
M
(
A
v
−
I
)
hr=\frac{\mathrm{SUM}(\mathbf{A}^v\odot\mathbf{PP}^T-\mathbf{I})}{\mathrm{SUM}(\mathbf{A}^v-\mathbf{I})}
hr=SUM(Av−I)SUM(Av⊙PPT−I)
⊙
\odot
⊙是hadamard product,
P
∈
{
0
,
1
}
n
×
c
\mathbf{P} \in \{0,1\}^{n\times c}
P∈{0,1}n×c是伪标签的one-hot编码.hr还可以响应图上相似度和不想死的信息的比例.其计算开销小.
H
‾
=
∑
v
=
1
V
ω
h
v
H
v
,
where
ω
h
v
=
(
e
v
a
v
max
(
e
v
a
1
,
e
v
a
2
,
⋯
,
e
v
a
V
)
)
ρ
,
\begin{aligned} \overline{\mathbf{H}}=& \sum_{v=1}^V\omega_h^v\mathbf{H}^v,\text{where} \\ &\omega_h^v=(\frac{eva^v}{\max{(eva^1,eva^2,\cdots,eva^V)}})^\rho, \end{aligned}
H=v=1∑VωhvHv,whereωhv=(max(eva1,eva2,⋯,evaV)evav)ρ,
其中,eva是共识特征
H
ˉ
\bar{\mathbf{H}}
Hˉ和H的评估.超参
ρ
\rho
ρ调整整个视图权重的光滑程度.对于每个共识结果,我们应用k-means来运算最终结果,并运用kl散度来优化聚类结果
损失函数
L
R
e
c
=
l
(
f
x
(
X
;
θ
x
)
;
X
)
+
l
(
f
a
(
A
;
θ
a
)
;
A
)
,
\mathcal{L}_{Rec}=l(f_x(\mathbf{X};\theta_x);\mathbf{X})+l(f_a(\mathbf{A};\theta_a);\mathbf{A}),
LRec=l(fx(X;θx);X)+l(fa(A;θa);A),
L
K
L
=
∑
v
=
1
V
K
L
(
P
‾
∥
Q
v
)
+
∑
v
=
1
V
K
L
(
P
v
∥
Q
v
)
+
K
L
(
P
‾
∥
Q
‾
)
,
\mathcal{L}_{KL}=\sum_{v=1}^VKL(\mathbf{\overline{P}}\|\mathbf{Q}^v)+\sum_{v=1}^VKL(\mathbf{P}^v\|\mathbf{Q}^v)+KL(\mathbf{\overline{P}}\|\mathbf{\overline{Q}}),
LKL=v=1∑VKL(P∥Qv)+v=1∑VKL(Pv∥Qv)+KL(P∥Q),
最终,损失函数被设计为:
L
=
γ
r
e
c
L
R
e
c
+
γ
k
l
L
K
L
,
\mathcal{L}=\gamma_{rec}\mathcal{L}_{Rec}+\gamma_{kl}\mathcal{L}_{KL},
L=γrecLRec+γklLKL,
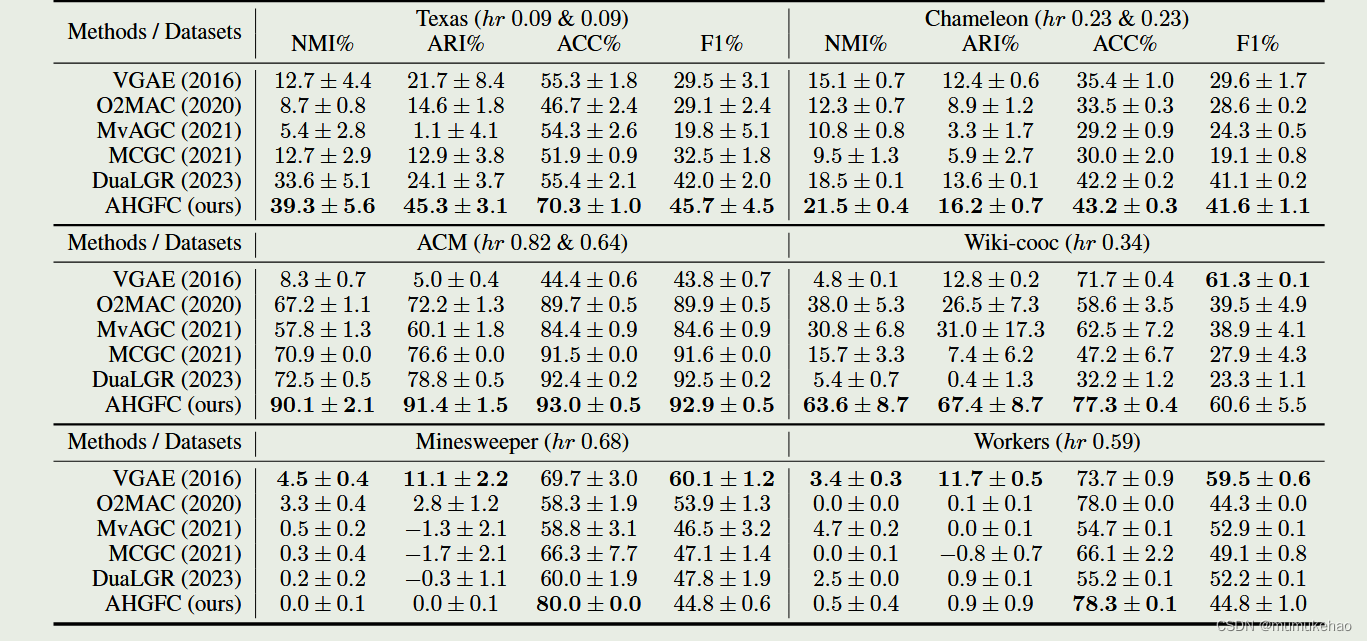
结果:
总结:
优点:这篇用了相似性矩阵和特征相似度生成的相似性矩阵,以及聚类伪标签来设计同配比,利用视图特征和共识特征的权重比去聚合不同阶信息的特征,思路很直观,挺有意思的.(创新点:同配比,视图特征和共识特征的权重比聚合特征)
缺点:写的有点好,结果让人难以相信.在权重参数的确定时引入超参,对其适用性是否有一丢丢怀疑















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









