







Word2Vec使用一层神经网络将one-hot(独热编码)形式的词向量映射到分布式形式的词向量。
1 Neural Network Language Model
2003年,Bengio等人发表了一篇开创性的文章:A neural probabilistic language model。
采用了一个简单的前向反馈神经网络来拟合一个词序列的条件概率
。
模型结构:
线性的Embedding层。将输入的N-1个one-hot词向量,经过一个D*V的矩阵C,映射成N−1个分布式的词向量。V是词典的大小,D是Embedding向量的维度。
前向反馈神经网络g。它由一个tanh隐层和一个softmax输出层组成。通过将Embedding层输出的N−1个词向量映射为一个长度为V的概率分布向量,从而对词典中的word在输入context下的条件概率做出预估:
![]()

通过最小化一个cross-entropy的正则化损失函数来调整模型的参数θ:
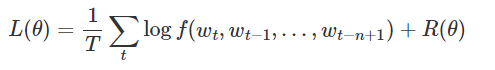
import argparse
import math
import time
import numpy as np
import tensorflow as tf
from input_data import TextLoader
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--data_dir', type=str, default='data/',
help='data directory containing input.txt')
parser.add_argument('--batch_size', type=int, default=120,
help='minibatch size')
parser.add_argument('--win_size', type=int, default=5,
help='context sequence length')
parser.add_argument('--hidden_num', type=int, default=64,
help='number of hidden layers')
parser.add_argument('--word_dim', type=int, default=50,
help='number of word embedding')
parser.add_argument('--num_epochs', type=int, default=10,
help='number of epochs')
parser.add_argument('--grad_clip', type=float, default=10.,
help='clip gradients at this value')
args = parser.parse_args()
data_loader = TextLoader(args.data_dir, args.batch_size, args.win_size)
args.vocab_size = data_loader.vocab_size
graph = tf.Graph()
with graph.as_default():
input_data = tf.placeholder(tf.int64, [args.batch_size, args.win_size])
targets = tf.placeholder(tf.int64, [args.batch_size, 1])
with tf.variable_scope('nnlm' + 'embedding'):
embeddings = tf.Variable(tf.random_uniform([args.vocab_size, args.word_dim], -1.0, 1.0))
embeddings = tf.nn.l2_normalize(embeddings, 1)
with tf.variable_scope('nnlm' + 'weight'):
weight_h = tf.Variable(tf.truncated_normal([args.win_size * args.word_dim, args.hidden_num],
stddev=1.0 / math.sqrt(args.hidden_num)))
softmax_w = tf.Variable(tf.truncated_normal([args.win_size * args.word_dim, args.vocab_size],
stddev=1.0 / math.sqrt(args.win_size * args.word_dim)))
softmax_u = tf.Variable(tf.truncated_normal([args.hidden_num, args.vocab_size],
stddev=1.0 / math.sqrt(args.hidden_num)))
b_1 = tf.Variable(tf.random_normal([args.hidden_num]))
b_2 = tf.Variable(tf.random_normal([args.vocab_size]))
def infer_output(input_data):
"""
hidden = tanh(x * H + b_1)
output = softmax(x * W + hidden * U + b_2)
"""
input_data_emb = tf.nn.embedding_lookup(embeddings, input_data)
input_data_emb = tf.reshape(input_data_emb, [-1, args.win_size * args.word_dim])
hidden = tf.tanh(tf.matmul(input_data_emb, weight_h)) + b_1
hidden_output = tf.matmul(hidden, softmax_u) + tf.matmul(input_data_emb, softmax_w) + b_2
output = tf.nn.softmax(hidden_output)
return output
outputs = infer_output(input_data)
one_hot_targets = tf.one_hot(tf.squeeze(targets), args.vocab_size, 1.0, 0.0)
loss = -tf.reduce_mean(tf.reduce_sum(tf.log(outputs) * one_hot_targets, 1))
# Clip grad.
optimizer = tf.train.AdagradOptimizer(0.1)
gvs = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -args.grad_clip, args.grad_clip), var) for grad, var in gvs]
optimizer = optimizer.apply_gradients(capped_gvs)
embeddings_norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / embeddings_norm
with tf.Session(graph=graph) as sess:
tf.global_variables_initializer().run()
for e in range(args.num_epochs):
data_loader.reset_batch_pointer()
for b in range(data_loader.num_batches):
start = time.time()
x, y = data_loader.next_batch()
feed = {input_data: x, targets: y}
train_loss, _ = sess.run([loss, optimizer], feed)
end = time.time()
print("{}/{} (epoch {}), train_loss = {:.3f}, time/batch = {:.3f}".format(
b, data_loader.num_batches,
e, train_loss, end - start))
np.save('nnlm_word_embeddings.zh', normalized_embeddings.eval())
if __name__ == '__main__':
main()
2 CBoW & Skip-gram Model
2.1 CBoW模型(Continuous Bag-of-Words Model):
从context对target word的预测中学习到词向量的表达

2.2 Skip-gram:
从target word对context的预测中学习到word vector
















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









