







若该文为原创文章,转载请注明原文出处。
分享一个行人属性分析系统,识别行人,并标记每个人的属性。
项目代码来自公众号渡码的项目。
本人用Win10复现完整项目,并记录过程。
源码会上传到github,可以自行下载测试。
Yinyifeng18/AI_pedestrain_attributes: 行人属性识别 (github.com)
一、介绍
实现行人属性分析系统需要 3 个步骤:
-
用 YOlOv5 识别行人
-
用 ByteTrack 跟踪标记同一个人
-
训练多标签图像分类网络,识别行人 26 个属性

二、环境安装
使用环境是win10下CPU版本
1、安装Anaconda
下载地址:Miniconda — Anaconda documentation
下载安装即可。
2、创建虚拟机
conda create -n pedestrain_env python=3.83、激活
conda activate pedestrain_env三、安装轮子
pip install loguru -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lapx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install thop -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy==1.23.5 -i https://pypi.tuna.tsinghua.edu.cn/simple 安装cython_bbox,win下无法直接安装
先安装cython
pip install cython -i https://pypi.tuna.tsinghua.edu.cn/simple 下载cython_bbox-0.1.3
https://pypi.org/project/cython-bbox/0.1.3/#files修改里面的setup.py文件
extra_compile_args = [-Wno-cpp]为extra_compile_args = {'gcc': ['/Qstd=c99']}安装
python setup.py build_ext install安装时如果出Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools"的错误处理方法安装VS C++
四、安装paddlepadddle
电脑无GPU,安装的是CPU版本
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple五、安装paddleclas
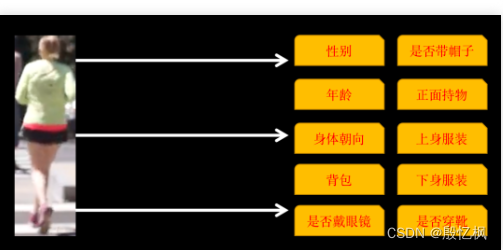
paddleclas识别的属性包括以下 10 类
1、安装
pip install paddleclas -i https://mirror.baidu.com/pypi/simple2、测试
测试数据下载:
https://paddleclas.bj.bcebos.com/data/PULC/pulc_demo_imgs.zip
下载后解压到当前目录
测试有两种方法:
1)、使用命令行快速预测
paddleclas --model_name=person_attribute --infer_imgs=./pulc_demo_imgs/person_attribute/090004.jpg
2)、python测试
创建paddleclas_demo.py文件,内容如下:
import paddleclas
model = paddleclas.PaddleClas(model_name="person_attribute")
result = model.predict(input_data="pulc_demo_imgs/person_attribute/090004.jpg")
print(next(result))运行测试
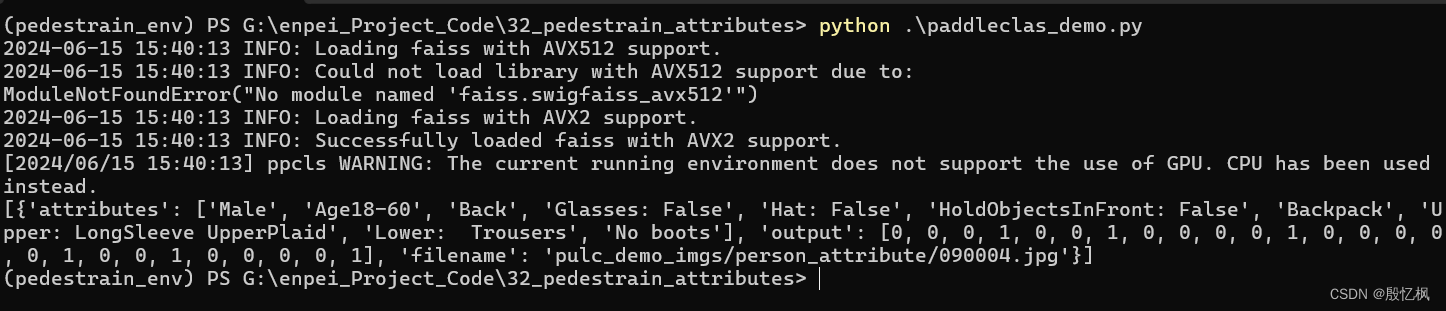
测试结果相同。
这里只测试不做训练,如果想训练,参考文章PaddleClas/docs/zh_CN/models/PULC/PULC_person_attribute.md at release/2.5 · PaddlePaddle/PaddleClas (github.com)
六、安装yolov5
1、下载yolov5
git clone https://github.com/ultralytics/yolov52、安装
cd yolov5
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple 3、测试
创建yolov5_demo.py文件,内容如下:
import torch
# Model
model = torch.hub.load('yolov5',
'custom',
path='./yolov5/weights/yolov5s.pt',
source='local')# or yolov5n - yolov5x6, custom
# Images
img = "./zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.需要先下载yolov5s.pt文件。
测试结果

七、下载ByteTrack
git clone https://github.com/ifzhang/ByteTrack.git到此文件准备完成
八、代码分析测试
代码只有三个,全部附上
track.py
# track.py
from dataclasses import dataclass
import numpy as np
import cv2
import paddleclas
from pedestrain_attr_dict import *
import sys
sys.path.append('./ByteTrack/')
from yolox.tracker.byte_tracker import BYTETracker, STrack
@dataclass(frozen=True)
class BYTETrackerArgs:
track_thresh: float = 0.25
track_buffer: int = 30
match_thresh: float = 0.8
aspect_ratio_thresh: float = 3.0
min_box_area: float = 1.0
mot20: bool = False
class Detection(object):
def __init__(self, ltrb, track_id, person_attr):
self.track_id = track_id
self.ltrb = None
self.sex = ''
self.age = ''
self.front = '未知'
self.has_glasses = '否'
self.has_hat = '否'
self.bag = '未知'
self.upper = ''
self.lower = ''
self.boots = '否'
self.update(ltrb, person_attr)
def update(self, ltrb, attr):
self.ltrb = ltrb
if attr is not None:
self.sex = '女' if attr[0] == 'Female' else '男'
self.age = age_dict[attr[1]]
self.front = direct_list[attr[2]]
self.has_glasses = '是' if attr[3] == 'Glasses: True' else '否'
self.has_hat = '是' if attr[4] == 'Hat: True' else '否'
self.bag = bag_dict[attr[6]]
# 上半身
self.upper = ' '.join([upper_dict[up] for up in attr[7].replace('Upper: ', '').split(' ')])
# 下半身
self.lower = ' '.join([lower_dict[lo] for lo in attr[8].replace('Lower: ', '').split(' ')])
self.boots = '是' if attr[9] == 'Boots' else '否'
class PedestrainTrack(object):
def __init__(self):
self.byte_tracker = BYTETracker(BYTETrackerArgs())
self.detection_dict = {}
# 行人属性模型
self.pedestrain_attr_model = paddleclas.PaddleClas(model_name="person_attribute")
def update_track(self, boxes, frame):
tracks = self.byte_tracker.update(
output_results=boxes,
img_info=frame.shape,
img_size=frame.shape
)
new_detection_dict = {}
for track in tracks:
l, t, r, b = track.tlbr.astype(np.int32)
track_id = track.track_id
# 调用行人检测模型,识别行人属性
track_box = frame[t:b, l:r]
# print(track_box.shape)
# cv2.imwrite('a.jpg', track_box)
person_attr_res = self.pedestrain_attr_model.predict(track_box)
attr = None
try:
for i in person_attr_res:
attr = i[0]['attributes']
except:
pass
if track_id in self.detection_dict:
detection = self.detection_dict[track_id]
detection.update((l, t, r, b), attr)
else:
detection = Detection((l, t, r, b), track_id, attr)
new_detection_dict[track_id] = detection
self.detection_dict = new_detection_dict
return self.detection_dict
pedestrain_attr_dict.py
gender_dict = {
'Female': '女',
'Male': '男',
}
age_dict = {
'AgeLess18': '小于18岁',
'Age18-60': '18-60岁',
'AgeOver60': '大于60岁'
}
# 朝向
direct_list = {
'Front': '正面',
'Side': '侧面',
'Back': '背面'
}
# 背包
bag_dict = {
'HandBag': '手提包',
'ShoulderBag': '单肩包',
'Backpack': '双肩包',
'No bag': '未背包'
}
# 上衣风格
upper_dict = {
'LongSleeve': '长袖',
'ShortSleeve': '短袖',
'UpperStride': '带条纹',
'UpperLogo': '带logo',
'UpperPlaid': '带格子',
'UpperSplice': '拼接风格'
}
# 下身风格
lower_dict = {
'LowerStripe': '带条纹',
'LowerPattern': '带图案',
'LongCoat': '长外套',
'Trousers': '长裤',
'Shorts': '短裤',
'Skirt&Dress': '短裙&裙子'
}
pedestrain_attributes.py
import cv2
import torch
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from track import PedestrainTrack
def cv2_add_chinese_text(img, text, position, text_color=(0, 255, 0), text_size=30):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 创建一个可以在给定图像上绘图的对象
draw = ImageDraw.Draw(img)
# 字体的格式
fontStyle = ImageFont.truetype("./fonts/simsun.ttc", text_size, encoding="utf-8")
# 绘制文本
draw.text(position, text, text_color, font=fontStyle)
# 转换回OpenCV格式
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
class PedestrainAttrDetection(object):
def __init__(self):
self.yolo_model = torch.hub.load('yolov5',
'custom',
path='./yolov5/weights/yolov5s.pt',
source='local')
self.yolo_model.conf = 0.6
self.tracker = PedestrainTrack()
def plot_detection(self, person_track_dict, frame):
for track_id, detection in person_track_dict.items():
l, t, r, b = detection.ltrb
track_id = detection.track_id
cv2.rectangle(frame, (l, t), (r, b), (0, 255, 0), 1)
cv2.putText(frame, f'id-{track_id}', (l + 2, t - 3), cv2.FONT_HERSHEY_PLAIN, 1, (0, 0, 255), 1)
top_margin = 20
font_size = 14
font_color = (255, 0, 255)
frame = cv2_add_chinese_text(frame, f'性别:{detection.sex}', (l+2, t+top_margin), font_color, font_size)
frame = cv2_add_chinese_text(frame, f'年龄:{detection.age}', (l+2, t+top_margin*2), font_color, font_size)
frame = cv2_add_chinese_text(frame, f'朝向:{detection.front}', (l+2, t+top_margin*3), font_color, font_size)
frame = cv2_add_chinese_text(frame, f'戴眼镜:{detection.has_glasses}', (l+2, t+top_margin*4), font_color, font_size)
frame = cv2_add_chinese_text(frame, f'戴帽子:{detection.has_hat}', (l+2, t+top_margin*5), font_color, font_size)
frame = cv2_add_chinese_text(frame, f'背包:{detection.bag}', (l+2, t+top_margin*6), font_color, font_size)
frame = cv2_add_chinese_text(frame, f'上半身:{detection.upper}', (l+2, t+top_margin*7), font_color, font_size)
frame = cv2_add_chinese_text(frame, f'下半身:{detection.lower}', (l+2, t+top_margin*8), font_color, font_size)
frame = cv2_add_chinese_text(frame, f'穿靴:{detection.boots}', (l+2, t+top_margin*9), font_color, font_size)
# cv2.putText(frame, f'sex-{sex}', (l + 2, t + 10), cv2.FONT_HERSHEY_PLAIN, 1, (0, 0, 255), 1)
return frame
@staticmethod
def yolo_pd_to_numpy(yolo_pd):
box_list = yolo_pd.to_numpy()
detections = []
for box in box_list:
l, t = int(box[0]), int(box[1])
r, b = int(box[2]), int(box[3])
conf = box[4]
detections.append([l, t, r, b, conf])
return np.array(detections, dtype=float)
def detect(self, video_file):
cap = cv2.VideoCapture(video_file)
video_w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
video_h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = round(cap.get(cv2.CAP_PROP_FPS))
print(fps)
# video_writer = cv2.VideoWriter('./video_p2.mp4', cv2.VideoWriter_fourcc(*'H264'), fps, (video_w, video_h))
while True:
ret, frame = cap.read()
if not ret or frame is None:
break
yolo_det_results = self.yolo_model(frame[:, :, ::-1])
pd = yolo_det_results.pandas().xyxy[0]
person_pd = pd[pd['name'] == 'person']
person_det_boxes = self.yolo_pd_to_numpy(person_pd)
person_track_dict = self.tracker.update_track(person_det_boxes, frame)
frame = self.plot_detection(person_track_dict, frame)
cv2.imshow('pedestrain attributes detect', frame)
# video_writer.write(frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
return
if __name__ == '__main__':
PedestrainAttrDetection().detect('./video.mp4')代码不多,比较容易看懂
九、总结
测试过程中由于使用的是CPU安装cython_bbox花了一点时间.环境搭建还是蛮麻烦的。
如有侵权,或需要完整代码,请及时联系博主。


















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











