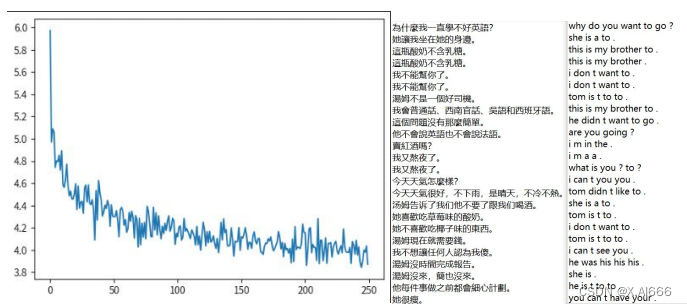
从 loss 图来看最低达到 3.9,通过翻译的结果对比,原始代码的翻译效果几乎没有,我认为 RNN 在这次文本翻译中表现较差主要因其难以捕捉长期依赖性、容易出现梯度问题、记忆容量有限、缺乏并行性而造成的。
2,将 RNN 模型替换成 GRU 和 LSTM
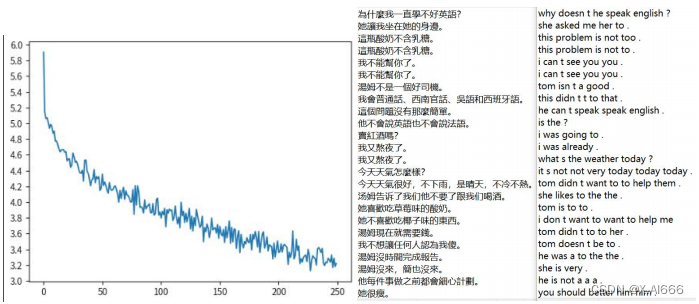
在模型替换为 GRU 的时候明显 loss 下降了更多而且翻译效果也相对于原来 RNN模型有一定提升。比如句子‘为什么我一直学习不好英语’GRU 模型的翻译为why is i speak english english ?而 RNN 模型的翻译为 why do you want to go ?,可以看出虽然两者都不完全对,但是 GRU 模型的翻译很接近正确答案了,而 RNN 的翻译基本不沾边,所以在这次 RNN 模型替换为 GRU 的实验中效果明显提升。
改进为 LSTM
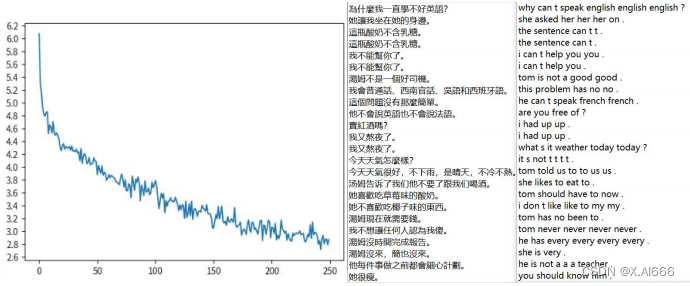
从 loss 图来看比起原始的 RNN 有明显更多的下降,从翻译效果来看也是如此。比如句子‘今天天气怎么样’在 LSTM 模型的翻译是 what s the weather today ? 而在 RNN 模型的翻译是 what is you ? to ?。明显 LSTM 完全翻译正确,而 RNN 的翻译压根不搭边,所以这次 RNN 模型替换成 LSTM 的效果有明显提升。
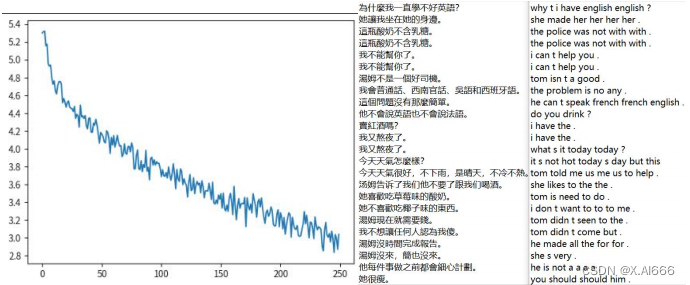
从 loss 图可以看出 loss 明显比原来单向的 GRU 的时候下降更多了,最低达到了2.8,并且从翻页的结果来看也明显优于原来单向的 GRU,比如在我不能帮你了。翻译成了 i can t help you,而在单向的 GRU 中翻译成了 i can t you you you you。有明显的效果提升,
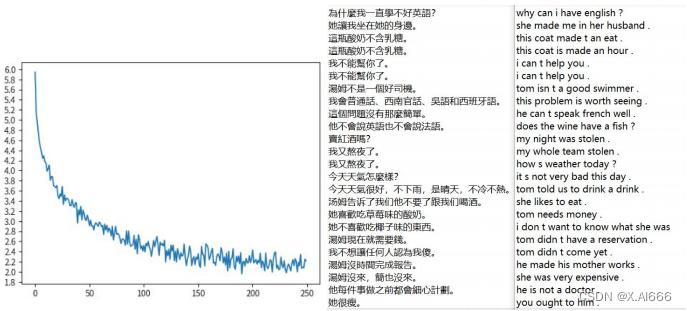
从 loss 图来看相对于单向的 LSTM 的 loss 下降了更多,最低达到 2.95,然后再从翻译结果来看也比单向的 LSTM 要更好一点,比如句子‘他不会说法语也不会说英语’,单向 LSTM 的翻译结果是 he can t speak speak english ,而双向的 LSTM的翻译是 he can t speak french french english .虽然结果都与实际结果有差距,但是也可以看出双向的 LSTM 翻译的更好,因为它翻译出来法语,英语。而单向的LSTM 只翻译出英语,这就是差距。
首先从 loss 图来看,最终的下降达到的值比没有加注意力机制的 GRU 要稍微低一点,差 0.1 左右,从实际的翻译效果看加了注意力机制的更好,比如句子今天天气怎么样?,没有加注意力机制的 GRU 翻译结果是 how s it weather today today?而加了注意力机制的 GRU 翻译结果为 what s the weather like today ?可以说是完全正确。再比如句子‘她喜欢吃草莓味的酸奶’普通 GRU 的翻译结果是 she likes to eat sushi,意思是她喜欢吃寿司,而加了注意力机制的 GRU 的翻译结果是 she likes to drink milk 意思是她喜欢喝牛奶。明显可以看出加了注意力机制的 GRU 翻译结果更接近真实的意思。
不管是从 loss 来看还是翻译结果来看,都比之前的好不少,这也是我能调出的最好翻译效果。比如句子汤姆不是一个好司机,翻译是 tom isn t a good swimmer .意思是汤姆不是一个好游泳员,已经很接近正确答案,而在之前的改进中这个翻译几乎不沾边,还有其他句子也有类似情况,最终的超参数调整的改进相对来说还是比较成功的,提升了句子翻译的效果。




























 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











