







“分而治之”一直是一个非常有效地处理大量数据的方法。著名的MapReduce也是采取了分而治之的思想。 Fork就是分解任务,而Join 在Java线程中是等待意思 ,也就是等待计算结果。在实际应用中如果毫无顾忌地使用fork开启线程进行处理,那么很多可能会导致系统开启过多的线程而严重影响性能。所以在JDK中,给出了一个ForJoinPool线程池,对于fork方法并不急着开启线程,而是提交给ForkJoinPool线程池进行处理,以节省系统资源。
使用fork/Join 进行数据处理时的总体结构如图:
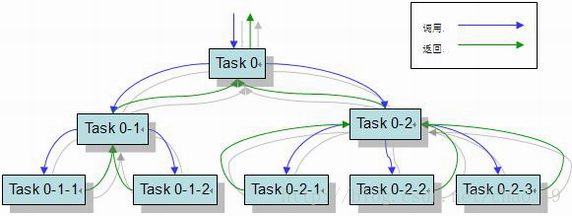
可以向ForkJoinPool线程池提交一个ForkJoinTask任务。所谓ForkJoinTask任务就是支持fork分解以及join等待的任务。ForkJoinTask有两个重要的子类 RecursiveAction和RecursiveTask。分别表示没有返回值的任务和可以携带返回值的任务。
public class CountTask extends RecursiveTask<Long> {
private static final int threshold = 1000;
private List<Integer> list;
public CountTask(List<Integer> list) {
this.list = list;
}
@Override
protected Long compute() {
long result = 0L;
int size = list.size();
System.out.println("size " + size);
if (size <= threshold) {
for (Integer i : list) {
result += i;
}
} else {
int count = size / threshold + 1;
List<CountTask> taskList = new ArrayList<CountTask>();
for (int i = 0; i < count; i++) {
int toindex = 0;
if (size < ((i + 1) * threshold)) {
toindex = size;
} else {
toindex = (i + 1) * threshold;
}
int fromIndex =i * threshold;
System.out.println("fromIndex " + fromIndex +"<><>"+"toindex " + toindex);
List<Integer> subList = list.subList(fromIndex, toindex);
CountTask c = new CountTask(subList);
taskList.add(c);
// c.fork();
c.fork();
}
for (CountTask c : taskList) {
result += c.join();
}
}
return result;
}
public static void main(String args[]) {
ForkJoinPool fp = new ForkJoinPool();
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 903000; i++) {
list.add(i);
}
CountTask task = new CountTask(list);
ForkJoinTask<Long> re = fp.submit(task);
try {
long res = re.get();
System.out.println(res);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









