







系统环境:Centos7 虚拟机一台
Hadoop版本:3.0.3
Jdk1.8
笔记从安装虚拟机,下载hadoop包,jdk包之后说起。
第一步:将压缩包解压缩
tar -xvf 压缩包的名字

第二步:设置jdk的系统环境变量和hadoop的环境变量
vim /etc/profile
添加环境变量
export JAVA_HOME=/software/jdk1.8
export HADOOP_HOME=/software/hadoop-3.0.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:${JAVA_HOME}/bin
export CLASS_PATH=.:${JAVA_HOME}/lib
添加完之后执行source /etc/profile 让设置的环境变量生效。
执行java -version查看jdk环境变量是否生效,正常结果如下:

执行hadoop version 查看hadoop的环境变量是否设置成功,成功结果如下:
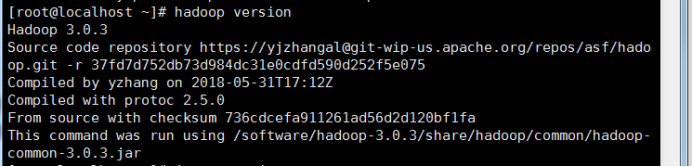
至此,jdk环境配置好了,接下来就是hadoop的启动配置。
第三步:配置hadoop属性文件
目标目录在hadoop解压缩之后的目录中
1、core-site.xml
vim /hadoop-3.0.3/etc/hadoop/core-site.xml
添加
<configuration>
<property>
<!--分布式中主节点的地址和端口号 -->
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<!--配置hadoop的公共目录 -->
<name>hadoop.tmp.dir</name>
<value>/home/hadoopdata/</value>
</property>
</configuration>
2、hdfs-site.xml
vim /hadoop-3.0.3/etc/hadoop/hdfs-site.xml
<configuration>
<!--hdfs副本数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
3.mapred-site.xml
vim /hadoop-3.0.3/etc/hadoop/mapred-site.xml
<configuration>
<!--指定MapReduce程序应该放在哪个资源调度集群上运行 -->
<!--若不指定,MR程序就只会在本地运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.yarn-site.xml
<configuration>
<property>
<!--指定yarn的老大 目前 是本机 -->
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<!--配置yarn集群中的重节点,指定map产生的中间结果传递给reduce 采用的是shuffle>机制 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5.hadoop-env.sh
添加JAVA_HOME环境变量,
export JAVA_HOME=/software/jdk1.8
第四步:关闭防火墙
Service firewall stop
第五步:免密登录
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
第五步:启动hadoop
第一次运行,先执行格式化操作:hadoop namenode -format
成功之后,执行启动hadoop命令:hadoop-3.0.3/sbin/start-all.sh
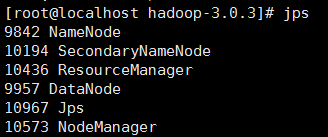
成功打印的结果如下

查看进程
大功告成。
下面是遇到的问题:
启动过程中遇到问题:
Stopping namenodes on [master]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Stopping datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Stopping secondary namenodes [slave1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Stopping nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
Stopping resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
原因是没有配置用户变量
vim sbin/start-dfs.sh
在前面添加
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
添加到末尾无效。
stop-dfs.sh 文件也给添加上面一样的变量。
vim sbin/start-yarn.sh
下面三个变量也是添加到前面
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
Stop-yarn.sh 文件中也在前面添加上面三个变量。
问题2: datanode没有启动成功
这个可能是之前安装过hadoop,然后设置的hadoop.tmp.dir是一样的路径,重装之没有清楚这个目录,这里面保存了namespaceID,这个是执行format之后保存的,重装之后没有删除,执行format之后的namesaceID与这个不同,所以启动失败,查看日志会发现datanode有个IOException,所以删除这个目录之后,重新执行format命令,再次启动hadoop就没有问题了。















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









