






最近好多同学私信我:“救命!论文被查出AIGC率超高,怎么破?”
别慌!今天这篇干货,手把手教你压住AI率。从平台测评到实操技巧,全学科通用!
先搞懂什么是AIGC?
AIGC就是AI生成的内容。简单来说,就是机器写的句子。
系统检测AIGC率,就是查你的论文里有多少像AI写的部分。
AI写的东西有啥特点?比如句子太长、用词死板、逻辑太顺溜。
举个例子,AI可能会写:“通过实验分析,我们发现该方法的有效性显著提升。”
这种句式,系统一抓一个准。
避坑第一步:选对检测平台!
市面上的检测工具五花八门,选错平台可能白花钱。
我实测了4大平台,优缺点全给你扒清楚:
1. 知网智检:权威但贵
-
价格:2块/千字(含AIGC检测)
-
优点:高校都认它,中英文混检也没问题。
-
缺点:公式类内容查不出来,跨章节分析也不行。
适合人群:学校指定用知网的同学。
2. 维普AIGC检测:严到变态
-
价格:20块/次(全篇检测)
-
优点:查得比知网还狠,连代码都能揪出来。
-
缺点:不给分章节报告,图片内容查不准。
适合人群:想彻底“消毒”的强迫症患者。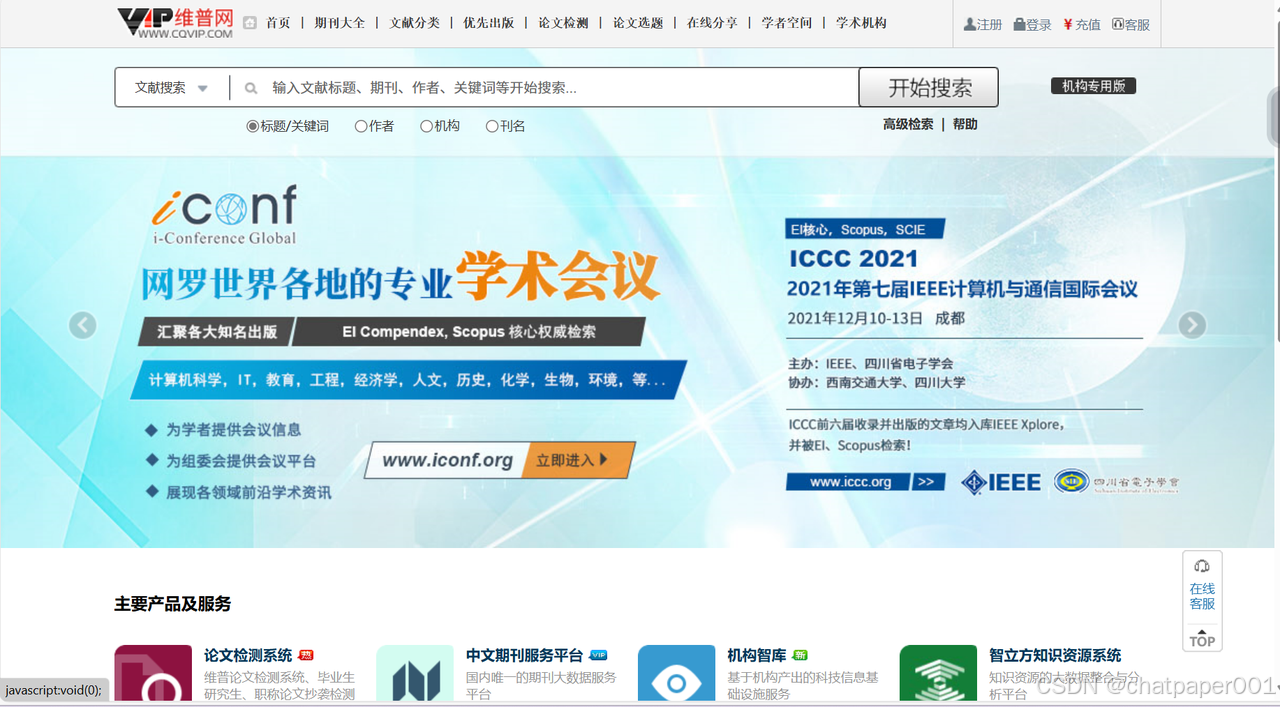
3. MasterAIgc:免费试一次
-
价格:19.9元/篇
-
优点:不用注册,报告秒删不留痕。
-
缺点:学校不认,只能自己偷偷用。
适合人群:预算有限,想先摸底的同学。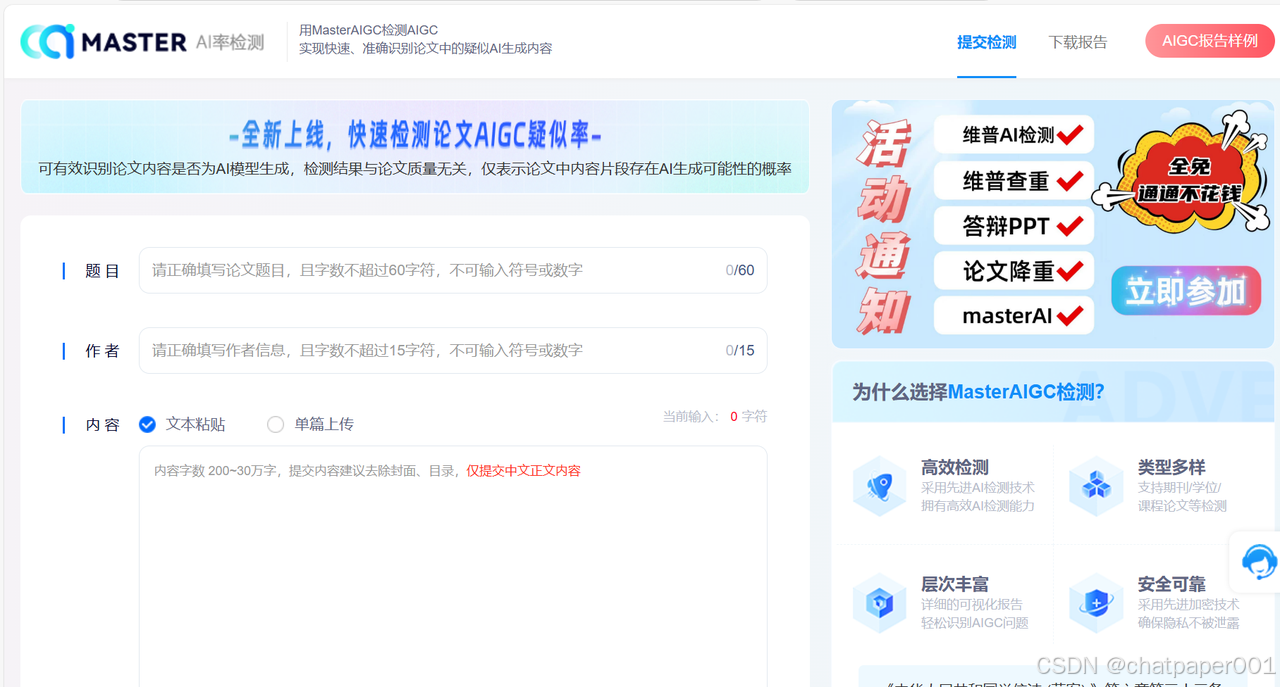
4. Turnitin国际版:留学生必备
-
价格:10块/千字(英文)
-
优点:全球数据库最全,图表也能查。
-
缺点:中文检测稀烂,方言直接摆烂。
适合人群:写英文论文的留学生。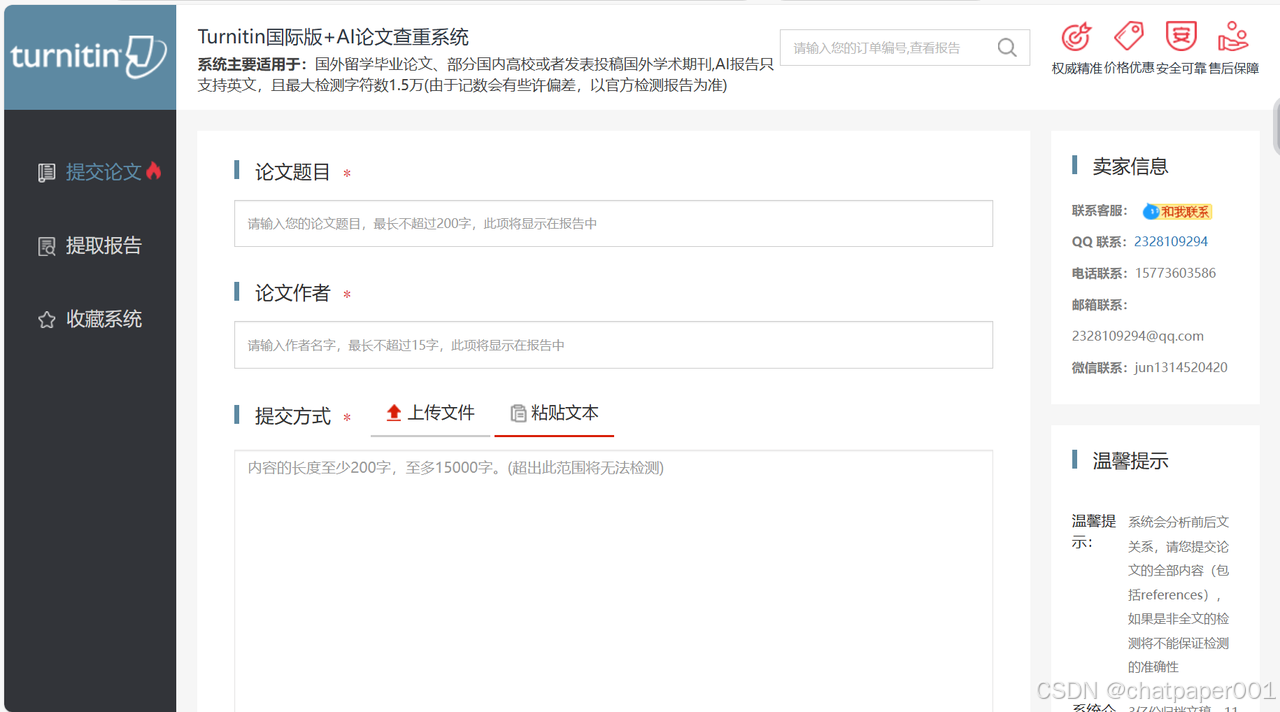
6个压AIGC率的超实用技巧
技巧1:别让AI逮住你的“和”
AI特爱用“和”字,比如“分析数据和研究案例”。 这种句子系统一眼就能认出来。 所以建议大家用“并且”“以及”替换。 比如:“分析数据,并且考察案例。” 再比如,用点高级词:“多媒体技术不仅提升了效率,更优化了体验。”
技巧2:序数词换成“骚操作”
“首先、其次”这种词,AI用得比谁都溜。 换成“其一”“其二”,立马就顺眼了。 或者玩点花样:“横向看现象,纵向挖原因。” 再比如:“核心问题其实是……延伸开来会发现……”
技巧3:同一个词别用超过3次
比如“方法”这个词,AI能给你重复十遍。 赶紧建个同义词库! 理论类论文用“范式”,实践类用“路径”,技术流用“架构”。 再比如,“分析数据”改成“解析数据”,“重要的”换成“关键性”。
技巧4:短句合并,长句拆解
AI生成的短句像流水账:“效果好。效率高。” 咱们得改!比如:“这个方法效果显著,尤其能提升工作效率。” 反过来,长句太绕也要拆:“传统教学有个毛病,师生互动太少。但用了多媒体后,课堂明显活跃了。”
技巧5:少总结,多提问
AI特爱用“综上所述”“由此可见”。 咱偏不!试试用问题过渡:“这能说明什么?其实背后还有深层逻辑……” 或者直接亮观点:“本段论证表明,核心矛盾在于资源分配。”
技巧6:终极神器——笔灵AI
前面5招够实用了吧?但有人还是嫌麻烦。 所以,直接上大招——笔灵AI。
它能干嘛?上传论文,2分钟把AI率压到安全线。自动拆句子、换词汇、调逻辑。 改完的论文,读起来和真人写的一模一样!
更绝的是,它还能帮你写答辩PPT、生成论文框架。改稿不限次数,直到你满意。
直达链接:👉https://ibiling.cn/paper-pass?from=csdnai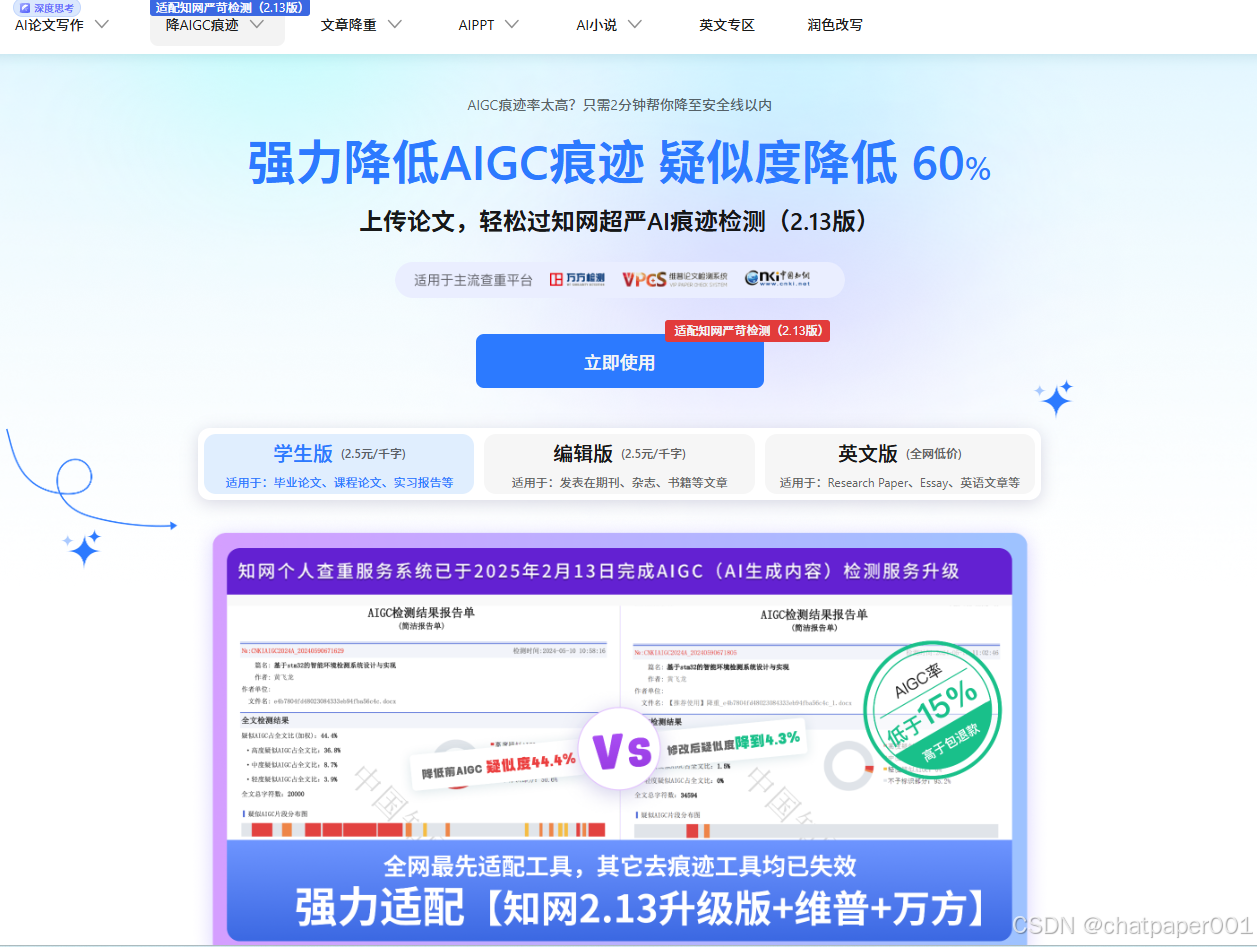
怎么用AI工具才不翻车?
话说回来,AI不是洪水猛兽。关键看你怎么用。
核心部分:比如理论推导、结论,尽量自己写。AI介入别超15%。
基础工作:比如整理文献、洗数据,放心交给工具。
记住三阶模型:AI筛检→人工验证→双向校准。
把AI当助手,别当枪手。你的论文才能真正有灵魂!
最后说点大实话
降AIGC率不是为了糊弄系统,而是让论文更“像人话”。 毕竟,导师想看到的是你的思考,不是机器的流水线作业。
但话说回来,谁还没个赶DDL的时候呢? 时间紧就用笔灵AI救急,时间宽裕就慢慢磨技巧。两手准备,稳过!
P.S:别等查重了才后悔!写完初稿立马测AIGC率,早发现早治疗。

















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









