






A while ago I found the slide at the right, claiming that AMD did not have any direct GPU-GPU communication. I found at several sources there was, but it seems not to be a well-known feature. The feature is known as SDI (mostly on network-cards, SSDs and FPGAs), but not much information is found on PCI+SDI. More often RDMA is used: Remote Direct Memory Access (wikipedia).
Questions I try to answer:
- Which server-grade GPUs support direct GPU-GPU communication when using OpenCL?
- What are other characteristics interesting for OpenCL-devs besides direct communication GPU-GPU, GPU-FPGA, GPU-NIC?
- How do you code such fast communication?
Enjoy reading!
A note about OpenCL contexts
You might know of clEnqueueMigrateMemObjects(), which is close to what RDMA is doing. It’s defined by “Enqueues a command to indicate which device a set of memory objects should be associated with”. The big difference is that clEnqueueMigrateMemObjects operates within an OpenCL context only, and RDMA works between different contexts.
NVidia GPUDirect on Tesla and Quadro
 We can be short: NVidia doesn’t have support of GPUDirect under OpenCL. If you need it, file a bug-report and tell how big customer you are – you might get access to some special program.
We can be short: NVidia doesn’t have support of GPUDirect under OpenCL. If you need it, file a bug-report and tell how big customer you are – you might get access to some special program.
I’d like to discuss theirs first, as it’s better known than AMD’s solution. From NVidia’sGPUDirect page, one can conclude that their solution consists of three categories:
1) GPU-GPU communications:
- Peer-to-Peer Transfers between GPUs: copy between memories of different GPUs.
- Peer-to-Peer memory access: access other GPU’s memory.
2) GPU-PCIcard communications:
- Network cards.
- SSDs.
- FPGAs.
- Video-input: frame grabbers, video switchers, HD-SDI capture, and CameraLink devices.
3) GPU-PCI-network-PCI-GPU communications. This includes Infiniband, if the network-driver supports it.
As multi-GPU is a typical professional feature (like double precision compute), all this only works on Tesla and Quadro cards.
Intel OFED on XeonPhi
Intel thinks that OpenMP and MPI are the only working solutions, and doesn’t promote OpenCL on XeonPhi anymore. If you need more information on Intel’s alternative to GPUDirect and DirectGMA, check Intra-node and inter-node MPI using OFED.
AMD DirectGMA/SDI-Link on FirePro
Albeit existing since 2011, not many know of its existence. You might have seen their demo’s of video-software, where camera-input is directly feeded into the GPU. Or if you already use recent FirePro GPUs on a cluster.
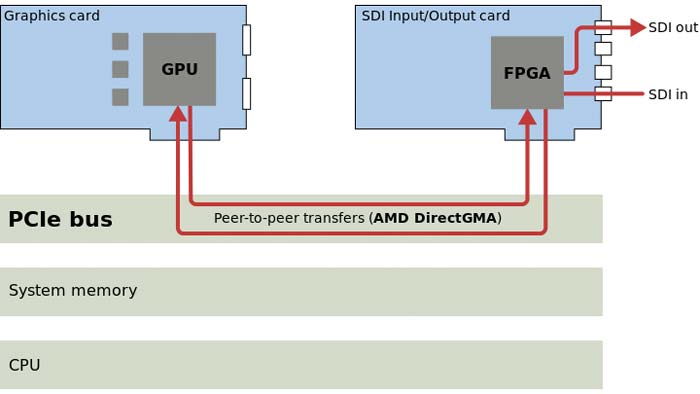
AMD has support for the two first categories (GPU-GPU and GPU-PCI) on FirePro GPUs. I heard that RDMA-support is coming in Q2/Q3. GPU-GPU communication is called DirectGMA and GPU-PCIcard can be found under SDILink. Often these two names are mixed.
Support is on FirePro S-series (S7xx0, S9xx0, S10xx0) and W-series (W5xx0, W7xx0, W8xx0 and W9xx0).
Programming for DirectGMA
First step is to check if extension “cl_amd_bus_addressable_memory” is available. This function enables:
- clEnqueueMakeBuffersResidentAMD(): prepares a buffer object to be used from another device.
- clEnqueueWriteSignalAMD(): gives a signal with a given ID to the GPU that has the buffer object that writing has been finished. This function differs from clCreateUserEvent(), that it works cross contexts.
- clEnqueueWaitSignalAMD(): waits for signal from other devices with a given ID – is blocking. This is the cross-context version ofclWaitForEvents().
You also need standard available functions:
- clCreateBuffer(): Creates a buffer object.
- clEnqueueMigrateMemObjects(): Enqueues a command to indicate which device a set of memory objects should be associated with. Is enqueued to
- clEnqueueCopyBuffer(): Enqueues a command to copy from one buffer object to another.
Extra flags:
- CL_MEM_BUS_ADDRESSABLE_AMD: buffer objects that need to be made resident, need to be created with this flag. CL_MEM_BUS_ADDRESSABLE_AMD, CL_MEM_ALLOC_HOST_PTR and CL_MEM_USE_HOST_PTR are mutually exclusive.
- CL_MEM_EXTERNAL_PHYSICAL_AMD: creates an object pointing to a buffer object on another device, which was created with CL_MEM_BUS_ADDRESSABLE_AMD. CL_MEM_EXTERNAL_PHYSICAL_AMD, CL_MEM_ALLOC_HOST_PTR, CL_MEM_COPY_HOST_PTR and CL_MEM_USE_HOST_PTR are mutually exclusive.
The struct:
typedef struct _cl_bus_address_amd {
cl_long surface_bus_address;
cl_long marker_bus_address
} cl_bus_address_amd;
You’ll find this struct in the ‘ cl_ext.h ‘ from the AMD APP SDK .
Limitations of DirectGMA: there is no support for map/unmap and image objects.
The actual steps need to be done in two parts. The below example shows a single round of reading/writing, but with more signals you can make it much more complex.
Allowing access at GPU 1
This GPU is passive in the communication – it hosts the memory buffer, but cannot initiate transfers.
- Create a buffer with clCreateBuffer() using the flag CL_MEM_BUS_ADDRESSABLE_AMD.
- Make that buffer “resident” by using clEnqueueMakeBuffersResidentAMD(). This gives a cl_bus_address_amd struct, you need on the other GPU.
- Wait for other GPU with clEnqueueWaitSignalAMD().
- Use the buffer again.
Accessing to GPU 1 from GPU 2
This GPU is active in the communication and does the transfers from and to the other GPU that has the memory buffer.
- Align the address. See below.
- Create a working buffer for GPU 2.
- Create a virtual buffer with clCreateBuffer() using the flag CL_MEM_EXTERNAL_PHYSICAL_AMD and the cl_bus_address_amdstruct you got from clEnqueueMakeBuffersResidentAMD().
- Assign the virtual buffer to the queue of GPU 2 using clEnqueueMigrateMemObjects().
- Write data from the working-buffer to the virtual buffer using clEnqueueCopyBuffer(), or the reverse (reading from the working buffer to the virtual buffer). The extension is triggered to handle the copy to/from GPU 1.
- Signal GPU 1 the transfer is finished with clEnqueueWriteSignalAMD().
- Clean up the buffer.
Aligning the address
You need to manually align the buffer. The code to do that is as follows:
Aligned address = ulMarkerAddr & ~0xfff; Offset = ulMarkerAddr & 0xfff;
If you need multiple buffers, then you need to administrate the offsets. How that’s done exactly, you can find in the code linked below.
Code & more info
Download fully working sources of DirectGMA, and start to play around (found at Devgurus forum). This includes code for both OpenCL and OpenGL – you need to check the CLsources and a part of the common code. It contains a VS-solution and a Makefile. See also this more recent article from AMD.
At CLSink::processFrame() a buffer is created for writing to from another device. At CLSource::processFrame() a buffer at the other device is written to. The CLTransferBuffer object is created for both the Sink and Source. To test, you need two FirePro GPUs or a dual GPU like the S10000.
Want more information? Read this blog by AMD’s Bruno Stefanazzi, or contact us. We can also provide more insight into this mechanism than you read here, and can update your existing OpenCL software enabled with fast multi-GPU.















 2973
2973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









