







 本文介绍了决策树的学习过程,包括信息熵、信息增益和信息增益率的概念,以及如何选择划分属性。同时,讨论了过拟合、欠拟合和剪枝在防止模型过复杂中的作用,提出预剪枝和后剪枝策略。最后,简述了多变量决策树的特性,即非叶节点使用属性的线性组合进行分类。
本文介绍了决策树的学习过程,包括信息熵、信息增益和信息增益率的概念,以及如何选择划分属性。同时,讨论了过拟合、欠拟合和剪枝在防止模型过复杂中的作用,提出预剪枝和后剪枝策略。最后,简述了多变量决策树的特性,即非叶节点使用属性的线性组合进行分类。
我觉得决策树是机器学习所有算法中最可爱的了……没有那么多复杂的数学公式哈哈~下图是一棵决策树,用来判断西瓜是好瓜还是坏瓜:
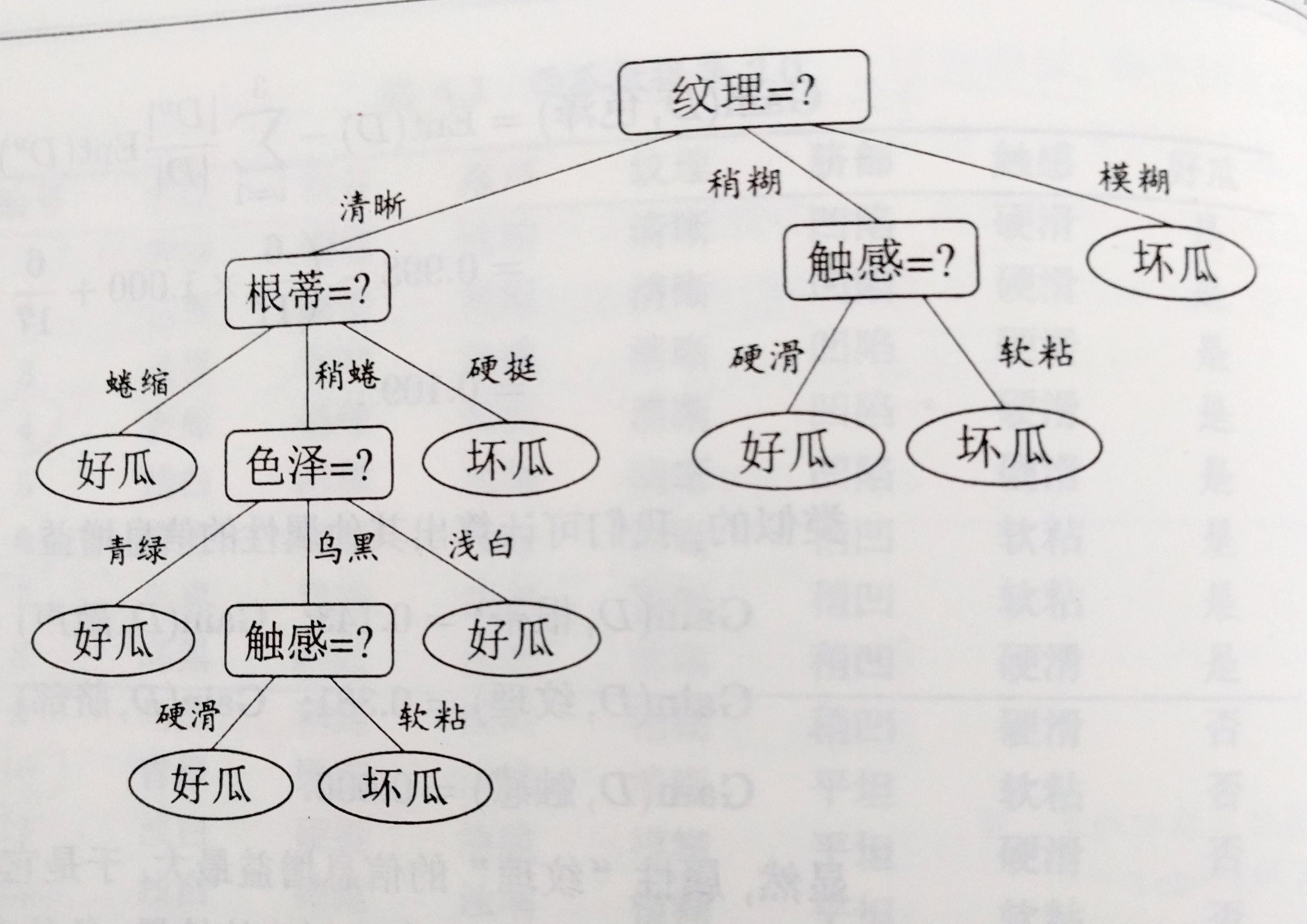
决策过程中提出的每个判定问题都是都对某个属性的测试,每个测试结果要么推导出最终结论,要么导出进一步判断的问题,在上次决策结果限定的范围内做进一步判断。从上图可以看出,叶节点对应决策结果,其他节点都是属性测试。决策树学习的目的是产生一棵泛化能力强,处理未见示例能力强的决策树模型。
决策树基本算法过程如下(一个递归算法):

三种情况会导致递归返回(也就是成功判断了类别):1)当前结点包含的样本属于同类别,不需要再划分;2)当前属性集为空,或是所有样本在属性上取值相同,无法划分;3)当前按节点包含的样本集合为空,不能划分。
决策树的关键是:如何选择最好划分。如何选择划分属性使得决策树包含的分支节点尽可能属于同类,即结点的“纯度“越来越高。下面介绍衡量标准。
信息熵、信息增益、信息增益率
信息熵是度量样本集合纯度的最常用指标。假设样本集合D分类最终结果有k类,第i类所占比例为p [i],则D的信息熵为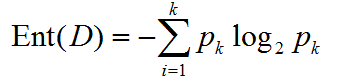
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









