






这是一篇韩国科学技术院(KAIST)和汉阳大学发表在aaai 2023上的文章: https://arxiv.org/abs/2209.06535
一、目的和创新点
- 根据相机和radar的特点,提出了一种proposal-level的前融合框架,减缓了两种模态坐标系之间的差异和测量数据上的歧义
- 提出了Soft-Polar-Association 和 Spatio-Contextual Fusion Transformer两种结构,高效地在相机和radar之间交换信息
- nuScenes上效果很好
主要思路还是用radar的点来refine 图片propose出来的3D框;
二、精度、速度和资源开销
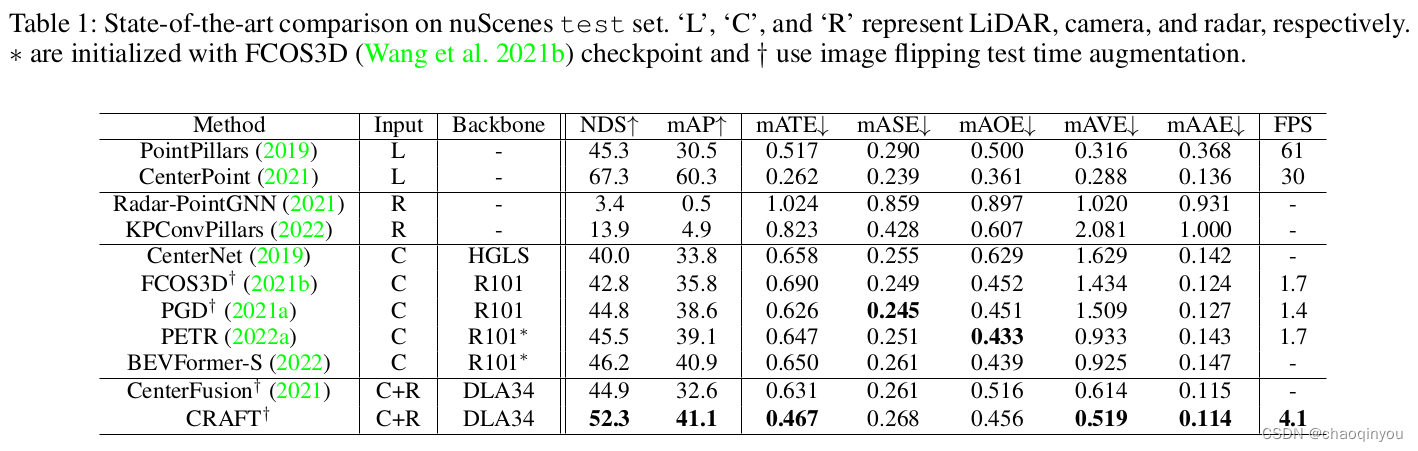
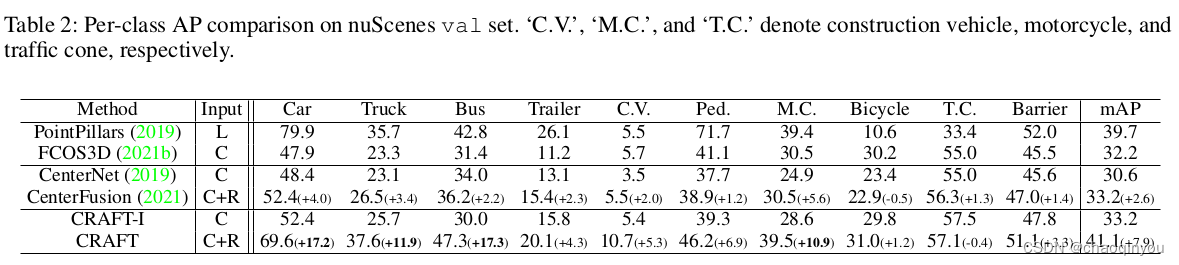
3090上4.1fps不快
car, pedestrain上还是比PointPillars要低,但是需要语义帮助的类别,比如bicycle, traffic cone上要比point pillars好(nuScenes是32线的lidar, 128线的数据集上这个结论不一定成立)
三、实现
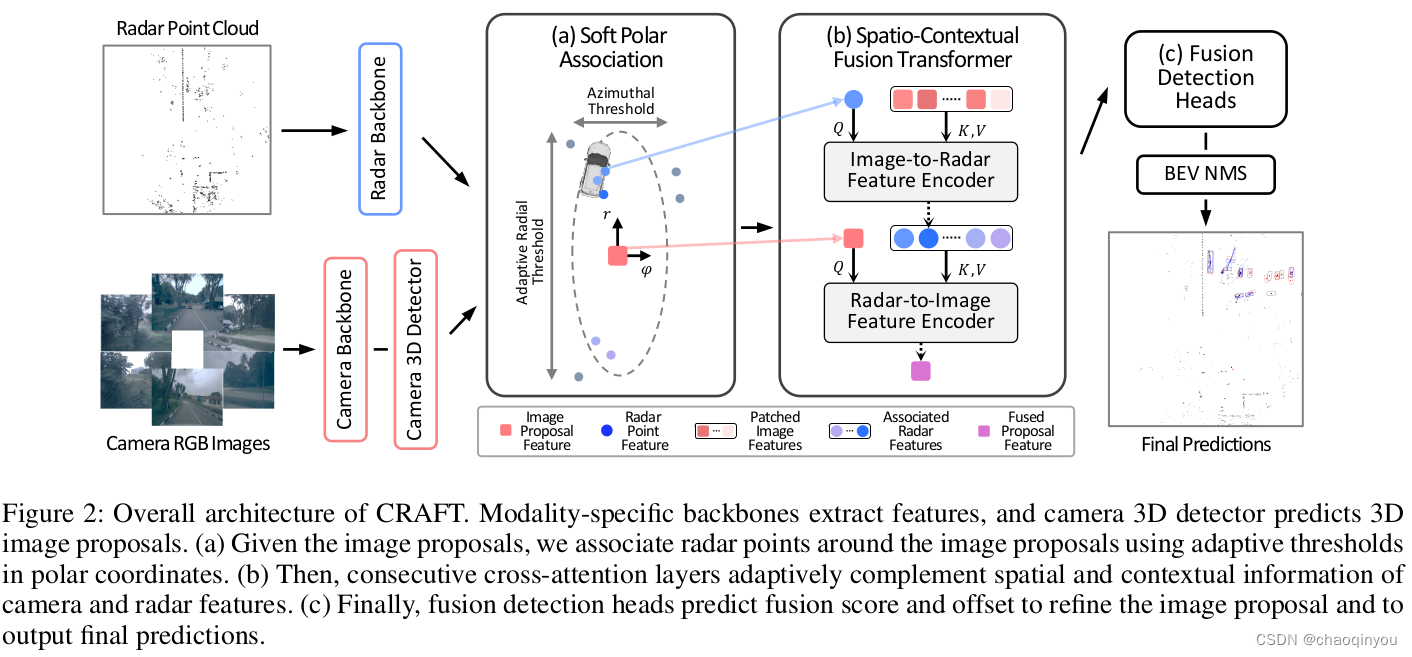
3.1 backbone 和相机目标检测3D目标检测
相机用cnn提取多视图特征,然后用3D目标检测propose框,框与其特征相关联: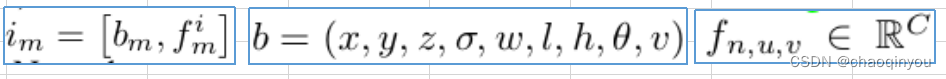
radar输入数据是5帧叠加,并且通过ego-motion和dopler速度进行补偿,然后用point-net++等point based的方法进行特征提取,之后通过Image to radar Feature Encoder进行decoration:
3.2 Soft Polar Association

把相机每个3D框和多个radar 的feature点在极坐标之下关联:
- azimuth的阈值直接用相机3D框的范围;
- 距离阈值方向会根据障碍物的距离和距离的置信度进行调整,越远/置信度越低,范围越大
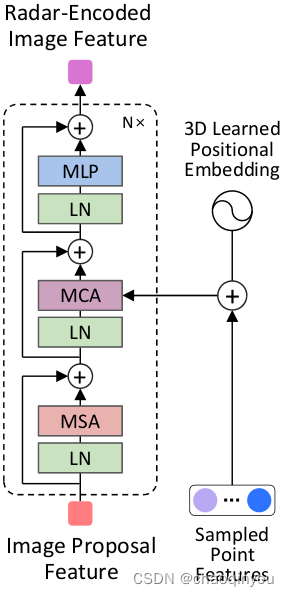
3.3 Image to Radar Feature Encoder:
把radar Feature投影到相机平面做局部的cross attention,这步可以和3.2并行搞,供后面的3.4用;
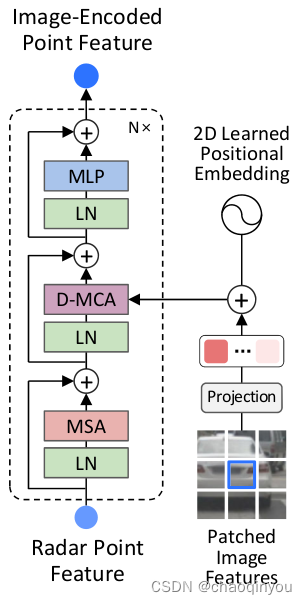
3.4 Radar-to-Image Feature Encoder
对于3.2每个图片3D框及其“框中”的radar Feature,做cross attention,搞完的Feature给后面的检测头用;如果图片框里面没有框中点,则补零
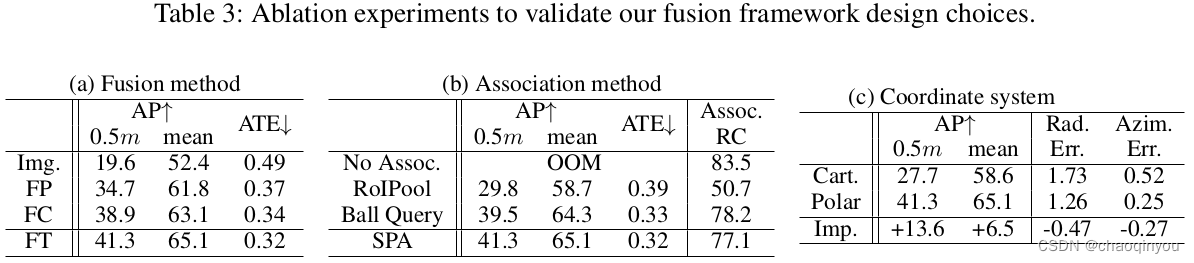
四、消融实验
个人理解:
2D中有遮挡,不好做associate, 所以放到3D做
图片propose的3D框的azimuth其实挺准的,所以在极坐标下回归更合适,集中精力把深度搞好
五、重要的参考文献
(2017 NeurIPS) Pointnet++: Deep hierarchical feature learning on point sets in a metric space


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









