







1.LeNet-5的基本结构
输入 → 卷积 → 池化 → 卷积 → 池化 → 卷积(全连接) → 全连接 → 输出。
包括7层网络结构(不含输入层)

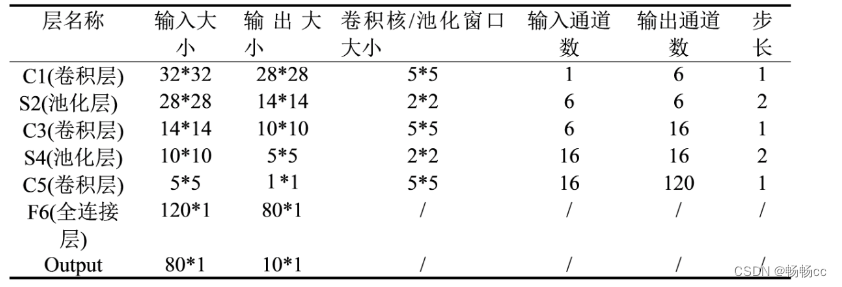
1、输入层(Input layer)
接收32*32的手写数字图像,包括灰度值(0-255),在实际应用中,我们通常会对输入图像进行预处理,例如对像素值进行归一化,以加快训练速度和提高模型的准确性,
2、卷积层C1(Convolutional layer C1)
包括6个卷积核,每个卷积核的大小为5*5,步长为1,填充为0,输出上使用sigmoid激活函数,
每个卷积核产生一个大小为28*28的特征图,(输出通道数为6)
3、采样层S2(Subsampling layer S2)
采用最大池化(max-pooling)操作,每个窗口的大小为2*2,步长为2,产生一个14*14的特征图,(输出通道数为6)。
这样可以减少特征图的大小,提高计算效率,并且对于轻微的位置变化可以保持一定的不变性
4、卷积层C3(Convolutional layer C3)
包括16个卷积核,每个卷积核的大小为5*5,步长为1,填充为0。输出上使用sigmoid激活函数,
每个卷积核会产生一个大小为10*10的特征图(输出通道数为16)
5、采样层S4(Subsampling layer S4)
采用最大池化(max-pooling)操作,每个窗口的大小为2*2,步长为2,产生一个5*5的特征图,(输出通道数为16)
6、全连接层C5(Fully connected layer C5)
将每个5*5的特征图(共16个)成一个长度为400的向量,并通过一个带有120个神经元的全连接层进行连接。
120是由LeNet-5的设计者根据实验得到的最佳值
7、全连接层F6(Fully connected layer F6)
将120个神经元连接到84个神经元上
8、输出层(Output layer)
由10个神经元组成,每个神经元对应0-9中的一个数字,并输出最终的分类结果
2.特征图大小的计算


3.代码实现
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
'''定义LeNet-5模型'''
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1)
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(in_features=16 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=84)
self.fc3 = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.pool1(torch.relu(self.conv1(x)))
# 1.通过卷积层self.conv1进行卷积操作
# 2.使用ReLU激活函数torch.relu对结果进行非线性变换
# 3.通过池化层self.pool1对得到的特征图进行下采样
x = self.pool2(torch.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
# 调用x.view(-1, 16 * 4 * 4)将特征张量展平成一维向量,以便输入全连接层self.fc1进行处理
x = torch.relu(self.fc1(x)) #使用ReLU激活函数对fc1的输出进行非线性变换
x = torch.relu(self.fc2(x)) #使用ReLU激活函数对fc2的输出进行非线性变换
x = self.fc3(x) #通过全连接层self.fc3获得最终的输出结果
return x
net = LeNet5()
print(net)
import torchvision.transforms as transforms
'''加载MNIST数据集'''
# transform = torchvision.transforms.ToTensor() #定义数据预处理方式:转换 PIL.Image 成 torch.FloatTensor
train_dataset = datasets.MNIST(root='./data', #数据目录,
train=True, #是否为训练集
transform=transforms.ToTensor(), #加载数据预处理
download=True) #是否下载
test_dataset = datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor(),
download=False)
# 定义数据加载器
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
'''观察部分MNIST数据集'''
import numpy as np
import matplotlib.pyplot as plt
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# torchvision.utils.make_grid 将图片进行拼接
imshow(torchvision.utils.make_grid(iter(train_loader).next()[0]))

'''定义模型、损失函数和优化器'''
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') #设置GPU运行
net = LeNet5().to(device) #实例化网络,有GPU则将网络放入GPU加速
loss = nn.CrossEntropyLoss() #多分类问题,选择交叉熵损失函数
optimizer = optim.SGD(net.parameters(),lr = 0.001,momentum = 0.9) #选择SGD,学习率取0.001
'''训练模型'''
num_epochs = 10
for epoch in range(num_epochs):
sum_loss = 0
for i, (images, labels) in enumerate(train_loader):
images,labels = images.to(device), labels.to(device) #有GPU则将数据置入GPU加速
'''梯度清零'''
optimizer.zero_grad()
'''传递损失 + 更新参数'''
outputs =net(images)
l = loss(outputs, labels)
l.backward()
optimizer.step()
'''每训练100个batch打印一次平均loss'''
sum_loss += l.item()
if (i) % 100 == 99:
# print('[Epoch:%d, batch:%d] train loss: %.03f' % (epoch + 1, i + 1, sum_loss / 100))
sum_loss = 0.0
'''测试模型'''
net.eval()
with torch.no_grad():
correct = 0
total = 0
for data in test_loader:
test_inputs, labels = data
test_inputs, labels = test_inputs.to(device), labels.to(device)
outputs_test = net(test_inputs)
_, predicted = torch.max(outputs_test.data, 1) #输出得分最高的类
total += labels.size(0) #统计50个batch 图片的总个数
correct += (predicted == labels).sum() #统计50个batch 正确分类的个数
print('第{}个epoch的识别准确率为:{}%'.format (epoch + 1, 100*correct.item()/total))
#模型保存
torch.save(net, './model/LeNet5.bin')
#模型加载
# net2 = torch.load('./model/LeNet5.bin')
# print(net2) 















 4728
4728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









