







 本文探讨了mini-batch SGD训练算法存在的问题,包括在最优点附近震荡和收敛速度问题。介绍了Momentum方法如何有效解决这些问题,通过引入动量概念改进参数更新过程,实现更稳定和快速的收敛。
本文探讨了mini-batch SGD训练算法存在的问题,包括在最优点附近震荡和收敛速度问题。介绍了Momentum方法如何有效解决这些问题,通过引入动量概念改进参数更新过程,实现更稳定和快速的收敛。
mini-batch SGD训练算法的问题:1)虽然能够带来很好的训练速度,但是在到达最优点的时候并不能够总是真正到达最优点,而是在最优点附近徘徊。容易产生一些震荡。
2)采用小的学习率的时候,会导致网络在训练的时候收敛太慢;当我们采用大的学习率的时候,会导致在训练过程中优化的幅度跳过函数的范围,也就是可能跳过最优点。
Momentum方法:能够很好的解决SGD中上面的两个问题。
SGD更新参数的方式:参数![]() 等于上次的值,减去学习率*梯度。
等于上次的值,减去学习率*梯度。
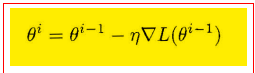
Momentum更新参数的方式:
第一步:先计算动量的速度,Vdw等于上一次的值和梯度dW共同计算得到,其中![]() 取值一般为0.9。
取值一般为0.9。
![]()
第二步: 更新参数W,这里的![]() 才为学习率。
才为学习率。
![]()

















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









