







论文中的专业术语:
MVQA:Multimodal Video Question Answering
MSAN:Modality Shifting Attention Network
MPN:moment proposal network
HRN:heterogeneous reasoning network
MIM:Modality Importance Modulation
摘要:
这篇文章针对多模态视频问答任务,提出了一种叫做Modality Shifting Attention Network (MSAN)的网络。
MSAN可以分解为两个子任务:(1) localization of temporal moment relevant to the question(与问题相关的时间的定位) (2) accurate prediction of the answer based on the localized moment.(基于定位的时间来预测答案)。
这个模型要求的时间定位或许问题预测不一样,并且模型转换的能力对于完成任务是必要的。
MSAN基于(1):moment proposal network(MPN)用于为每一个模型定位最准确的时间 (2)异构推理网络用于在两个模型上使用注意力机制来预测答案。
MSAN可以使用一个组件叫做Modality Importance Modulation (MIM).,在在两个模型上为每个子任务放重要性权值。
problems:1、在所有异构模式中定位有助于回答问题的关键时刻
2、对于MVQA任务,是否有能力在异构的模型上进行推理来回答问题。
2、Modality Shifting Attention Network
Multi-modal Video Question Answering (MVQA):是在Video QA的基础上增加了test modality。比如说对字幕的理解。
Modality Shifting Attention Network Framework:

由两部分构成:1、Moment Proposal Network(MPN) 2、Heterogeneous Reasoning Network(HRN)。
对应于MSAN的两个子任务:(1)时间的定位(2)对问题的预测,这两个task需要不同的模型来完成。
2.1输入表示
视频表示。就像最近在MVQA上的其他方法一样,输入视频被表示为一组检测到的对象标签。具体地说,以3fps的速度对视频进行采样形成帧集,然后使用在Visual Genome上预训练的Faster RCNN来检测由对象标签和属性组成的视觉概念。
我们把输入视频划分成按时间顺序排列的视频截图集,来减少冗余。与视频不同的是,字幕对话中本身就少冗余,所以不用再次划分。
在MVQA里面我们使用motion cues来帮助理解视频截图,据我们所知,我们是第一个使用motion cues的。因为观察到motion cues对于理解视频切片有帮助。
文本表示:我们给视频和字幕中的句子,提取了768个维度 word level的文本表示。这些提取出来的表示在训练中是固定的。给每个假设,MSAN学会预测它的正确得分,并且最大化正确答案的得分。为了简单表示,我们给接下来的假设加上下标K。
2.2Moment Proposal Network
Moment Proposal Network(MPN)用于定位回答问题要求的感兴趣的时刻。对于每一个感兴趣的时刻(MoI),MPN都生成两个时刻分数,一个模式一个分数。模型重要性调制器调整每个模型的时刻分数来权重对时刻来说重要的模式。
2.2.1 Moment of Interest Candidate Generation
我们使用预定义的滑动窗口为暂时排列的视频和字幕生成了N个MoI的候选。每一个MoI候选由一系列的flatten后的视频截图和字幕句子构成,表示为v ∈ ,s ∈
,
是视频中视觉对象的数量,
是字幕中单词的数量。我们为每个模型定义多种长度的滑动窗口,这样MoI候选可以在时间轴上均匀分布并且包含整个视频。如果和GT(ground-truth) moment的IoU>=0.5,我们就给MoI候选标上正标签;并给其他的MoI标上负标签。
2.2.2 MoI Candidate Moment Score
在N个MoI候选中,MPN要定位和回答问题相关的MoI,MPN首先为每个MoI候选产生视频/字幕时刻的分数。我们首先使用context-to-query(C2Q)注意力机制来对每个上下文(视频和字幕)和假设进行联合建模来得到和
。C2Q的细节可以在2.3.1节找到。然后我们把串联的特征[V;
] and [S;
]输入进一层的双向LSTM接着沿着时间轴通过一个最大池化。这个最终的视频和字幕特征fv, fs会传给共享的分数回归(FC(d)-ReLU-FC(1)-σ) ,分别输出视频/字幕时刻分数
,
。
2.2.3Modality Importance Modulation
Modality Importance Modulation(MIM)调整时刻分数,为了给重要的模型放更多的权值。但是重要形态的分数会被加强,别的部分会被抑制。用来调制的系数,可以通过传递平均池化问题到带sigmoid的一个多层感知机(FC(d)-ReLU-FC(1))来限制
的范围。
MIM 公式如下:
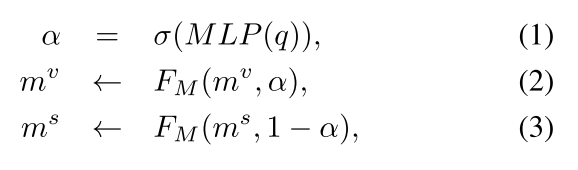
是调制函数。
我们考虑三种调制函数:1、加法 2、乘法 3、加法乘法混合
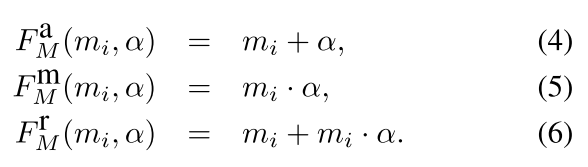
在推理的时候,MPN为答案预测选择时刻分数最大的MoI候选。
cross-modal ranking loss提出来训练MPN。它使拥有正的时刻分数的MoI候选比负数大一个特定的margin。我们提出在两个模型上整合时刻分数和应用ranking loss,而不是分开在两个模型上分别这么做。我们把cross-modal ranking loss叫做,由如下表示:
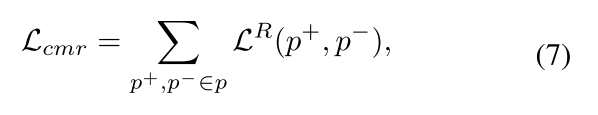
P+和P-分别表示正的和负的分数的candidate,并且L是带margin b的ranking loss。在训练的时候,为了稳定的训练,我们采样相同数量的正分数和负分数样本。
Relationship between MPN and Other Methods
MPN背后的原理和广泛用于目标检测的region pro- posal network (RPN)类似。不同的是,RPN在空间维度定义了一系列锚点,而MPN在时间维度定义了一系列MoI 候选。在这两种情况下,分类器被训练使用检测到的特征作为输入,然后输出对象类或者正确答案的索引。然而,MPN是一个依赖条件的方法,它的行为会随着输入问题而改变。由于MPN定位了一个特定的时间区域,它可以被看做是一种硬注意力机制。相反,软注意力机制在之前的工作中一直是主流机制。我们相信MPN可测量性更好使用更公平的指标,并且更少的噪声。
2.3 Heterogeneous Reasoning Network
异构推理网络使用MPN定位好的MoI并且学习推理正确答案。HRN包含参数有效的异构注意力机制heterogeneous attention mechanism (HAM) 来考虑模型内和模型间的影响。HAM通过在所有三个异构模态特征空间中表示视频或字幕中的每个元素来转换视频和字幕特征,从而实现丰富的特征交互。MIM再一次调制HRN的输出给重要的模式加weight。
2.3.1 Heterogeneous Attention Mechanism
引入异质注意机制(HAM)来考虑模态间和模内的相互作用,方法是通过其他模态特征的线性组合来代表某一模态特征。

HAM由三个基本的注意力单元组成:1、self-attention (SA) 2、context-to-query (C2Q) attention 3、context-to-context (C2C) attention。以上三个都基于:dot product attention。
对于输入的特征X和Y,dot-product attention 首先计算X和Y每个元素的点积以获得相似矩阵,然后对相似矩阵的每一行用softmax,来获得M*N的注意力矩阵:
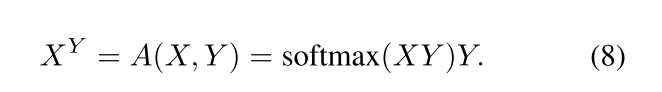
我们可以将dot-product attension解释为使用Y的线性组合来代表X,从而在Y的特征空间表示X的每个元素。
自注意SA单元是dot-product attention使用自身特征用来定义模式内的关系。SA表示为A(X,X),X为输入特征。C2Q和C2C注意单元考虑模式间的关系,分别定义为A(C,Q)和A(C,C),这三个注意力单元在定义异构注意力机制(HAM)时,结合在一个模块里。
在HRN里面,HAM使用定位的视频V,字幕S,假设H作为输入;然后输出两个转化后的上下文特征,
。首先每个特征都有SA单元更新,然后上下文被C2Q转换到假设空间,被C2C转换到别的上下文空间。如下面数学公式所示:
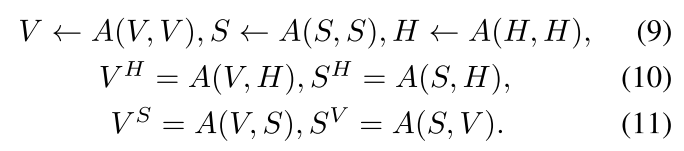
最后我们连接这三个特征维度的单元的输出来建立一个丰富的上下文描述器,如下所示:
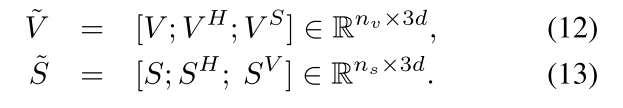
作为结果,作为一个在视频特征空间、假设特征空间和字幕特征空间他自己的连接。
作为他自己字幕的链接在三个特征空间。
2.3.2 Modality Importance Modulation and Answer Reasoning
随着异构注意力的学习,输出的视频特征 ∈
和字幕特征
∈
包含关于各种模式的丰富信息。然后
和
输入到一层的双向LSTM和沿时间轴的最大池化,来形成最终的特征向量。我们为每个视频和字幕使用两层的MLP(FC(d)-ReLU-FC(5))来获取预测分数l
和L
∈
预测分数再一次被Modality Importance Modulation(MIM)调整:
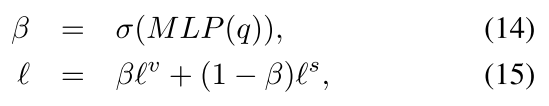
L代表最终的预测分数。我们使用标准的交叉熵作为损失函数来训练一个最终预测评分顶部的5维的分类器。
3、实验
3.1数据集
TVQA是目前最大的基准MVQA数据集,TVQA包含从6个长的TV节目中切片短视频的人类标注的多选择问题-答案对。在TVQA中标注的问题结构如下:【what/how/where/why/...】________【when/before/after】______? 问题的第二部分定位视频切片中的相关时刻。并且第一部分询问关于定位时刻的问题。每个问题包含5个答案候选并且他们当中只有一个是对的。TVQA中总共有152.5K个问题-答案对,21793个视频切片被分成了21793视频切片。训练集当中有122,039个问题-答案对,17,435个视频切片;验证集当中有15,252个问题=答案对和2179个视频切片;测试集当中有7623个问题-答案对和1089视频切片。
3.2 实验细节
整个框架是用Pytorch写的,我们设置batch size为16。使用Adam优化,初始学习率设置为0.0003。所有的实验都使用NVIDIA TITAN Xp(12GB内存)GPU使用cuda加速。我们训练网络使用10epochs,在验证集正确率在2个epochs不上升的情况下使用early stopping。在所有的实验中,都使用严格的train/validation/test。
3.3 消融实验
3.3.1 在MPN上的消融实验,这个小节描述定量的消融实验。给两个时刻,IoU定义为:
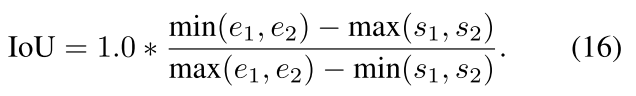
MPN的主旨是减掉不相关的时刻区域。定位的MoI和ground truth重叠的效果更好。为了反映这个偏好,Coverage metric如下所示:
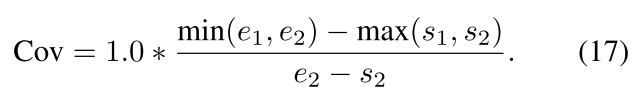
table1总结了MPN上的消融实验。

table2总结了model variants的消融实验:

table3是在TVQA上的模型的性能对比:

4.结论
在本论文中,将 MVQA 分解成了两个子任务:
(1)定位与问题相关的视频时刻
(2)基于定位的时刻来预测正确的答案
基本动机是时间定位所需要的模态可能和答案预测所需要的模态不同。
所以提出了 Modality Shifting Attention Network (MSAN) 包含两个主要
组件对应两个子任务:(1)moment proposal network (MPN)用来定位具体的
时刻(2)heterogeneous reasoning network (HRN)异构推理网络使用多模态
注意力机制来预测答案
同时也提出了 Modality Importance Modulation (MIM) 模态重要性调制来
使能 MPN 和 HRN 模态之间的转换。
MSAN 在 TVQA 上实现了 SoTA。71.13%的测试集准确率















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









