










代码: https://github.com/xh-liu/HydraPlus-Net
原文:https://arxiv.org/abs/1709.09930
HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis,来自SenseTime的论文,提出了一个基于注意力机制的深度网络HydraPlus-Net,将多层注意力图 多向映射到不同的特征层。
由HP-Net得到的注意力深度特征具有几个优点:
(1)模型能够从浅层到语义层捕获注意力;
(2)挖掘多尺度的注意力特征,充实最终的行人特征表示,丰富了行人图像的最终特征表示。
(3)提取出细节和局部特征来充实高层全局特征,这些特征在细粒度的行人分析任务中是非常重要的;
(4)提出多方向注意机制模块(multi-directional attention,MDA),提取多层(multiple level)特征,包含局部和全局特征,进行多层特征融合,进行细粒度的行人分析;
引言
行人识别,行人属性识别,重点关注能够补充全局深层特征的细节和局部特征,如下图所示,在(a)中,局部的语义特征用来分辨具有相似外观的行人,如长发及短发,长袖和短袖。在(b)中,浅层特征可以捕获衣服条纹。在(c-d)中多尺度信息描述行人的特点,(c)对应小尺度描述”打电话”,(d)对应大尺度全局理解描述“性别”属性。

目前的主流方法仅仅捕获全局特征,局部响应的语义特征很难获取到。论文提出的方法提取多层特征,进行多层行人属性理解和行人认证,即HP-Net,改方法提出多方向注意机制模块(MDA)集合注意区域内多层特征。作者搜集了一个行人属性样本集PA-100K。
本文贡献:
(1)提出了一种基于多方向注意力融合模块的HydraPlus-Net,为行人分析的细粒度任务训练多层次、多尺度的注意力增强特征。
(2)综合评价HP-net对行人属性识别和人的再识别的作用。当前最好效果。
(3)PA-100K数据集。收集场景最多样化、样本和实例数量最多的新的大型行人属性数据集(PA- 100K),比以前的数据集提供了更多的信息,有助于完成各种行人分析任务。
相关研究
行人属性分析:提出联合训练多属性 可以提升属性识别的性能。也有方法使用姿态或身体不可见信息进行属性分析。
HydraPlus-Net结构
HP-net的设计是基于从多个层次提取多尺度特征的需要,不仅捕获局部和全局信息,而且根据不同层的语义集合特征。
HP-net包含两部分,M-Net和AF-Net。
主网络是一个CNN结构,注意力特征网络AF-Net 包含MDA模块的多分支,应用到不同语义特征层上。除了MDA模块,AF-Net与M-Net共享卷积框架。它们的输出concat,使用全局池化和FC层融合。最终的输出映射到属性logits用于属性识别,或者特征向量用于重识别。论文使用的是inception_v2结构,网络结构如下图所示:

(1)注意力网络 AF-net
AF-Net包含三个子网络分支,并使用MDA模块增强,即F(αi),其中αi是由inception块输出特征生成的注意力图,图中使用黑实线标记。随后应用到kth块的输出,图中用虚红线标示。每个MDA模块,有一条注意力生成链接,三条注意力特征构造链接。不同的MDA模块,注意力图由不同的inception模块生成,之后乘到不同层的特征图,生成多层次的注意力特征。 其中AF-Net初始化采用backbone。MDA模块的一个示例如下图所示:
通过MDA模块融合多层次的注意特性,我们就可以使输出特性跨不同的语义级别收集信息,从而提供更有选择性的表示。
传统基于注意力的模型,将注意力图返回输入到原相同的模块(红线),通过应用注意力图到相邻的模块来扩展此机制;HP-Net应用不同的注意力图到相邻的多个模块(下图b不同颜色表示),在相同的空间分布下融合多层特征。将单个注意图应用于多个块,自然会让融合的特征在相同的空间分布中编码多层信息。

由不同的块学习到的注意力图尺寸和细节不同,如例,高层块的注意力图较粗糙,通常表示出语义区域,图4(a)中的图3突出了手提包,低层的块学习到的特征对应局部特征模式,如边缘和文理等细节,如下图(a)所示:

将一个注意力图应用到多个块,使融合的特征编码具有相同空间分布的多层信息。对于一个inception块i,特征图为Fi,注意力图αi由带有BN的的1×1卷积层和ReLU激活得到: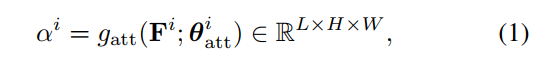
其中L代表注意力图的通道。与inception k的输出特征图相乘,得到的注意力特征图为: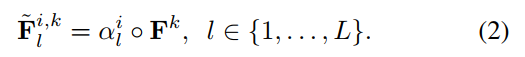
注意力特征图经过后续的块,在MDA模块最后,concat L个注意力特征图作为最终的特征表示。示例如图3所示。
由图(4)的b-c观察,注意模型有多个通道,可以关注不同的注意区域,与一个注意力通道相比,注意力通道的多样性充实了特征标识。注意力的一致性,由(b)-(c)可以看出,不同的人注意力对应通道关注的信息相似。高层特征与低层特征提取信息的区别:

(2)HP-Net 训练
我们以分阶段的方式训练HP-net。
(1)训练M-Net,提取基本特征;
(2)将M-Net复制三次,得到AF-Net的三个分支,每个MDA模块有三个子分支组成,即临近的三个不同的inception blocks,依次微调每个blocks,即共有9个blocks需要微调;
(3)微调完成后,固定AF-Net和M-Net,训练全局平均池化层(GAP)和全连接层(FC);
(4)输出层:属性识别使用交叉熵损失函数,行人ReID使用softmax函数。
输出层定义不同任务的最小损失,其中交叉熵损失Latt用于行人属性识别,softmax损失用于人员重新识别。
行人属性实验结果
作者在文中还提出注意力的多样性和一致性,如图4b所示,两个相机的图像,得益于多个注意通道从一个层面上的识别定位能力,可以针对不同的注意区域分别捕获整个特征,丰富了特征表征。
如图4b-c所示,在不同的输入样本上生成的一个注意图可能在空间域上分布相似,因为它们突出了行人相同的语义部分,头是头,屁股是屁股。


















 3244
3244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









