





1. 背景介绍
当 MySQL中一个表的总记录数超过了1000万后,会出现性能的大幅度下降吗?答案是肯定的,但是性能下降的比率不一而同,要看系统的架构、应用程序,甚至还要根据索引、服务器硬件等多种因素而定。比如FCDB和SFDB中的关键词,多达上亿的数据量,分表之后的单个表也已经突破千万的数据量,导致单个表的更新等均影响着系统的运行效率。甚至是一条简单的SQL都有可能压垮整个数据库,如整个表对某个字段的排序操作等。目前,针对海量数据的优化主要有2中方法:大表拆小表的方式和SQL语句的优化。SQL语句的优化可以通过增加索引等来调整,但是数据量的增大将会导致索引的维护代价增大。在此不详述,建议大家参考相应的High Performance MySQL等书籍。另外,大表拆小表的方式主要有两种:
垂直分表: 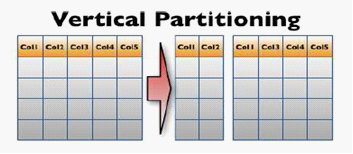
图1. 垂直分区示意图
对于垂直分表,它将一个N1+N2个字段的表Tab拆分成N1字段的子表Tab1和(N2+1)字段的子表Tab2;其中子表Tab2包含了关于子表Tab1的主键信息,否则两个表的关联关系就会丢失。当然垂直分表会带来程序端SQL的修改,若是应用程序已经应用很长的一段时间,然后程序的升级将是耗时而且易出错的,即升级的代价将会很大。
水平分表: 
图2. 水平分区示意图
水平分区技术将一个表拆成多个表,比较常用的方式是将表中的记录按照某种Hash算法进行拆分,简单的拆分方法如取模方式。同样,这种分区方法也必须对前端的应用程序中的SQL进行修改方可使用。而且对于一个SQL,它可能会修改两个表,那么你必须得写成2个SQL语句从而可以完成一个逻辑的事务,使得程序的判断逻辑越来越复杂,这样也会导致程序的维护代价高,也就失去了采用数据库的优势。因此,分区技术可以有力地避免如上的弊端,成为解决海量数据存储的有力方法。
MySQL 5.1分区技术初探(一)
最新推荐文章于 2024-11-10 22:27:03 发布
















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









