






深度学习课程学习记录,与吴恩达深度学习课程、《动手学深度学习》相结合。
AlexNet

Alexnet是由2012年ImageNet参赛者Hinton和他的学生设计的,Alexnet赢得了当年ImageNet图像分类竞赛的冠军,引发了神经网络的研究和使用热潮。
模型结构:
 改进之处:
改进之处:
- 使用ReLU激活函数代替sigmoid函数,用于卷积层和全连接层之后。
- 使用dropout,以一定的概率p随机关闭激活函数,有效减少过拟合。
- 使用双GPU策略,提高训练速度。
- 引入局部相应归一化操作LRN。
VGG-16

VGGNet是一种由Karen Simonyan和Andrew Zisserman在2014年提出的卷积神经网络,主要用于ImageNet图像识别任务。它使用了多个小尺寸的卷积核来替代原来的大尺寸卷积核,以提高模型的准确率。

改进之处:
- 通道数较多,网络加深。
- 各卷积层和池化层的超参数基本相同,整体结构呈现出规整的特点。
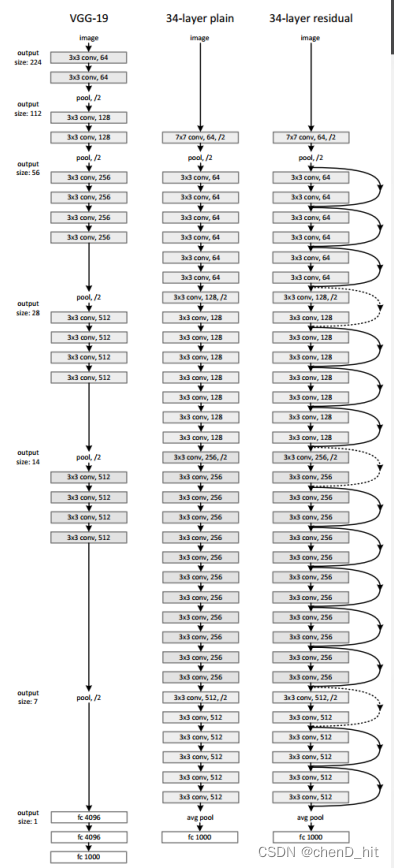
ResNet
ResNet采用了残差学习的思想,允许网络中存在跨层连接,解决了深度网络训练时出现的梯度消失和梯度爆炸问题,从而使得网络可以更深更复杂。
网络层数过多会产生梯度消失(每一层误差梯度是一个小于1的数,每进行一次反向传播会乘以一个小于1的数,导致最后梯度消失)或者梯度爆炸(与梯度消失相反);网络层数加深会产生退化现象。

卷积层主要有3×3的过滤器,并遵循两个简 单的设计规则:①对输出特征图的尺寸相同的 各层,都有相同数量的过滤器; ②如果特征 图的大小减半,那么过滤器的数量就增加一 倍,以保证每一层的时间复杂度相同。ResNet模型比VGG网络更少的过滤器和更低的 复杂性。ResNet具有34层的权重层,有36亿 FLOPs,只是VGG-19(19.6亿FLOPs)的18%。
常用数据集
Minist

MNIST 数据集主要由一些手 写数字的图片和相应的标签组成,图片一共有 10 类,分别对应从 0~9。原始的 MNIST 数据库一共包含下面 4 个文件:

MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样 本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。

CIFAR-10数据集
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每 个类有6000个图像。有50000个训练图像和10000个测试图像。数据集分为五个训练批次和一个测试批次,每个批次有10000 个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。

PASCAL VOC数据集
PASCAL的全称是Pattern Analysis, Statistical Modelling and Computational Learning,VOC的全称是Visual Object Classes,是目标分类(识别)、检测、分割最常用的数据集之一。PASCAL VOC数据集一共分为20类:person, bird, cat, cow, dog, horse, sheep, aeroplane, bicycle, boat, bus, car, motorbike, train, bottle, chair, dining table, potted plant, sofa, tv/monitor。

图像示例:

MS COCO数据集
PASCAL的全称是Microsoft Common Objects in Context,起源 于微软于2014年出资标注的Microsoft COCO数据集。数据集以scene understanding为目标,主要从复杂的日常场景中截取。包含目标分类(识别)、检测、分割、语义标注等数据集。提供的标注类别有80 类,有超过33 万张图片,其中20 万张有 标注,整个数据集中个体的数目超过150 万个。

ImageNet数据集
始于2009年,李飞飞与Google的合作: “ImageNet: A Large-Scale Hierarchical Image Database”。总图像数据:14,197,122,总类别数:21841, 带有标记框的图像数:1,034,908。
ISLVRC 2012子数据集
训练集:1,281,167张图片+标签,类别数:1,000 ,验证集:50,000张图片+标签,测试集:100,000张图片。
目标检测常见指标:
准确率(Accuracy):分类问题最常见的评价指标之一,它表示模型正确预测的样本数占总样本数的比例。
精度(Precision)和召回率(Recall):主要用于二分类问题。精度指的是预测为正类别的样本中,真正为正类别的样本所占的比例;召回率则指的是在所有真正为正类别的样本中,被正确预测为正类别的比例。
F1分数(F1-score):结合了精度和召回率,是综合指标。F1分数越高,代表模型对正负样本的分类效果越好。
均方误差(Mean Squared Error, MSE):用于回归问题的指标,衡量模型预测结果与真实值之间的均方误差。
平均绝对误差(Mean Absolute Error, MAE):同样也用于回归问题,衡量模型预测结果与真实值之间的平均绝对误差。
ROC曲线和AUC值:主要用于二分类问题的评价指标。ROC曲线是以假正率(False Positive Rate, FPR)为横轴,真正率(True Positive Rate, TPR)为纵轴的曲线,AUC值则是ROC曲线下的面积大小,AUC值越接近于1,代表模型分类效果越好。














 3856
3856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









