







code: https://github.com/loshchil/AdamW-and-SGDW
除了纯SGD, L2 != weight_decay
背景知识:
sgd with momentum和adam,详见《深度学习》:

L2 regulization and weight decay:


伪代码
计算步骤上来说,sgdW, adamW就是对于使用了adaptive gradient的优化器, 不要在loss function里面写L2 regulization 啦,而是在weight更新的时候decay,回归到"weight dacay"的本意;

一、创新点和贡献
提出adamW: 使用adam时,通过使用将weight decay 从基于梯度更新中解耦,从而提高了正则效果,泛化性更好
adamW使得学习率和weight_dacay系数更加独立,从而调参也更加容易
二、精度
2.1 在不同学习率变化方式上的实验
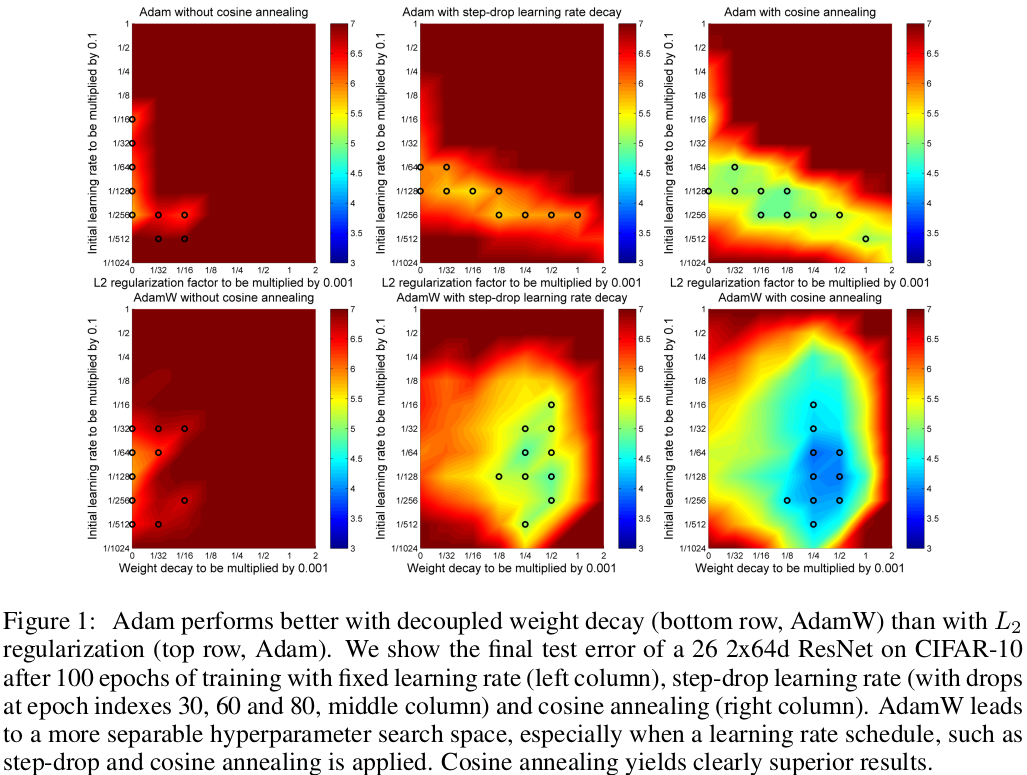
adamW好于adam, 配合cosine annealing食用更佳
2.2 对于weight_dacay系数和初始学习率的解耦实验
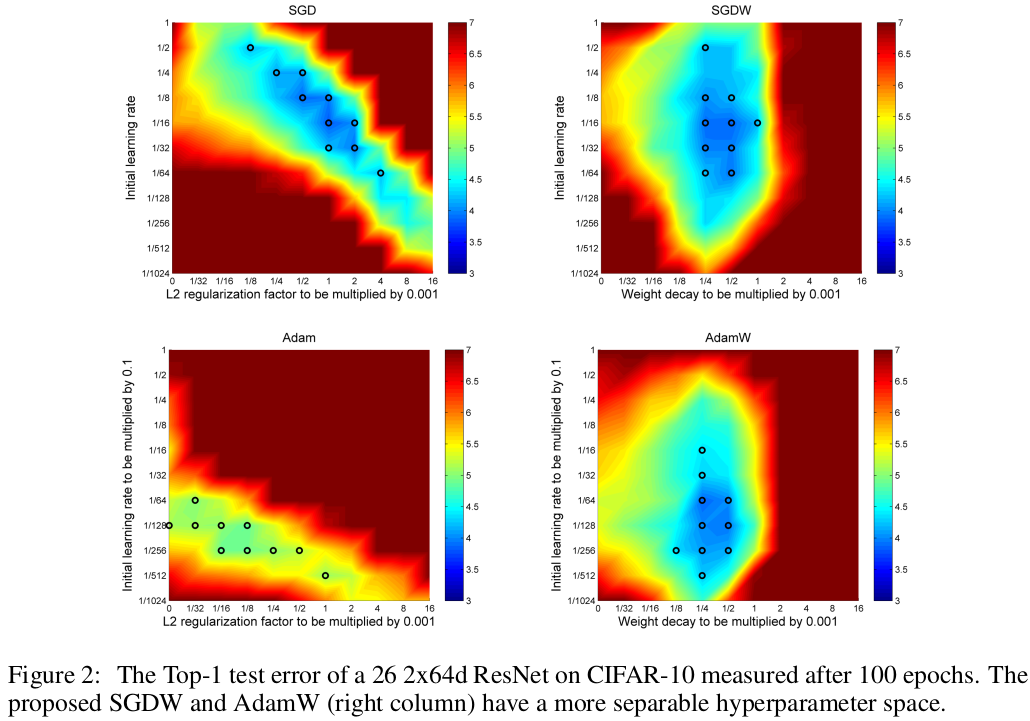
sgdW, adamW上weight_decay系数和初始学习率解耦,adamW也能够达到和sgdW相似的test set error
2.3 更好的泛化性能
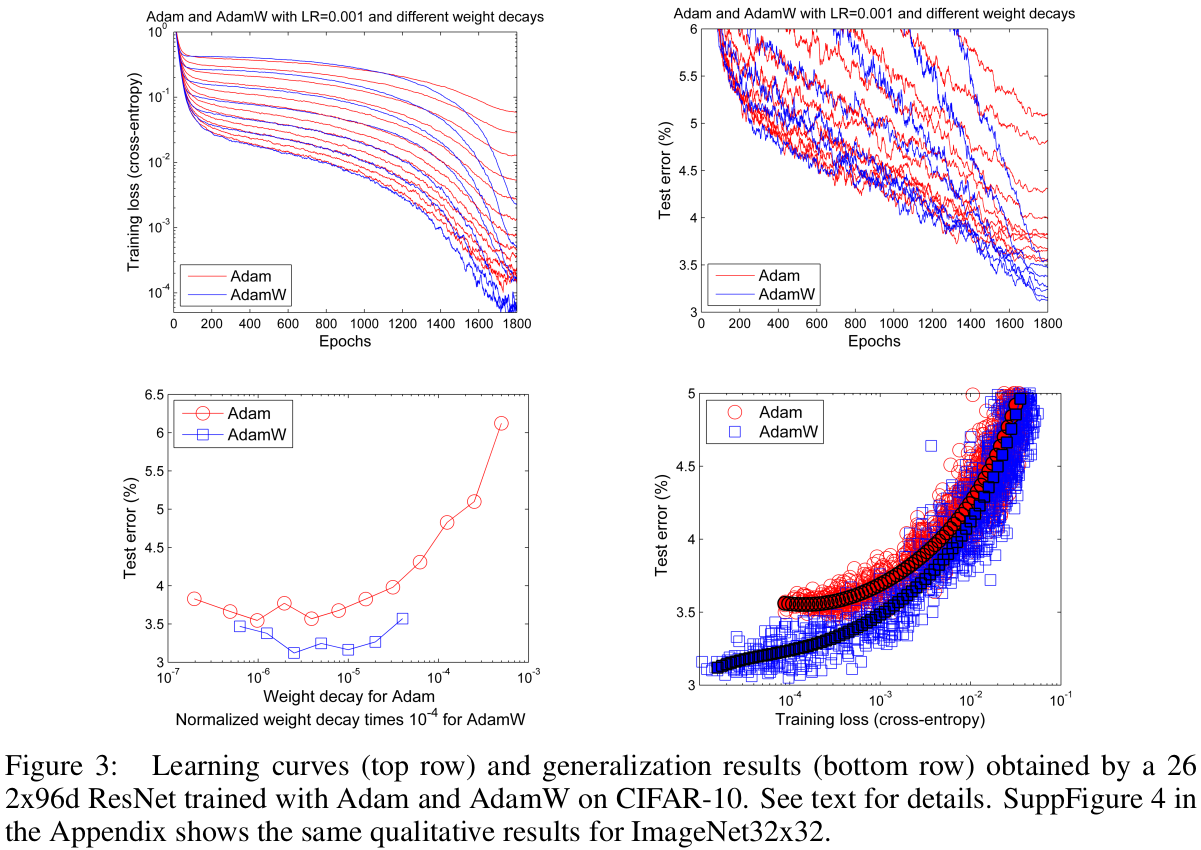
右下图: 在同样的训练损失下,adamW比adam有更低的test error (更好的泛化能力)
2.4 配合warm restarts使用
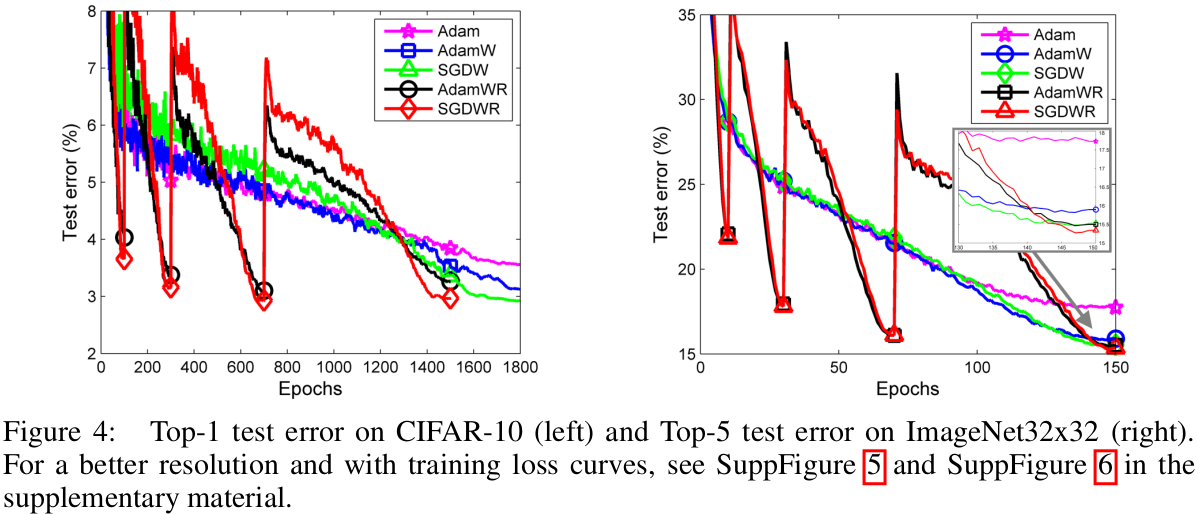
warm restarts能够大幅提高训练收敛速度,test error上也会好一点
三、原理
对于adaptive gradient的方法, L2 带来的“正则”幅度,会被 adaptive的时候归一化,对于绝对值比较大的weights, 等效于减小了regulize的幅度,所以更容易过拟合。
因此,对于adam等有adaptive gradient机制的优化器, loss函数中不要放L2 regulization,而是在更新的时刻做真正的weight decay:
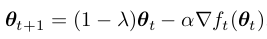

四、重要参考文献
SGDR: stochastic gradient descent with warm restarts
Comparing biases for minimal network construction with back-propagation
A unified theory of adaptive stochastic gradient descent as Bayesian filtering















 3591
3591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









