







train_val.prototxt文件和deploy.prototxt文件区别和转换
1.train_val.prototxt文件和deploy.prototxt文件介绍。
train_val.prototxt:训练与测试使用的网络结构文件
deploy.prototxt:模型构造文件。用于实际场景使用时的网络结构文件。
这两个文件是caffe的网络结构文件。train_val.prototx是训练时候的网络结构,deploy.prototxt用于发布(即测试时候的网络结构)。
2.二者的主要不同之处
(1)两个文件开头的输入数据不一样。
train_val.prototxt 中的开头:定义的是训练和测试数据的来源。
name: "MOBILENET_V2"
layer {
name: "Data1"
type: "Data"
top: "Data1"
top: "Data2"
include {
phase: TRAIN
}
transform_param {
mean_value: 96.6855
mean_value: 97.078
mean_value: 102.185
crop_size: 224
mirror:false
}
data_param {
source: "/home/caffe-ssd/data/resnet_shuzi/lmdb224X224/train_lmdb"
batch_size: 16
backend: LMDB
}
}
layer {
name: "Data1"
type: "Data"
top: "Data1"
top: "Data2"
include {
phase: TEST
}
transform_param {
mean_value: 96.4856
mean_value: 96.9166
mean_value: 101.907
crop_size: 224
mirror:false
}
data_param {
source: "/home/caffe-ssd/data/resnet_shuzi/lmdb224X224/test_lmdb"
batch_size: 8
backend: LMDB
}
}deploy.prototxt的开头:不需要定义训练和测试数据集的下相关信息,它只需要定义输入数据的大小格式。
name: "MOBILENET_V2"
layer {
name: "data"
type: "Input"
top: "data"
# 输入数据的batch size, channel, width, height
input_param { shape: { dim: 1 dim: 3 dim: 224 dim: 224 } }
}
(2)参数初始化
train_val.prototxt中会在对卷积层、全连层中的weight,bias等参数进行初始化。
deploy.prototxt中加载训练caffemodel中训练好的参数进行预测,因此不需要进行初始化。
如果要将train_val.prototxt转换成deploy.prototxt,需要将卷积层和全连层中的weight,bias参数初始化删掉。

(3)accuracy层不同。
train_val.prototx中需要测试准确率,而deploy则不需要。在将train_val.prototxt转换成deploy.prototxt时,如果train_val.prototxt中含有accuracy层,则将其删掉。
layer {
name: "Accuracy1"
type: "Accuracy"
bottom: "fc70"
bottom: "Data2"
top: "Accuracy1"
include {
phase: TEST
}
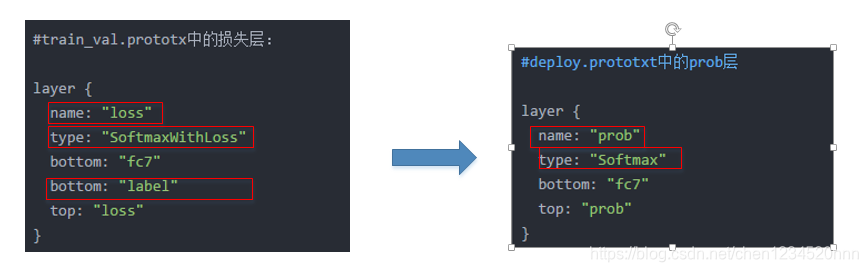
}(4)将train_val.prototxt中损失层的“name”改为 prob ,“type”改为 softmax,并删除输入的标签。
train_val.prototxt中的损失层:type为SoftmaxWithLoss。(因为训练的时候必须有loss作为反馈)
#train_val.prototx中的损失层:
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc7"
bottom: "label"
top: "loss"
}
deploy.prototxt的prob层:而deploy.prototxt的type为Softmax
#deploy.prototxt中的prob层
layer {
name: "prob"
type: "Softmax"
bottom: "fc7"
top: "prob"
}

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









