







功能建模:数据流图
数据流图:
1.以图形的方式来描述系统中数据流程的活动状态。(这里的系统是指当前层用数据流图表示的整个抽象模型)
2.包含逻辑输入(输入的数据),逻辑输出(转换后输出的数据),加工处理(从逻辑输入数据转换为逻辑输出的数据所需的加工处理)

功能建模:
1.就是以图形的方式建立一个模型。
2.从整个活动过程对可再细化成一个以上的活动过程,进行逐层分解为细化的新的一块数据流图。
3.功能建模有以下的三个特点:(这三个特点在之后对数据流图进行分层拆解时,会提到)
-自顶向下
-逐层分解
-逐步求精
个人理解:关于特点,比如用功能建模的方法来描述用户登录账号的系统。顶层数据流图为用户(用户是指外部实体)输入账号和密码(逻辑输入),进行登录(加工处理),得出登录后的结果(逻辑输出),最终的结果显示在客户端上(外部实体)。
这里的“进行登录”作为一个数据变换的活动还可以再细化为新的一层数据流图,编号为0层的系统(即逐层分解)。0层数据流图可以把“进行登录”细分为“验证账号和密码“和“改变登录状态”(若登录成功,由离线改为在线状态)。以此类推,再进行逐一分解下一层的系统,再细化系统中信息传递和变换的细节(逐步求精)。从顶层到0层,从0层到1层,从1层一直到不可再细分的最终数据流图(自顶向下)。
所以功能建模和数据流图的关系是:
1.功能建模包含有一个以上的数据流图,具体自顶向下,逐层分解,逐步求精的三个特点。简单来说,数据流图描述的是一个系统加工的活动状态,而功能模型是一个分层描述整个加工的活动状态的数据流图。
2.数据流图可用于功能建模,数据流图是功能建模的其中一种描述,也称为数据流模型。
3.数据流图不包括“数据存储“。
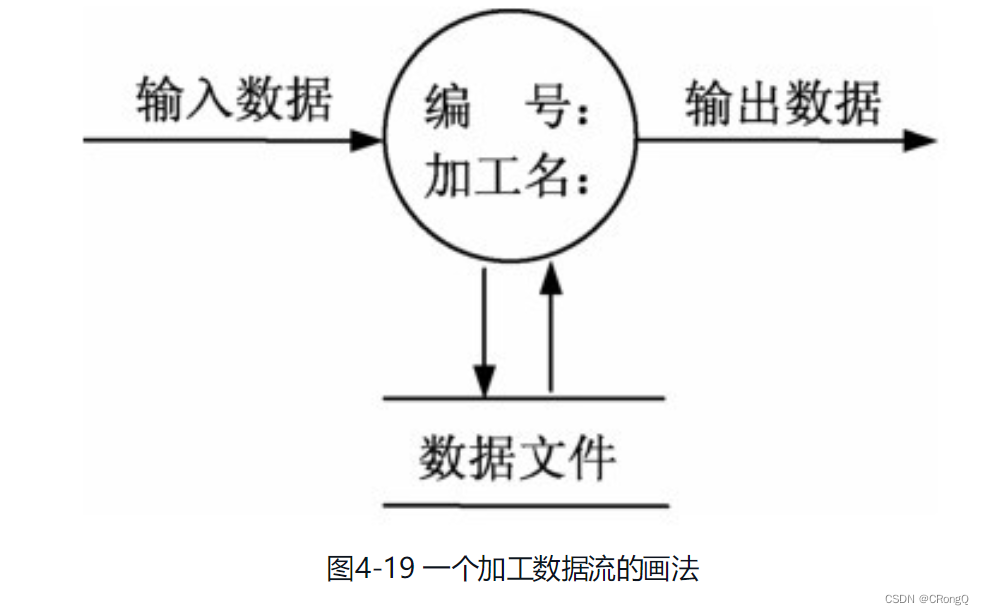
(1)数据流图符号
下文会引用大量书中的文字段。
如图3.3(a)所示,数据流图有4种基本符号:
(1)外部实体:正方形(或立方体)表示数据的源点或终点;它是系统之外的实体,可以是人,物或者其他系统。“□”
[存在系统边界,例如:部分,人员,组织]
(2)数据变换:圆角矩形(或圆形)代表变换数据的处理;表示对数据进行加工或处理,比如对数据的算法分析和科学计算。“〇”
(3)数据存储:开口矩形(或两条平行横线)代表数据存储;表示输入或输出文件。这些文件可以是计算机系统中的外部或者内部文件,也可以是表,账单等。“=”
[通常出现在中间和底层的数据流图中]
(4)数据流:箭头表示数据流,即特定数据的流动方向。数据流可以从加工流向加工,从加工流向文件,从文件流向加工。“→”

处理并不一定是一个程序。一个处理框可以代表一系列程序,单个程序或者程序的一个模块;它甚至可以代表用穿孔机穿孔或目视检查数据正确性等人工处理过程。一个数据存储也并不等同于一个文件,它可以表示一个文件,文件的一部分,数据库的元素,记录的一部分等;数据可以存储在磁盘,磁带,磁鼓,主存,微缩胶片,穿孔卡片及其他任何介质上(包括人脑)。
(5)分解的程度。系统自顶向下逐层分解时,可以把一个加工分解成几个加工。当每一个加工都已分解到足够简单时,分解工作就可以结束了。足够简单的不再分解的加工称为基本加工。如果某一层分解不合理、不恰当,就要重新分解。
数据流图由许多的加工用箭头互相连接构成,
数据流存在:从加工→加工,加工→文件,加工→终点,源点→加工,文件→加工;
不存在:文件→文件,文件→终点,源点→文件,源点→终点。
(6)加工说明。加工说明或者说加工处理(process specification)过程,用于描述系统的每一个基本加工处理的逻辑,说明输入数据转换为输出数据的加工规则。加工逻辑仅说明“做什么”就可以了,而不是实现加工的细节。加工说明的描述方式可以用结构化语言、判定表、判定树、IPO(输入—处理—输出)图等。
所谓结构化语言,是自然语言加上结构化的形式,是介于自然语言与程序设计语言之间的半形式化语言,特点是既有结构化程序清晰易读的优点,又有自然语言的灵活性。判定表是一种表格化表达形式,主要用于描述一些不容易用语言表达清楚或者用语言需要很大篇幅才能表达清楚的加工。判定树是判定表的图形形式。
数据存储和数据流都是数据,仅仅所处的状态不同。数据存储是出于静止状态的数据,数据流是处于运动中的数据。
通常在数据流图中忽略出错处理,也不包括诸如打开或关闭文件之类的内务处理,数据流图的基本要点是描绘“做什么“而不考虑”怎样做“。
有时数据的源点和终点相同,这时如果只用一个符号代表数据的源点和终点,则将有两个箭头和这个符号相连(一个进一个出),可能其中一条箭头线相当长,这将降低数据流图的清晰度。
另一种表示方法是再重复画一个同样的符号(正方形或立方体)表示数据的终点。有时数据存储也需要重复,以增加数据流图的清晰程度。
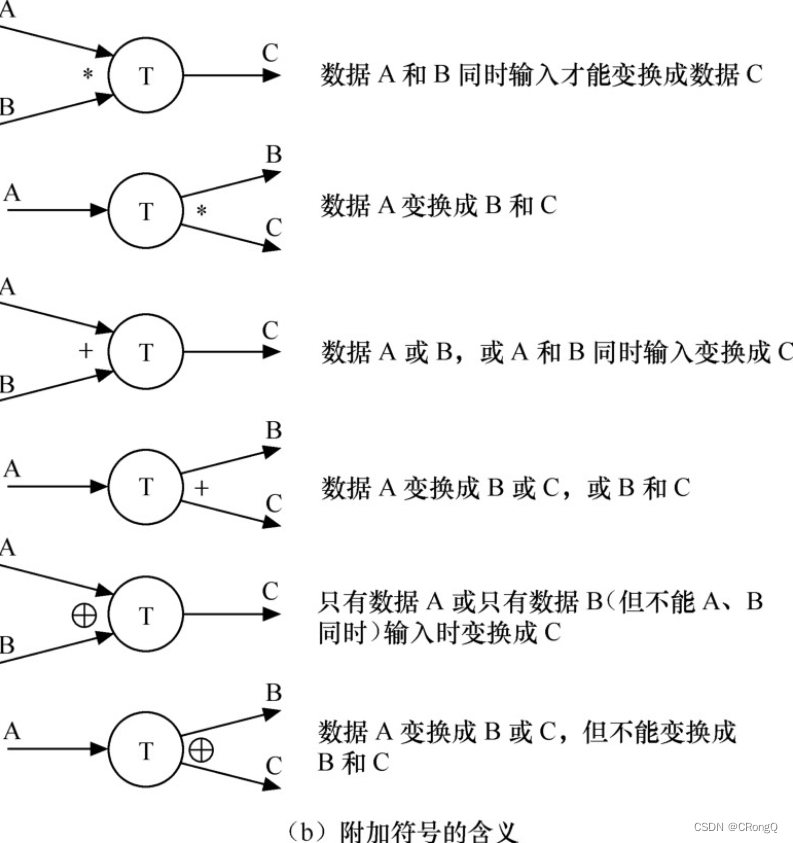
为了避免可能引起的误解,如果代表同一个事物的同样符号在图中出现在n个地方,则在这个符号的一个角上画n-1条短斜线做标记。除了上述4种基本符号之外,有时也使用几种附加 符号。星号(*)表示数据流之间是“与“关系(同时存在);加号(+)表示”或“关系;(⊕)号表示只能从中选一个(互斥的关系)。图3.3(b)所示为这些附加符号的含义。
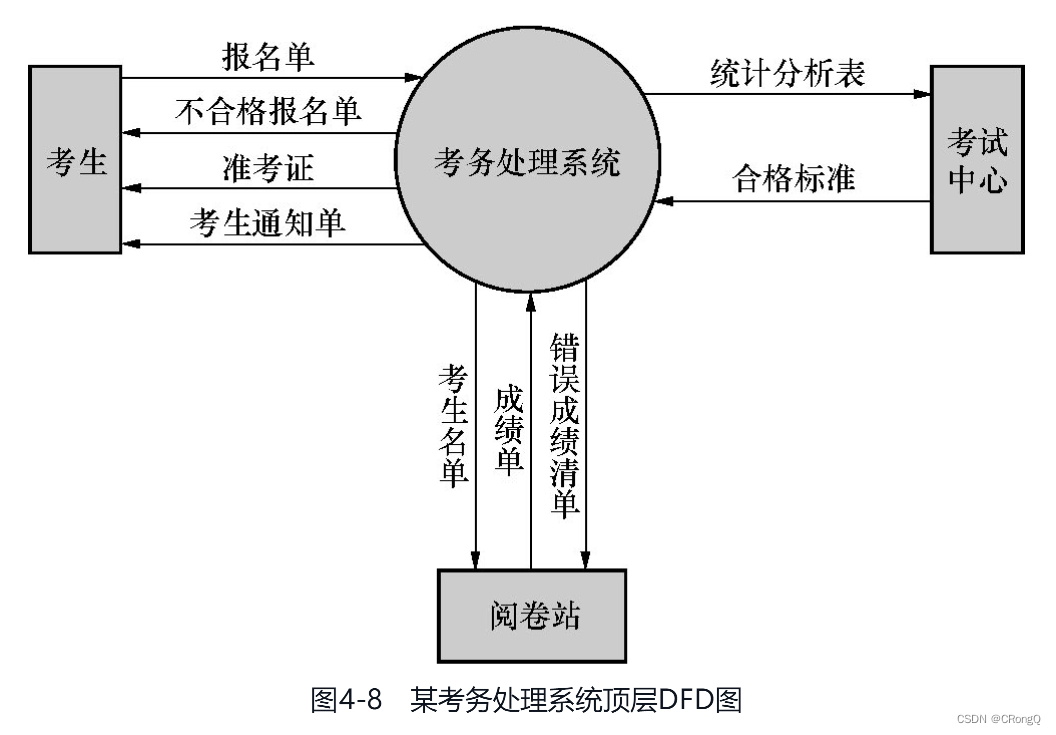
(2)环境图
环境图(见图4-7)也称为系统顶层数据流图(或0层数据流图),仅包括一个数据处理过程,也就是要开发的目标系统。
环境图的作用:确定系统在其环境中的位置,通过确定系统的输入和输出与外部实体的关系确定其边界。

根据结构化需求分析采用的“自顶向下,由外到内,逐层分解”的思想,开发人员要先画出系统顶层的数据流图,然后再逐层画出低层的数据流图。顶层的数据流图要定义系统范围,并描述系统与外界的数据联系,它是对系统架构的高度概括和抽象。底层的数据流图是对系统某个部分的精细描述。
图4-8是某考务处理系统顶层DFD图。其中只用一个数据变换表示软件,即考务处理系统;包含所有相关外部实体,即考生、考试中心和阅卷站;包含外部实体与软件中间的数据流,但是不含数据存储。顶层DFD图应该是唯一的。
(3)数据流图的分解
对顶层DFP图(环境图)进行细化,得到0层DFD图。如图4-9所示。软件被细分为两个数据处理,把这个泡泡“〇”“考务处理系统“细分为“登记报名表”和“统计成绩“,以及数据存储”考生名册“。(书上“泡泡”所指的是数据流图中“加工处理”成分)

在下一层的数据流图进行分解时,顶层的泡泡就会分解成下一层的0层DFD图。因此,对以上图4-9进行下一层细化工作时,分别对“等级报名表“和”统计成绩“进一步分解下层的数据流图。



命名问题
对数据流图中每一成分的命名,需要留意别人的理解程度;
所以命名需要注意:
1.能够代表整个数据流(或数据存储)的内容
2.不能使用没有具体含义的名字(如“数据”,“信息”“输入”,“输出”等)
3.如果起名有困难,是否考虑对数据流进行重新分解,来解决整个问题;
4.优先为数据流命名,再为与之相关联的处理命名。
5.能清晰描述整个处理的功能,而不是其中的一部分功能;
6.最好使用及物动词+宾语;(尽量不要使用空洞含义的动词,比如“加工”,“处理”)
7.一般只包含一个动词。如果有必须用到两个动词才能描述清楚,应当考虑把这个处理再分解成两个处理;
绘制数据流图时,注意:
1.数据的处理不一定是一个程序或一个模块,也可以是一个连贯的处理过程。
2.数据存储是指输入或输出文件,但它不仅可以是文件,还可以数据项或用来组织数据的中间数据。
3.数据流和数据存储是不同状态的数据。数据流是流动状态的数据,数据存储是指处于静止状态的数据。
4.当目标系统的规模较大时,为了描述得清晰和易于理解,通常采用用逐层分解的方法,画出分层的数据流图。在分解时,要考虑自然性,均匀性和分解度几个概念。
(1)自然性是指概念上要合理和清晰。
(2)均匀性是指尽量将一个大问题分解为规模均匀的若干部分。
(3)分解度是指分解的维度,一般每个加工每次分解最多不超过7个子加工,应分解到基本的教工为止。
(4)数据流图分层细化时必须保持信息的连续性,即细化前后对应功能的输入和输出数据必须相同。
画数据流图的基本原则
1.数据流图中所有的符号必须是前面所属的4种基本符号和附加符号。
2.数据流图的主图(顶层)必须含有前面所述的4种符号,缺一不可。
3.数据流图的主图上数据流必须封闭在外部实体之间(外部实体可以是一个,也可以是多个)。
4.加工(变换数据处理)至少有一个输入数据流和一个输出数据流,反映出此加工数据的来源与加工的结果。
5.任何一个数据流子图必须与它父图上的一个加工相对应,父图中有几个加工,就可能有几张子图,两者的输入数据流和数据流必须一致,即所谓“平衡”。
6.图上的每个元素都必须有名字(流向数据存储或从数据存储流出的数据流除外)。
画数据流图的步骤
先画数据流图的主图,大致可分为以下几步:
1.第一步,先找外部实体(可以是人,物或其他软件系统),找到了外部实体,则系统与外界的界面就得以确定,系统的源点和终点也就找到了。
2.第二步,找出外部实体的输入和输出数据流;
3.第三步,在图的边上画出系统的外部实体;
4.第四步,从外部实体的输出流(源点)出发,按照系统的逻辑需要,逐步画出一系列变换数据的加工,直到找到外部实体处所需的输入流(终点),形成数据流的封闭;
5.第五步,按照上述步骤画出所有子图。
注意事项
1.画数据流图时,只考虑数据流的静态关系,不考虑其动态关系(如启动,停止等于与时间有关的问题),也不考虑出错处理问题。
2.画数据流图时,只考虑常规状态,不考虑异常状态,这两点一般留在设计阶段解决。
3.画数据流图不是画程序流图图,二者有本质的区别。数据流图只描述“做什么”,不描述“怎么做”和做的顺序,而程序流程图表示对数据进行加工的控制和细节。
4.不能期望数据流图一次画成,而是要经过各项反复才能完成。
5.描绘复杂系统的数据流图通常很大,对于画在几张纸上的图很难阅读和理解。一个比较好的方法是分层的描绘这个系统。
在分层细画时,必须保持信息的连续性,父图和子图要平衡,每次只细画一个加工。

图3.3中父图与子图是不平衡的,因为父图中的加工4没有输入与子图4的输入数据流H相对应,也没有输出与输出数据流C相对应,因此是不平衡的。图3.4中从表面上看父图与子图是不平衡的。因为父图的加工2中的输入与子图2的输入数据流不相同,但是借助与下面将要介绍的数据字典中数据流的描述可知,父图的数据流“考生信息”由“考生姓名”、“准考证号”、“通信地址”和“考生成绩”4部分的数据项组成,即子图是父图中加工、数据流同时分解而来的,因此这两张图是平衡的。

因此,父图和子图的平衡是指父图中某加工的输入输出数据流和分解这个加工的子图的输入输出数据流必须完全一致,即数目必须相等。
例子

根据表3.1描述的内容,画出顶层数据流图:

由于图3.4所示的基本系统模型太抽象了,了解的信息很有限。那么,下一步应该把基本系统模型细化,描绘系统的主要功能。
根据以上3.1图,“产生报表”和“处理事务”是系统必须完成的两个主要功能,它们将代替图3.4中的“定货系统”,如图3.5所示。(拆解为两个下一层的数据流图)


细化后的数据流图中还增加了两个数据存储:处理事务需要“库存清单”数据;产生报表和处理事务在不同时间,因此需要存储“定货信息”。在图3.5中给处理和数据存储都加了编号,这样做的目的是便于引用和追踪。














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









