






动机
在GA中有两个特征是必要的:
- 在找出包含最优解的范围之后,收敛到最佳效果的能力。(收敛能力)
-
探索解空间的新区域以寻找全局最优的能力。(寻优能力)
经过经验验证,适当的Pc值(0.5~1.0)和较小的Pm值(0.001~0.005)在传统遗传算法(SGA)实践中被普遍采用。而SGA存在着严重的缺点,它的Pc和Pm的值是固定的,不管是优良个体还是劣质个体都经过了相同概率的交叉和变异操作。这会引起两个很严重的问题:
-
相同的概率,这可以说是不公平,因为对于优良个体,我们应该减小交叉变异概率,使之能够尽量保存 ; 而对于劣质个体,我们应该增大交叉变异概率,使之能够尽可能的改变劣质的状况 。所以,一成不变的交叉变异概率影响了算法的效率。
- 相同的概率总不能很好的满足种群进化过程中的需要,比如在迭代初期,种群需要较高的交叉和变异概率,已达到快速寻找最优解的目的,而在收敛后期,种群需要较小的交叉和变异概率,以帮助种群在寻找完最优解后快速收敛。所以,一成不变的交叉变异概率影响了算法的效率。
基于上述SGA存在的种种问题,M.Srinivas 和 L .M. Patnaik在1994年的《Adaptive Probabilities of Crossover》论文提出了自适应的遗传算法(AGA)
自适应设计理念的诞生
AGA,旨在通过以不同的方式实现搜索和随机性之间的权衡,根据适合度值自适应地改变Pc和Pm的值 ,当群体倾向于停留在局部最优时(也就是群体适应度集中,多样性比较差时)Pc和Pm的值 增加,并且当群体在解空间中散布时(也就是群体适应度分散,多样性比较高时)减小。所以需要一个针对Pc和Pm的计算公式,让其符合动态变化。
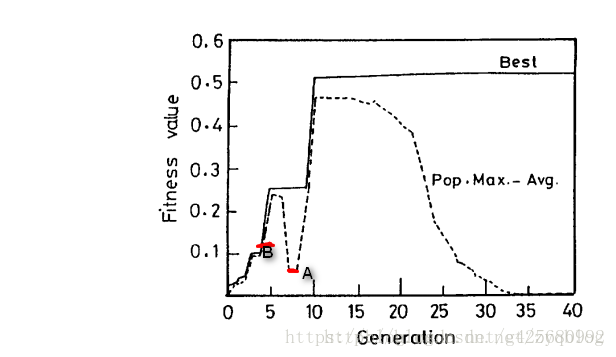
一种检测收敛的方法是: 观察种群的最大适应度值(Fmax)与种群的平均适应度值(Favg )的关系,也就是Fmax-Favg的大小情况。这个值越小,即Favg逐渐向Fmax靠拢,表明种群逐渐进化,可能解向最优解靠拢。当然,通过上图,我们也可以发现对于收敛到一个最佳解的种群 比 一个分散在解空间的种群的Fmax-Favg 可能会更小(如上图中A点比B点还要低)。
我们注意上图中,(我们从整个种群的进化角度来看。)当GA收敛到适应度值为0.5的局部最优值时(全局最优解具有1.0的适应度值),Fmax-Favg减小了。Fmax-Favg作为GA检测收敛的标准,Pc和Pm值会根据Fmax-Favg的值进行变化。因为GA收敛到局部最优时,Pc和Pm的值必须增加,也就说,当Fmax-Favg减小的时候,Pc和Pm要增加(与Fmax-Favg的相反),也就说Fmax-Favg的值与Pc和Pm的值成反比。
表达式为:

从上述表达式中,我们可以观察到Pc和Pm的值的确是根据种群的适应度而变化了,即,当种群适应度集中时候(Favg向Fmax靠拢,Fmax-Favg变小),Pc和Pm变大,相反的,变小。 但是 还存在两个问题:
- Pc和Pm的值并不是依赖于特定个体的适应值,而是整个种群的平均和种群最大适应值 。因此优良个体和劣质个体都进行了相同水平的交叉和变异。 ,所以这对优良个体和劣质个体而言不公平,毕竟我们的初衷是想要保存优良个体,让交叉和变异小一点 ; 而改变劣质个体,让交叉和变异大一点。
- 当一个种群收敛到全局最优解的时候(甚至是局部最优解的时候),Pc和Pm增加,并且可能导致接近最优个体的损坏。种群可能永远不会收敛到全局最优解。即使我们能够阻止GA陷入局部最优解,但是GA的性能(根据收敛所需要的代数)肯定会恶化。
为了克服上述问题,我们需要保存种群中优良的个体和改变劣质个体,可以通过以下方式实现 (我们从某一代种群内部各个体的角度来看) :
- 对于高适应度个体给予较低的Pc和Pm值,这有利于进行保存; 对于第适应度的个体给予高的Pc和Pm,这有利于劣质个体的改变。
- Pm的值不仅仅取决于
Fmax-Favg,还取决于个体的适应值F。 F越接近与Fmax,Pm的值应该越小,即 Pm应该直接等于(Fmax-F ),相似的,Pc的值应该也直接等于(Fmax-F ’ ) (F‘ 是两个要交叉个体中适应度较大的那个适应度值)。
现在对于Pc和Pm的表达式应该改为:

对最大适应度个体而言,Pc和Pm是0 。 如果一个个体的 F‘ = Favg 的话,Pc=k1,如果一个个体的 F = Favg 的话,Pm=k2 。对于一个适应度非常低(即F <<Favg)的个体而言, Pc和Pm的值可能会 >1.0 。为了防止Pc和Pm的值超过1.0,我们设置了以下约束:

所以,对于Pm和Pc的公式,总结为:

 的值
的值
在上述中,我们看到了一个适应度最高的个体,它的Pc和Pm都是0 。这个最好的个体被不停的复制到下一代。与选择机制一起循环,这可能导致这个最好个体在种群中以指数的增长形式快速增长,这会引起过早收敛。为了克服这个问题,我们为AGA(自适应遗传算法)的每一个个体都引进了一个默认的突变概率值(0.005)。
在现有文献中已经阐明了Pc应该取适当的值,最好为 0.5<Pc<1.0,Pm应该取小一点的值,最好为0.001<Pm<0.005,这是普通遗传算法(GAS)成功的必要措施。Pc的取值能够促进广泛的交叉,Pm的取值为了防止个体被破坏。然而,当Pc和Pm的值不变化时,这个方法是有效的和有意义的。
我们的方法的目标之一就是为了防止GA陷入局部最优解。为了实现这一个目标,我们采用低于平均适应度的个体去搜索空间中查找包含最优解的范围。像这种个体,需要被完全打乱,并且处于这种目的,我们让k4的值为0.5 。因为Favg的一个适应值的个体也应该被完全打乱,所以我们让K2的值也取0.5 。
基于类似的推论,我们让K1和K2的值取1.0 。这确保了所有适应度小于或者等于Favg的个体都要进行交叉操作。交叉的概率会随着适应度(父代个体中适应度最大的那个)趋向于Fmax而降低,并且这个概率对于适应度等于Fmax的个体为0.0 。
总结
通过自适应调节公式:
- 从种群整体来看:
随着种群的进化、可能解向着最优解靠拢,Favg逐渐接近Fmax,Fmax-Favg逐渐变小,Pc和Pm的值变大,这符合“ 随着种群迭代,适应度越来越集中,距离(局部)极值越来越近,为了增加种群多样性和跳出极值,Pc和Pm的值应该增大” 这一要求。
- 从某一代种群内部各个个体来看:
不同个体的交叉和变异概率随着自身适应度呈线性变化。适应度(F 或 F)越高的个体,Fmax-F或者Fmax-F'的值越小,这符合“ 保存优良个体”这一要求; 而适应度(F 或 F)越低的个体,Fmax-F或者Fmax-F'的值越大,这符合“ 改变劣质个体”这一要求。
特别的:
当个体的适应度等于当前当代种群中的最佳适应度(F'=Fmax或者F=Fmax)时,经过公式的计算可知,Pc和Pm都为0, 这也符合“把最佳个体保存下来”这一要求。
- 参数问题选择:
但是上述为0的情况虽然能把最佳个体保存,但是交叉和变异概率直接0,会导致那些保存下来的优良个体在种群中呈指数快速繁殖,导致早熟,所以让k2=0.5,k4=0.5,以利用种群中适应值低于平均值的个体来搜索全局最优解。同时推荐k1=1.0,k3=1.0。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









