







1、131. 分割回文串
给你一个字符串
s,请你将s分割成一些子串,使每个子串都是 回文串 。返回s所有可能的分割方案。回文串 是正着读和反着读都一样的字符串
#错误写法
def partition(s):
def huiwen(temp):
"""判断是否是回文串"""
return temp == temp[::-1]
def backtracking(s_temp, result, temp_result):
if not s_temp:
# 已经走到最后一个字符
result.append(temp_result)
return
for i in range(1, len(s_temp) + 1): # start位置横向找第二刀
if huiwen(s_temp[:i]):
temp_result.append(s_temp[:i])
backtracking(s_temp[i:], result, temp_result)
result = []
backtracking(s, result, [])
return result
#第一种写法
def partition(s):
def huiwen(temp):
"""判断是否是回文串"""
return temp == temp[::-1]
def backtracking(s_temp, result, temp_result):
if not s_temp:
# 已经走到最后一个字符
result.append(temp_result[:])
return
for i in range(1, len(s_temp) + 1):
if huiwen(s_temp[:i]):
temp_result.append(s_temp[:i])
backtracking(s_temp[i:], result, temp_result)
temp_result.pop()
result = []
backtracking(s, result, [])
return result
#第二种写法
def partition(s):
def huiwen(temp):
"""判断是否是回文串"""
return temp == temp[::-1]
def backtracking(s_temp, result, temp_result):
if not s_temp:
# 已经走到最后一个字符
result.append(temp_result)
return
for i in range(1, len(s_temp) + 1):
if huiwen(s_temp[:i]):
backtracking(s_temp[i:], result, temp_result+[s_temp[:i]])
result = []
backtracking(s, result, [])
return result
#LeetCode上
class Solution:
def _huiwen(self, temp):
"""判断是否是回文串"""
return temp == temp[::-1]
def backtrack(self, s_temp, res, path):
if not s_temp:
res.append(path) # 类你面的path却没有这个问题
return
for i in range(1, len(s_temp) + 1): # 注意起始和结束位置
if self._huiwen(s_temp[:i]):
self.backtrack(s_temp[i:], res, path + [s_temp[:i]])
def partition(self, s):
res = []
self.backtrack(s, res, [])
return res
if __name__ == '__main__':
print(partition("cdd"))
f = Solution()
res = f.partition("cdd")
print(res)产生错误的原因:可变类型变量的引用,不具备深copy
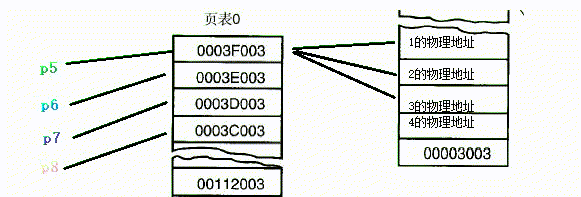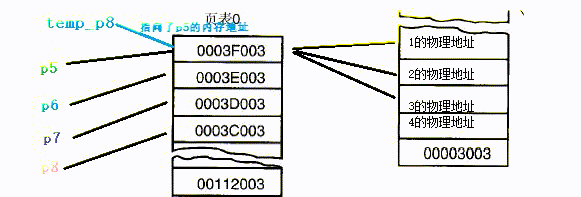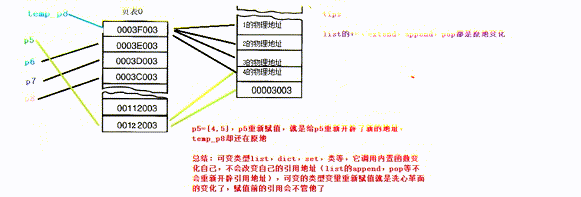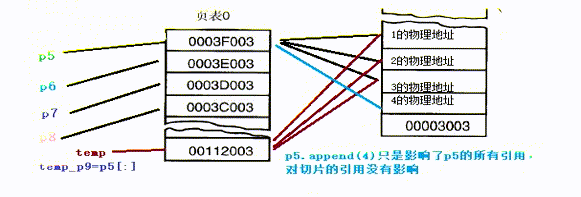
以下代码尝试了python中的常见类型引用的常见情况
p1 = "abc"
p2 = 123
p3 = 12.12
p4 = (1, 2)
p5 = [1, 2, 3]
p6 = {"w1": 1, "w2": 2}
p7 = {1, 2, 3, 4}
class A():
def __init__(self, name):
self.name = name
def __repr__(self):
return self.name
p8 = A("haha")
print("#" * 100)
print("(1)基础的不可变string,int, float, tuple的类型变量")
print("赋值string类型变量")
temp_p1 = p1
print(temp_p1, p1)
p1 = "abc1"
print(temp_p1, p1)
print("赋值int类型变量")
temp_p2 = p2
print(temp_p2, p2)
p2 = 1234
print(temp_p2, p2)
print("赋值float类型变量")
temp_p3 = p3
print(temp_p3, p3)
p3 = 1234.12
print(temp_p3, p3)
print("赋值tuple类型变量")
temp_p4 = p4
print(temp_p4, p4)
p4 += (3, 4)
print(temp_p4, p4)
print("list变量由基础类型组成")
temp_p5 = [p1, p2, p3, p4]
print(temp_p5, p1, p2, p3, p4)
p1, p2, p3, p4 = "1", 1, 1.1, (1, 1)
print(temp_p5, p1, p2, p3, p4)
print("dict变量由基础类型组成")
temp_p6 = {}
temp_p6 = {"w1": p1, "w2": p2, "w3": p3, "w4": p4}
print(temp_p6, p1, p2, p3, p4)
p1, p2, p3, p4 = "2", 2, 2.2, (2, 2)
print(temp_p6, p1, p2, p3, p4)
print("set变量由基础类型组成")
temp_p7 = {}
temp_p7 = {p1, p2, p3, p4}
print(temp_p7, p1, p2, p3, p4)
p1, p2, p3, p4 = "3", 3, 3.3, (3, 3)
print(temp_p7, p1, p2, p3, p4)
print("#" * 100)
print("(2)可变的list类型变量")
print("赋值=")
temp_p8 = p5
print(temp_p8, p5)
p5.append(4)
print(temp_p8, p5)
p5.extend([5])
print(temp_p8, p5)
p5 += [6]
print(temp_p8, p5)
p5 = [1, 2]
print(temp_p8, p5)
print("装入list")
temp_p9 = []
temp_p9.append(p5)
print(temp_p9, p5)
p5.append(3)
print(temp_p9, p5)
p5 += [4]
print(temp_p9, p5)
print("切片装入list")
temp_p10 = []
temp_p10.append(p5[:])
print(temp_p10, p5)
p5.append(5)
print(temp_p10, p5)
p5 += [6]
print(temp_p10, p5)
print("装入dict")
temp_p11 = {}
temp_p11["w1"] = p5
print(temp_p11, p5)
p5.pop()
print(temp_p11, p5)
p5 += [6]
print(temp_p11, p5)
print("切片装入dict")
temp_p12 = {}
temp_p12["w1"] = p5[:]
print(temp_p12, p5)
p5.pop()
print(temp_p12, p5)
p5 += [6]
print(temp_p12, p5)
print("#" * 100)
print("(3)可变的dict类型变量")
print("赋值=")
temp_p13 = p6
print(temp_p13, p6)
p6["w3"] = 3
print(temp_p13, p6)
p6 = {"f": "f"}
print(temp_p13, p6)
print("装入list")
temp_p14 = []
temp_p14.append(p6)
print(temp_p14, p6)
p6["w4"] = 4
print(temp_p14, p6)
print("装入dict")
p6 = {"w1": 1, "w2": 2}
temp_p15 = {}
temp_p15["w1"] = p6
print(temp_p15, p6)
p6.pop("w1")
print(temp_p15, p6)
print("#" * 100)
print("(4)可变的set类型变量")
print("赋值=")
temp_p16 = p7
print(temp_p16, p7)
p7.pop()
print(temp_p16, p7)
p7 = {1, 2}
print(temp_p16, p7)
print("装入list")
temp_p17 = []
temp_p17.append(p7)
print(temp_p17, p7)
p7.add(1)
print(temp_p17, p7)
print("装入dict")
temp_p18 = {}
temp_p18["w1"] = p7
print(temp_p18, p7)
p7.pop()
print(temp_p18, p7)
print("#" * 100)
print("(5)可变的自定义类变量")
print("赋值=")
temp_p19 = p8
print(temp_p19, p8)
p8.name = "123"
print(temp_p19, p8)
print("装入list")
temp_p20 = []
temp_p20.append(p8)
print(temp_p20, p8)
p8.name = "temp_p20"
print(temp_p20, p8)
print("装入dict")
temp_p21 = {}
temp_p21["w1"] = p8
print(temp_p21, p8)
p8.name = "temp_p21"
print(temp_p21, p8)
2、139. 单词拆分
def wordBreak(s, wordDict):
"""回溯方法+记忆化"""
def _backtracking(start_index, memory):
if start_index >= len(s):
return True
if memory[start_index] != -1:
return memory[start_index]
for i in range(start_index + 1, len(s) + 1):
if s[start_index:i] in wordDict and _backtracking(i, memory):
memory[start_index] = 1
return True
memory[start_index] = 0
return False
memory = [-1] * len(s) # 记录每个位置作为起始位置的计算结果,减少重复计算的次数
return _backtracking(0, memory)3、雀魂启动
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 32M,其他语言64M
小包最近迷上了一款叫做雀魂的麻将游戏,但是这个游戏规则太复杂,小包玩了几个月了还是输多赢少。
于是生气的小包根据游戏简化了一下规则发明了一种新的麻将,只留下一种花色,并且去除了一些特殊和牌方式(例如七对子等),具体的规则如下:
- 总共有36张牌,每张牌是1~9。每个数字4张牌。
- 你手里有其中的14张牌,如果这14张牌满足如下条件,即算作和牌
- 14张牌中有2张相同数字的牌,称为雀头。
- 除去上述2张牌,剩下12张牌可以组成4个顺子或刻子。顺子的意思是递增的连续3个数字牌(例如234,567等),刻子的意思是相同数字的3个数字牌(例如111,777)
例如:
1 1 1 2 2 2 6 6 6 7 7 7 9 9 可以组成1,2,6,7的4个刻子和9的雀头,可以和牌
1 1 1 1 2 2 3 3 5 6 7 7 8 9 用1做雀头,组123,123,567,789的四个顺子,可以和牌
1 1 1 2 2 2 3 3 3 5 6 7 7 9 无论用1 2 3 7哪个做雀头,都无法组成和牌的条件。
现在,小包从36张牌中抽取了13张牌,他想知道在剩下的23张牌中,再取一张牌,取到哪几种数字牌可以和牌。
输入描述:
输入只有一行,包含13个数字,用空格分隔,每个数字在1~9之间,数据保证同种数字最多出现4次。输出描述:
输出同样是一行,包含1个或以上的数字。代表他再取到哪些牌可以和牌。若满足条件的有多种牌,请按从小到大的顺序输出。若没有满足条件的牌,请输出一个数字0输入例子1:
1 1 1 2 2 2 5 5 5 6 6 6 9输出例子1:
9例子说明1:
可以组成1,2,6,7的4个刻子和9的雀头输入例子2:
1 1 1 1 2 2 3 3 5 6 7 8 9输出例子2:
4 7例子说明2:
用1做雀头,组123,123,567或456,789的四个顺子输入例子3:
1 1 1 2 2 2 3 3 3 5 7 7 9输出例子3:
0例子说明3:
来任何牌都无法和牌测试一个雀头场景:1 1 2 2 4 4 5 5 7 7 8 8 9
def quehun():
def _is_hu(param):
"""判断是否能胡牌"""
if len(param) == 0:
return True
count_1 = param.count(param[0])
# 处理顺序很重要,优先处理了雀头,在处理刻子,最后处理顺子(雀头必须有且有一个,优先处理顺子会remove很多一样的牌面)
# 长度非3的倍数说明还没有找到雀头,处理雀头
if len(param) % 3 != 0 and count_1 >= 2 and _is_hu(param[2:]):
return True
# 处理时刻子的情况
if count_1 >= 3 and _is_hu(param[3:]):
return True
# 处理是顺子的情况
if param[0] + 1 in param and param[0]+2 in param:
param.remove(param[0] + 1)
param.remove(param[0]+2)
param.remove(param[0])
if _is_hu(param):
return True
return False
nums = list(map(int, input().strip().split()))
flag = 0 # 标志是否一次也没有胡牌过
# 可以选择的范围就是[1,9]的牌面
for i in range(1, 10):
# 排序方便_is_hu方法中使用切片
temp = sorted(nums + [i])
# 排除13张牌中有一个牌面有4张的场景
if temp.count(i) > 4:
continue
# 如果胡牌,就是一个需要找到的结果
if _is_hu(temp):
flag = 1
print(i, end=" ")
if not flag:
print(0)














 4420
4420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









